Google I/O是由Google举行的网络开发者年会,评论的焦点是用Google和敞开网络技能开发网络运用。这个年会自2008年开端举行,到本年现已是举行的第9届了。
在本年的年会上,Google首要发布了以下8种产品:智能帮手Google Assistant,与Amazon Echo竞赛的无线扬声器和语音指令设备Google Home,音讯运用Allo,视频呼叫运用Duo,VR渠道Daydream,独立运用程序的支撑Android Wear 2.0,答应不装置而运用运用的Android Instant Apps,以及答应在Chromebook上运用Android运用Google Play on Chrome OS。
而这8中产品首要都会集在了软件范畴。

(Google I/O 2016现场图via:webpronews.com)
在Google I/O 2016的主题讲演进入结尾时,Google的CEO皮采提到了一项他们这段时刻在AI和机器学习上获得的效果,一款叫做Tensor Processing Unit(张量处理单元)的处理器,简称TPU。在大会上皮采仅仅介绍了这款TPU的一些功用指标,并在随后的博客中发布了一些运用场景,并没有对这款处理器的架构以及内部的运作机制进行具体论述,所以咱们或许需求从一些常见的处理器的结构动身,企图猜想与探求下这款用于机器学习的专属芯片究竟有着怎样的一个面孔。

(Tensor processing unit实物图 via:cio-today.com)
首要咱们先来看看咱们最了解的中央处理器(Central Processing Unit),简称CPU。它是一种超大规划的集成芯片,而且是一种通用芯片,也便是说,它能够用它来做许多品种的作业。咱们日常运用的电脑运用的处理器基本上都是CPU,看个电影、听个音乐、跑个代码,都没啥问题。
| 咱们来看看CPU的结构
CPU首要包括运算器(ALU,Arithmetic and Logic Unit)和操控器(CU,Control Unit)两大部件。此外,还包括若干个存放器和高速缓冲存储器及完结它们之间联络的数据、操控及状况的总线。从上面的叙说咱们能够看出,CPU首要包括运算逻辑器材、存放器部件以及操控部件等。

(CPU结构简化图 via:blog.csdn.net)
从字面上咱们也很好了解,运算逻辑器材首要履行算术运算、移位等操作,以及地址运算和转化;存放器材首要用于保存运算中发生的数据以及指令等;操控器材则是担任对指令译码,而且宣布为完结每条指令所要履行的各个操作的操控信号。
咱们能够运用下面这张图来阐明一条指令在CPU中履行的大致进程:
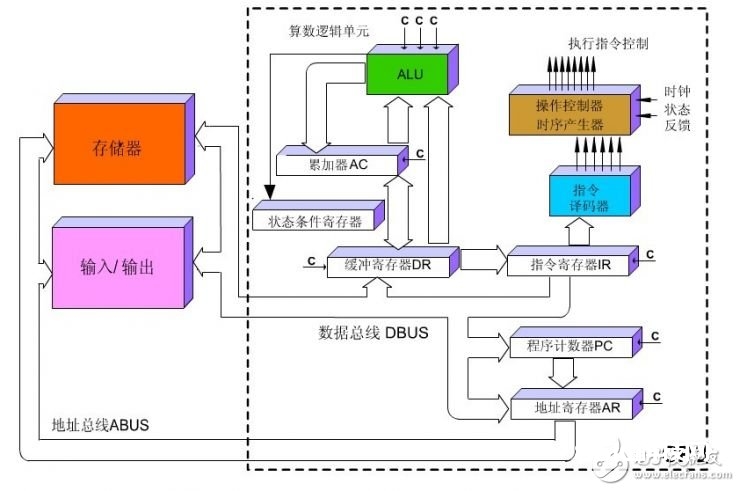
(CPU履行指令图 via:blog.csdn.net)
CPU从程序计数器取到指令,经过指令总线将指令送至译码器,将转译后的指令交给时序发生器与操作操控器,然后运算器对数据进行核算,经过数据总线将数据存至数据缓存存放器。
咱们从CPU的结构以及履行进程能够看出,CPU遵从的是冯诺依曼架构,冯诺依曼的中心便是:存储程序,次序履行。
从上面的描绘咱们能够看出,CPU就像一个有条有理的管家,咱们叮咛的作业总是一步一步来做。可是跟着摩尔定律的推动以及人们对更大规划与更快处理速度的需求的添加,CPU如同履行起使命来就不那么令人满意了。所以人们就想,咱们可不能够把好多个处理器放在同一块芯片上,让他们一起来干事,这样功率是不是就会高许多,这是GPU就诞生了。
| GPU诞生了
GPU全称为Graphics Processing Unit,中文为图形处理器,就如它的姓名相同,GPU开端是用在个人电脑、作业站、游戏机和一些移动设备(如平板电脑、智能手机等)上运转绘图运算作业的微处理器。由于关于处理图画数据来说,图画上的每一个像素点都有被处理的需求,这是一个相当大的数据,所以关于运算加快的需求图画处理范畴最为激烈,GPU也就应运而生。
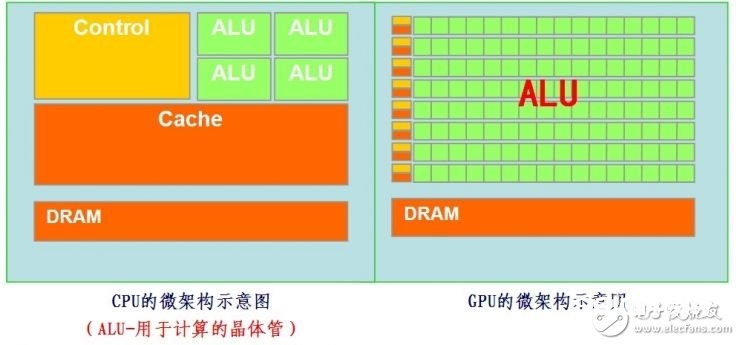
(CPU与GPU结构比照示意图 via:baike.baidu.com)
经过CPU与GPU结构上的比照咱们能够看出,CPU功用模块许多,能习惯杂乱运算环境;GPU构成则相对简略,大部分晶体管首要用于构建操控电路(比方分支猜测等)和Cache,只要少部分的晶体管来完结实践的运算作业。而GPU的操控相对简略,且对Cache的需求小,所以大部分晶体管能够组成各类专用电路、多条流水线,使得GPU的核算速度有了突破性的腾跃,具有了更强壮的处理浮点运算的才能。其时最尖端的CPU只要4核或许6核,模拟出8个或许12个处理线程来进行运算,可是一般等级的GPU就包括了成百上千个处理单元,高端的乃至更多,这关于多媒体核算中许多的重复处理进程有着天然生成的优势。
这就比如在画一幅画的时分CPU是用一支笔一笔一笔的来画,而GPU则是多支笔对不同的方位一起进行描绘,那天然功率便是日新月异的。
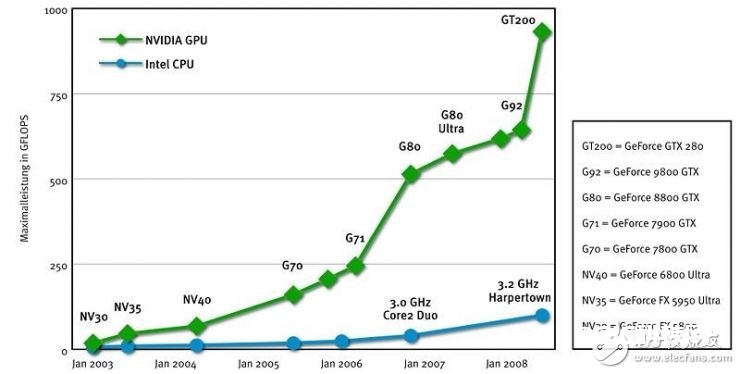
(英特尔CPU与英伟达GPU浮点运算功用比照图 via:blog.sina.com.cn)
尽管GPU是为了图画处理而生的,可是咱们经过前面的介绍能够发现,它在结构上并没有专门为图画服务的部件,仅仅对CPU的结构进行了优化与调整,所以现在GPU不只能够在图画处理范畴大显神通,它还被用来科学核算、暗码破解、数值剖析,海量数据处理(排序,Map-Reduce等),金融剖析等需求大规划并行核算的范畴。所以GPU也能够以为是一种较通用的芯片。
| FPGA应运而生
跟着人们的核算需求越来越专业化,人们期望有芯片能够愈加契合咱们的专业需求,可是考虑到硬件产品一旦成型便不行再更改这个特色,人们便开端想,咱们可不能够出产一种芯片,让它硬件可编程。也便是说——
这一刻咱们需求一个比较合适对图画进行处理的硬件体系,下一刻咱们需求一个对科学核算比较合适的硬件体系,可是咱们又不期望焊两块板子,这个时分FPGA便应运而生。
FPGA是Field Programmable Gate Array的简称,中文全称为场效可编程逻辑闸阵列,它是作为专用集成电路范畴中的一种半定制电路而呈现的,既处理了全定制电路的缺乏,又克服了原有可编程逻辑器材门电路数有限的缺陷。
FPGA运用硬件描绘言语(Verilog或VHDL)描绘逻辑电路,能够运用逻辑归纳和布局、布线工具软件,快速地烧录至FPGA上进行测验。人们能够根据需求,经过可修改的衔接,把FPGA内部的逻辑块衔接起来。这就如同一个电路实验板被放在了一个芯片里。一个出厂后的制品FPGA的逻辑块和衔接能够依照规划者的需求而改动,所以FPGA能够完结所需求的逻辑功用。

(FPGA结构简图 via:dps-az.cz/vyvoj)
FPGA这种硬件可编程的特色使得其一经推出就受到了很大的欢迎,许多ASIC(专用集成电路)就被FPGA所替代。这儿需求阐明一下ASIC是什么。ASIC是指依产品需求不同而定制化的特别标准集成电路,由特定运用者要求和特定电子体系的需求而规划、制作。这儿之所以特别阐明是由于咱们下面介绍的TPU也算是一种ASIC。
FPGA与ASIC芯片各有缺陷,FPGA一般来说比ASIC的速度要慢,而且无法完结更杂乱的规划,而且会消耗更多的电能;而ASIC的出产成本很高,假如出货量较小,则选用ASIC在经济上不太实惠。可是假如某一种需求开端增大之后, AS%&&&&&%的出货量开端添加,那么某一种专用%&&&&&%的诞生也便是一种前史趋势了,我以为这也是Google出产Tensor processing unit的一个重要动身点。至此,TPU便登上前史舞台。
跟着机器学习算法越来越多的运用在各个范畴并表现出优胜的功用,例如街景、邮件智能回复、声响查找等,关于机器学习算法硬件上的支撑也越来越成为一种需求。现在许多的机器学习以及图画处理算法大部分都跑在GPU与FPGA上面,可是经过上面的叙述咱们能够知道,这两种芯片都仍是一种通用性芯片,所以在效能与功耗上仍是不能更严密的适配机器学习算法,而且Google一向深信巨大的软件将在巨大的硬件的协助下愈加大放异彩,所以Google便在想,咱们可不能够做出一款专用机机器学习算法的专用芯片,TPU便诞生了。

(TPU板卡图 via:cloudplatform.googleblog.com)
| Google想做一款专用机机器学习算法的专用芯片——TPU
从姓名上咱们能够看出,TPU的创意来源于Google开源深度学习结构TensorFlow,所以现在TPU仍是只在Google内部运用的一种芯片。
Google其实现已在它内部的数据中心跑TPU跑了一年多了,功用指标杠杠的,大约将硬件功用提升了7年的开展时刻,约为摩尔定律的3代。关于功用来说,约束处理器速度的最大两个要素是发热与逻辑门的推迟,其间发热是约束速度最首要的要素。现在的处理器大部分运用的是CMOS技能,每一个时钟周期都会发生能量耗散,所以速度越快,热量就越大。下面是一张CPU时钟频率与能量消耗的联系,咱们能够看到,增加是指数性的。

(CPU时钟频率与功耗联系图 via:electronics.stackexchange.com)
从TPU的外观图咱们能够看出,其间间杰出一块很大的金属片,这便是为了能够很好地对TPU高速运算是发生许多的热进行耗散。
TPU的高功用还来源于关于低运算精度的忍受,也便是说每一步操作TPU将会需求更少的晶体管。在晶体管总容量不变的情况下,咱们就能够单位时刻在这些晶体管上运转更多的操作,这样咱们就能够以更快的速度经过运用愈加杂乱与强壮的机器学习算法得到愈加智能的成果。咱们在TPU的板子上看到了插条,所以现在Google运用TPU的方法是将载有TPU的板子插在数据中心机柜的硬盘驱动器插槽里来运用。
而且我觉得TPU的高功用还来源于它数据的本地化。关于GPU,从存储器中取指令与数据将消耗许多的时刻,可是机器学习大部分时刻并不需求从大局缓存中取数据,所以在结构上规划的愈加本地化也加快了TPU的运转速度。

(AlphaGo对战李世乭竞赛中运用的载有TPU的服务器机架,不知道为什么旁边面贴的围棋图有种萌感。via:googleblog.com)
在Google数据中心的这一年来,TPU其实现已干了许多作业了,例如机器学习人工智能体系RankBrain,它是用来协助Google处理查找成果并为用户供给愈加相关查找成果的;还有街景Street View,用来进步地图与导航的准确性的;当然还有下围棋的核算机程序AlphaGo,其实这一点上也有个很风趣的当地,咱们在描绘AlphaGo的那篇Nature文章中看到,AlphaGo仅仅跑在CPU+GPUs上,文章中说AlphaGo的完好版别运用了40个查找线程,跑在48块CPU和8块GPU上,AlphaGo的分布式版别则运用了更多的机器,40个查找线程跑在1202个CPU和176块GPU上。这个装备是和樊麾竞赛时运用的,所以其时李世乭看到AlphaGo与樊麾的对弈进程后对人机大战很有决心。可是就在短短的几个月时刻,Google就把运转AlphaGo的硬件渠道换成了TPU,然后对战的形势就艰难了起来。
那么除了TPU能够更好更快地运转机器学习算法,Google发布它还有什么其他意图。我觉得说的玄幻一些,Google或许鄙人一盘大棋。
Google说他们的方针是在工业界的机器学习方面起到前锋带头作用,并使得这种立异的力气惠及每一位用户,而且让用户更好地运用TensorFlow 和 Cloud Machine Learning。其实就像微软为它的HoloLens增强实际头显装备了全息处理单元(holographic processing unit,HPU),像TPU这样的专业硬件仅仅它远大征途的一小步,不只仅是想让自己在公共云范畴超越商场老迈Amazon Web Services (AWS)。跟着时刻的推移,Google会放出更多的机器学习API,现在Google现已推出了云机器学习渠道服务和视觉API,咱们能够信任,做机器学习技能与商场的leader才是Google更大的方针。