高校和私企正在运用分布式渠道,而不是装置速度更快、耗电更大的超级核算机来处理日益杂乱的科学算法,针对SETI@home 这样的项目,他们则运用数以千计的个人核算机来核算它们的数据。[1,2] 当时的分布式核算网络一般用CPU 或 GPU 来核算项目数据。
FPGA 也正被像 COPACOBANA这样的项目所选用,该项目运用 120个赛灵思 FPGA 经过暴力处理来破解DES 加密文件。[3] 不过在这个事例中,FPGA 都被会集安置在一个当地,这种计划不太合适那些预算严重的大学或企业。现在并未将 FPGA 当作分布式核算东西,这是由于它们的运用需求凭借 PC,才能用新的比特流不断地重新装备整个 FPGA。可是现在有了赛灵思部分重装备技能,为分布式核算网络规划依据 FPGA 的客户端彻底可行。
咱们汉堡运用技能大学的研讨小组为这样的客户端创建了一个原型,并将其完结在单个 FPGA 上。咱们的规划由静态和动态两大部分组成。其间静态部分在 FPGA 启动时加载,与此同时用静态部分完结的处理器从网络服务器下载动态部分。动态部分属部分重装备区域,供给同享的 FPGA资源。[4] 选用这种装备,FPGA 能够坐落世界上的任何当地,用较低的预算就能够为核算项目供给强壮的核算才能。
分布式 SOC 网络
由于具有信号并行处理才能,FPGA能够运用比微处理器慢 8 倍的时钟,低 8 倍的功耗完结比其快三倍的数据吞吐量。[5] 为运用该强壮的核算才能完结高数据输入速率,规划人员一般将算法完结为流水线,比方 DES 加密。[3] 咱们开发分布式 SoC 网络 (DSN)原型的意图是加速算法的速度和运用分布式 FPGA 资源处理大型数据集。咱们的网络规划选用“客户端- 署理-服务器”架构,故咱们能够将一切注册的片上体系 (SoC) 客户端分配给每一个网络参加方的核算项目(如图 1所示)。这在将每一个 SoC 客户端衔接到仅有的项意图“客户端- 服务器”架构中是无法完结的。
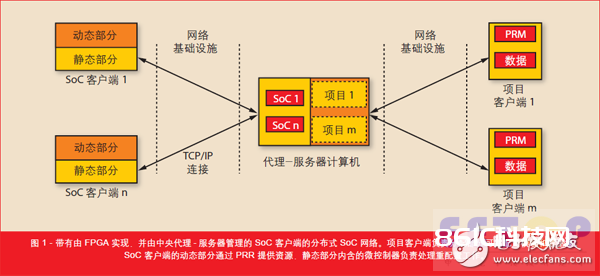
别的,咱们挑选“署理- 服务器”架构能够将每个 FPGA 的 TCP/IP 衔接数量削减到一个。DSN FPGA 担任运算运用专用数据集的算法,而“署理-服务器”则担任办理 SoC 客户端和项目客户端。署理调度衔接的 SoC 客户端,让每个项目在相同的时刻简直具有相同的核算才能,或许在 SoC 的数量少于核算恳求的项目时分时复用soc客户端。
项目客户端供给部分重装备模块(PRM) 和鼓励输入数据集。在衔接到“署理- 服务器”之后,项目客户端将PRM 比特文件发送给服务器,然后由服务器将它们分配给带有闲暇的部分可重装备区域 (PRR) 的 SoC 客户端。SoC 客户端的静态部分是一个依据MicroBlazeTM 的微操控器,用接纳到的 PRM 动态重新装备 PRR。接下来,项目客户端开端经过“署理- 服务器”发送数据集并从 SoC 客户端接纳核算的成果。依据项目客户端的需求,举例来说,它能够比较不同的核算成果,或依据核算意图评价核算成果。
MicroBlaze 处理器担任运转客户端软件,客户端软件办理部分重装备以及比特流和数据交换。
SOC 客户端
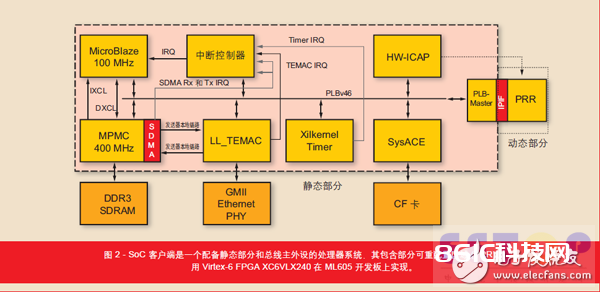
咱们为随 ML605 评价板配套供给的赛灵思 Virtex®-6 FPGA(XC6VLX240T)开发了 SoC 客户端。MicroBlazeTM 处理器担任运转客户端软件,客户端软件担任办理部分可重装备以及比特流和数据交换(如图 2 所示)。用户逻辑封装PRR 的处理器本地总线 (PLB) 外设用以衔接静态部分和动态部分。在动态部分驻留的是接纳到的 PRM 供给的加速器 IP 核运用的 FPGA 同享资源。为存储接纳到的数据和核算完结的数据,咱们挑选了 DDR3 存储器而非CompactFlash,由于 DDR 存储器有更高的数据吞吐量和无限制的写入拜访次数。PRM 存储在专用数据段内,以操控其巨细,防止与其它数据集发生冲突。该数据段巨细为 10 MB,足以存储完好的 FPGA 装备。因而每一个PRM 都应该与这个数据段的巨细匹配。
咱们还为接纳及成果数据集创建了不同的数据段。这些数据段的巨细有 50 MB,能够为比方图画或加密文本文件等供给满足的寻址空间。办理这些数据段首要依托 10 个办理结构。该办理结构包含每个数据集对的开始/ 结尾地址,以及指示成果数据集的标志。