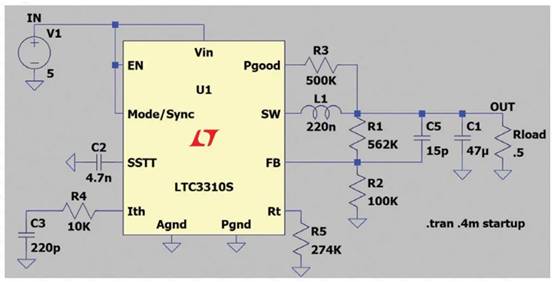
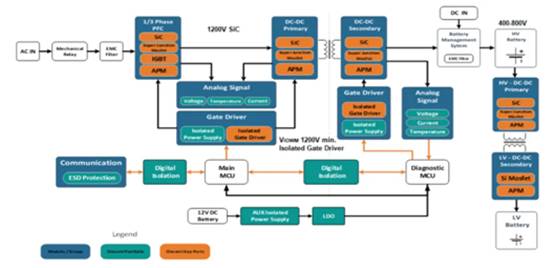
阅读了《单片机与嵌入式体系运用》2005年第10期杂志《经验交流》栏目的一篇文章《Keil C51对同一端口的接连读取办法》(原文)后,笔者以为该文并未就此问题进行深化精确的剖析文章中说到的两种处理办法并不直接和简略。笔者以为这并非是Keil C51中不能处理对一个端口进行接连读写的问题,而是对Kei1 C51的运用不行了解和规划不行详尽的问题,因而特编撰本文。
本文中对原文说到的问题,提出了三种不同于原文的处理办法。每种办法都比原文中说到的办法更直接和简略,规划也更标准。(无意批判,请原文作者见谅)
1问题回忆和剖析
原文中说到:在实践工作中遇到对同一端口重复接连读取,Keil C51编译并未到达预期的成果。原文作者对C编译出来的汇编程序进行剖析发现,对同一端口的第2次读取句子并未被编译。但惋惜原文作者并未剖析没有被编译的原因,而是匆忙地选用一些不太标准的办法实验出了两种处理办法。
对此问题,翻阅Keil C51的手册很简略发现:KeilC51的编译器有一个优化设置,不同的优化设置,会发生不同的编译成果。一般状况缺省编译优化设置被设定为8级优化,实践最高可设定为9级优化:
1. Dead code elimination。
2.Data overlaying。
3.Peephole optimization。
4.Register variables。
5.Common subexpression elimination。
6.Loop rotation。
7.Extended Index Access Optimizing。
8.Reuse Common Entry Code。
9.Common Block Subroutines。
而以上的问题,正是由于Keil C51编译优化发生的。由于在原文程序中将外设地址直接按如下界说:
unsigned char xdata MAX197 _at_ 0x8000
选用_at_将变量MAX197界说到外部扩展RAM指定地址0x8000。因而,Keil C51优化编译天经地义以为重复读第2次是没有用的,直接用第一次读取的成果就能够了,因而编译器越过了第二条读取句子。至此,问题就一望而知了。
2处理办法
由以上剖析很简略就能提出很好的处理办法。
2.1最简略最直接的办法
程序一点都不必修正,将Keil C51的编译优化挑选设置为0(不优化)就能够了。挑选project窗口的Target,然后翻开“Options for Target”设置对话框,挑选“C51”选项卡,将“Code Optimiztaion”中的“Level”挑选为“0:Costant folding”。再次编译后,我们会发现编译成果为:
CLR MAXHBEN
MOV DPTR,#MAX197
MOVX A,@DPTR
MOV R7,A
MOV down8,R7
SETB MAXHBEN
MOV DPTR,#MAX197
MOVX A,@DPTR
MOV R7,A
MOV up4,R7
两次读取操作都被编译出来了。
2.2最好的办法
告知Keil C51,这个地址不是一般的扩展RAM,而是衔接的设备,具有“蒸发”特性,每次读取都是有意义的。能够修正变量界说,添加“volatile”关键字阐明其特征:
unsigned char volatile xdata MAX197 _at_ 0x8000;
也能够在程序中包括体系头文件;“#include”,然后在程序中修正变量,界说为直接地址:
#define MAX197 XBYTE[0x8000]
这样,Keil C51的设置依然能够保存高档优化,且编译成果中,相同两次读取并不会被优化越过。
2 3硬件处理办法
原文中将MAX197的数据直接衔接到数据总线,而对地址总线并未运用,选用一根端口线挑选操作凹凸字节。很简略的修正办法便是运用一根地址线挑选操作凹凸字节即可。比方:将P2.0(A8)衔接到本来P1.0衔接的HBEN脚(MAX197的5脚).在程序中别离界说凹凸字节的操作地址:
unsigned char volatile xdata MAX197_L _at_ 0x8000;
unsigned char volatile xdata MAX197_H _at_ 0x8100;
将本来的程序:
MAXHBEN =0;
down8=MAX197;//读取低8位
MAXHBEN =1;
up4=MAX197;//读取高4位
改为以下两句即可
down8= MAX197_L;//读取低8位
up4=MAX197_H;//读取高4位
3小结
Keil C51经过长时刻检测和改善以及很多开发人员的实践运用,现已克服了绝大大都的问题,而且其编译功率也十分高。关于一般的运用.很难再发现什么问题。笔者从前大略研讨过一下Keil C51优化编洋的成果.十分敬服Keil C51规划者的才智,一些C程序编译发生的汇编代码.乃至比一般程序员直接用汇编编写的代码还要优异和简练经过研读Kell C51编译发生的汇编代码.对进步汇编语言编写程序的水平都是很有协助的。
由本文中的问题能够看出:在规划中遇到问题时.必定不要被表面现象遮盖,不要急于处理,应该仔细剖析,找出问题的原因.这样才干从根本上完全处理问题。
|
附表:Keil C51中的优化等级及优化效果
|
|
等级
|
阐明
|
|
0
|
常数兼并:编译器预先核算成果,尽或许用常数替代表达式。包括运转地址核算。
优化简略拜访:编译器优化拜访8051体系的内部数据和位地址。
跳转优化:编译器总是扩展跳转到最终目标,多级跳转指令被删去。
|
|
1
|
死代码删去:没用的代码段被删去。
回绝跳转:紧密的查看条件跳转,以确认是否能够倒置测验逻辑来改善或删去。
|
|
2
|
数据掩盖:合适静态掩盖的数据和位段被确认,并内部标识。BL51衔接/定位器能够经过大局数据流剖析,挑选可被掩盖的段。
|
|
3
|
窥孔优化:铲除剩余的MOV指令。这包括不必要的从存储区加载和常数加载操作。当存储空间或履行时刻可节省时,用简略操作替代杂乱操作。
|
|
4
|
寄存器变量:如有或许,主动变量和函数参数分配到寄存器上。为这些变量保存的存储区就省掉了。
优化扩展拜访:IDATA、XDATA、PDATA和CODE的变量直接包括在操作中。在大都时刻没必要运用中心寄存器。
部分公共子表达式删去:假如用一个表达式重复进行相同的核算,则保存第一次核算成果,后边有或许就用这成果。剩余的核算就被删去。
Case/Switch优化:包括SWITCH和CASE的代码优化为跳转表或跳转行列。
|
|
5
|
大局公共子表达式删去:一个函数内相同的子表达式有或许就只核算一次。中心成果保存在寄存器中,在一个新的核算中运用。
简略循环优化:用一个常数填充存储区的循环程序被修正和优化。
|
|
6
|
循环优化:假如成果程序代码更快和有用则程序对循环进行优化。
|
|
7
|
扩展索引拜访优化:适其时对寄存器变量用DPTR。对指针和数组拜访进行履行速度和代码巨细优化。
|
|
8
|
公共尾部兼并:当一个函数有多个调用,一些设置代码能够复用,因而削减程序巨细。
|
|
9
|
公共块子程序:检测循环指令序列,并转换成子程序。Cx51乃至重排代码以得到更大的循环序列。
|
声明:本文内容来自网络转载或用户投稿,文章版权归原作者和原出处所有。文中观点,不代表本站立场。若有侵权请联系本站删除(kf@86ic.com)https://www.86ic.net/qianrushi/256767.html