数字视频缩小和扩大(简称缩放)是视频处理的一个重要分支,是根据对数字视频每帧图画的处理来完结的。常见的缩放算法有最近邻域法、双线性插值法、抛物线插值法、双三次插值法和牛顿插值法等根据多项式的插值算法[1],较简单在FPGA硬件上完结;也有B样条插值法、根据小波插值和有理插值等比较复杂的算法,难以在FPGA上完结。
近年来跟着液晶平板显现器材的广泛应用,关于定标器的研讨越来越多且研讨成果也很丰厚。但定标器的缩放份额有限,一般在0.5~4之间,在这个范围内选用2阶或3阶多点插值算法,图画的边际和细节能够较好保存。可是选用定点插值法,当文字缩小份额较大时,会丢掉较多的细节,呈现字体笔画开裂或许锯齿现象。而选用低阶算法(例如多点均值插值),参加运算的点较多,能够有用进步文字的显现质量。
1 体系架构
体系架构如图1所示,先对输入视频的分辨率进行检测,将检测值送至MCU,MCU用其确认缩放步长;然后对视频进行缩小操作。假如要对信号进行扩大,则绕过该形式;接着将视频数据送至IFIFO缓存,由裁定器和DDR2操控器完结4个通道数据的帧率改换后,视频数据送至OFIFO模块;接着数据被送至扩大模块,完结扩大操作。假如要对视频信号进行缩小,则绕过该形式;最终将完结处理的RGB视频信号输出。整个缩放进程所需求的缩放步长、通道挑选等装备信号悉数由MCU经过本地总线装备FPGA。

其间,f(x,y)为缩小图画某点的像素值,f(xi,yi)为图画子块中各点的像素值。
完结成果如图5所示,较好地保证了文字的正常显现。
4 帧率改换
4.1 输入缓存 IFIFO
每一路IFIFO都需求在FIFO中数据量大于1/2 FIFO深度时向裁定模块发送占用DDR2总线的恳求信号REQ,应对信号AGREE有用时,向DDR2操控器发送数据。当完结一定量的读出数据时,往裁定模块发送一个发送完毕信号END,裁定模块接收到END信号后将DDR2总线操控权回收,IFIFO等候下一次应对。
4.2 输出缓存OFIFO
其完结原理与IFIFO相似,仅仅该模块的输入端作业在DDR2作业时钟域,输出模块作业在帧率改换后的视频图画的像素时钟域。
4.3 裁定
共有4路输入和4路输出占用DDR2带宽,需求区分时刻片来保证各个通道能够顺利地显现,优先级依次为第1、2、3、4通道读,第1、2、3、4通道写。本模块选用状况机操控,状况机在上述8个状况中循环跳转,然后跳回IDEL状况,开端下一轮循环。
裁定模块的另一个使命便是读写DDR2地址的生成。将DDR2的存储空间区分为4个部分,每个部分存储一路视频信号,每路视频信号存储3帧。一起读DDR2时,指令设置为读操作;写DDR2时,指令设置为写操作。
现就一路视频完结帧率改换评论如下:创立3个指针别离指向3帧数据的DDR2空间基地址,体系启动时,读指针rd_pointer、当时写指针current_wr_pointer和之前写指针pre_wr_pointer别离依照图6所示的状况图在3个基地址之间跳转。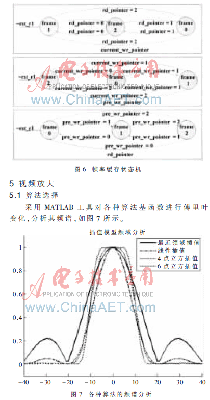
最近邻域插值法存在很强的波瓣,频率呼应较差。当图画中包括像素值有改变的纤细结构时,最近邻插值会在图画中发生人为的痕迹,形成图画含糊或发生人为噪声点。
线性插值法频谱的旁瓣远小于主瓣,带阻特性较好。但通带内高频成分衰减过快,会使得插值后的图画变含糊。
四点立方插值通带内高频成分衰减显着变慢,且旁瓣不超越1%,具有较好的高频呼应特性,缩放后的图画能够坚持更多细节。
六点立方插值算法的频率呼应特性愈加优胜,通带内高频成分衰减更慢且旁瓣更低。
四点立方插值较好地坚持了图画的细节,完结难度和占用逻辑资源适中。六点立方插值尽管完结作用更好,可是占用的逻辑资源较多。故本规划选用四点立方插值算法完结视频的扩大操作。
5.2 插值基函数
图画插值缩放具有二维可分解的特色,能够将二维图画的插值分解为别离沿x和y方向的一维信号插值[3]。一维方向上,运用插值点的四个接近像素点进行三次插值, Keys将sinc离散函数进行泰勒级数打开后,使三次分段多项式和原始信号的泰勒级数打开式尽可能多项符合,以此推导出插值基函数表达式[4]。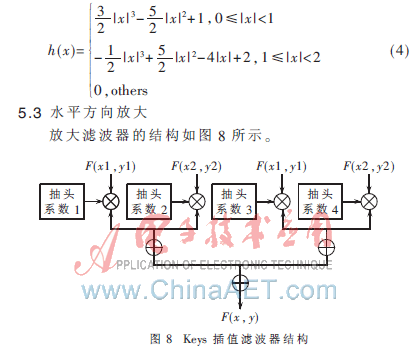
5.3.1 抽头系数的发生
将插值的系数存在ROM中,这样尽管运用三次方插值,可是不用在FPGA中完结三次方的运算,进步了运算速度。例如原图画一行有3个像素,要求插值后的图画一行有8个像素,则新图画一行的第5个点在原图画中映射的坐标为[(5-1)×2/7]+1=15/7=2+1/7≈
′b0010.1001,整数2为其原图画中左面接近的像素点坐标为2,1/7表明其与坐标为2的原图画像素的间隔为1/7。此刻将小数部分1001作为地址读出存储在该地址的抽头系数,将其送给卷积器。
5.3.2 插值参考点操控
扩大时,对缩放步长进行累加,当小数向个位数进位时,开端读取一个新的数据。例如核算插值后图画某个点时,选用原图画的x4、x5、x6、x7作为插值参考点,则当步长累加器有进位时,读取下一个像素值x8,一起将x5、x6、x7移到x4、x5、x6的寄存器方位,而x8则存入之前x7的方位,这样就能够完结从原图画向方针图画的地址映射,防止从方针图画到原图画地址映射进程呈现的乘法运算。
5.4 行缓存
行缓冲存储器的主体为若干个存储容量相同的双口随机存储器(DRAM),每个DRAM存储一行的有用像素数据。
为了保证行缓存不溢出,拓荒6个行缓存器,存储时按次第1-2-3-4-5-6-1循环寄存,读取时按循环次第读取。
5.5 笔直方向扩大
笔直方向扩大滤波器架构和水平方向相同,仅仅插值参考点来自于不同的行缓存空间里相同地址的数据。
本文选用Xilinx公司的Virtex-5系列XC5VLX50T-1FFG1136C类型的FPGA完结,可用用户IO管脚480个,满意4路视频信号输入、4路视频信号输出和一路16 bit本地总线需求。内部可用Slice 7 200个, Block RAM Blocks最大为2 160 KB,满意4路视频信号每路缓存6行数据需求。输入DVI视频信号用Silicon Image公司的SiI 1161解码成并行RGB数据送至FPGA,输出的并行RGB视频信号用SiI 1160编码成DVI视频信号输出显现。试验成果表明,在4个通道输入均为352×288(CIF格局)分辨率、均扩大为1 920×1 080输出显现时,无方块效应,输出安稳顺利;在4个通道输入均为1 920×1 080分辨率、均缩小为352×288输出显现时,画面质量杰出,且文字笔画圆润,无笔画开裂或许含糊不清的现象。