本文介绍了ARM最新型的Cortex-A7+Cortex-A15处理器的异构多核装备,以完成功用和功耗的最优。在当今移动国际里,特别是在超便携移动国际(尤以智能手机和平板电脑为主)里出现了一些令人抓狂的相似事情。这些手机运转或想象运转的运用程序类型,像实际增强和内容创立,运用更大屏幕的设备需求在极其重要的移动热能和电池约束条件下使处理才干的功用得到巨大的提高。因为这些设备还长时刻处于开机状况,并经常与 twitter feeds和facebook坚持衔接并推送电子邮件更新,因而它们还需求接连的低强度功用。最终,因为这些设备正在成为通讯、消费和核算渠道的干流设备,因而咱们期望能够延伸电池寿数来坚持咱们整天繁忙的作业。
在轿车规划方面,即便您依然期望将大型车的高功用与经济轿车的高能效合而为一,但您在组合巨细引擎时会发现第二个引擎太重了,这种做法太不实际。
而在移动CPU国际里,咱们已运用了这种概念:手机能够在同一芯片上集成CPU、图形处理器、视频引擎和音频引擎等。每一组件能够在每单位的能耗中供给最大的功用和功用。因而假如在”V8引擎”CPU 中增加其他经济型 CPU 引擎,那么就会发生芯片占用面积上的出资回报率的问题。但假如增加 ARM 的最新款 ARM Cortex-A7 CPU,即咱们最小型的、最节能的运用处理器到至高端的 ARM Cortex-A15 CPU,则能够完成性价比最优的抱负产品,这具有十分重要的含义。咱们称此概念为 big.LITTLE 处理:行将小型的、高能效的 ARM CPU 与彻底兼容的高功用 ARM CPU 严密地同步整合在一起。Cortex-A7 处理器以作为 big.LITTLE 对中的一款小型 CPU 与高端 Cortex-A15 CPU 完美地整合在一起为主旨而规划。我将在本次简述中与您共享咱们的完成进程。
咱们首先要保证在引擎切换进程中不会出现”间歇性的运转状况”。
在 big.LITTLE处理中,就意味着有必要保证小型CPU和大型CPU之间具有百分之百的软件兼容性。从用户和操作体系软件的视点而言,巨细内核有必要坚持外观上的一致性。详细来说,便是在架构上坚持一致。也便是说,Cortex-A15 和 Cortex-A7 处理器有必要具有彻底相同的指令、数据类型和寻址形式,而且它们能够发生相同的成果。在规划的其他范畴也有必要坚持一致。如缓存线巨细、40位物理地址空间、硬件虚拟化以及 128b AMBA 4 本地总线接口。
第二个要害要素便是保证具有最优化的引擎…即在小型引擎上完成每加仑燃油的最大行程,而在 V8 引擎上完成最高的功用,而且不卡齿轮。
咱们在 big.LITTLE 处理中运用的办法是在新一代移动渠道的移动剖面图以及不同的功率剖面图中确认要害的功用点。大 CPU (Cortex-A15) 旨在供给比当今高端 CPU 还要高的功用,而且满意可运用在移动电源设备中。它由更杂乱的、并行的、15 级或更高档的乱序管线组成,详细要根据指令流来确认。咱们为小型 CPU (Cortex-A7) 开发了一种天壤之别的由有序的 8 级管线组成的内核微体系架构,它能够并发履行大部分常用的指令对。与高功用内核的 NEON SIMD 单位比较,针对更大介质的 NEON SIMD 单位和浮点功用都有所下降。较小的 CPU 仅支撑履行有序的指令,但仍支撑一切相同的运算,如 64b 双精度浮点核算、针对整数和单精度浮点数据类型的双字和四字 SIMD 运算。假如较小 CPU 的功耗和运用面积接近于较大的 CPU,那么经过切换所节约的能耗并不足以证明增加另一个 CPU 群集的必要性。相似地,假如较小 CPU 的功用不能与高功用内核相对比美,那么它们之间的处理才干差异会因功用的不稳定而出现非接连性事务处理。因而,咱们有必要在功用和成效方面完成最优化才干供给适合于 big.LITTLE 的 CPU。
咱们需求保证的第三个问题是稳定的线性加快和减速。在引擎切换之间没有交代问题。
arm.com/index.php?app=core&module=attach§ion=attach&attach_rel_module=blogentry&attach_id=1200″ rel=”nofollow” >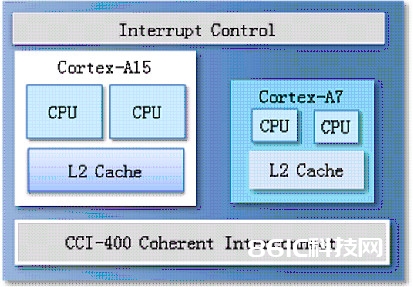
ARM 完成 big.LITTLE 处理的中心便是在较大 CPU 和较小 CPU 之间完成飞快的使命搬迁。可是快速环境搬迁所遇到的最大妨碍是时刻,也便是需求满足的时刻来铲除出站 CPU 群集上的缓存并使其无效,一起运用有用的环境来替换无效的环境。较小 Cortex-A7 和较大 Cortex-A15 处理器均具有 AMBA 一致性扩展 (ACE) 接口,这些处理器可跨 ARM 缓存一致性互联结构 (CCI-400)检查,在其他 CPU 群集的一级和二级缓存中履行查找操作。此功用的长处就在于出站 CPU 群集只需求保存由寄存器文件、CP15 寄存器值以及安全状况组成的小环境信息即可。然后在典型完成中,能够在总保存/康复时刻不到 20 微秒内,在入站CPU群会集康复这一小环境信息(如较大 CPU 运转于 1GHz 或更快)。这种快速的环境切换具有许多长处。因为切换的本钱开支很低,因而电源办理结构能够确认是切换到小群集,即便很短的时刻,也会节约能耗,仍是切换到大 CPU 群集,以便在极短的时刻里使功用瞬间到达最高。这种切换操控十分简略,因而进行切换操控的软件也十分简略。一起,您能够在运用的半途进行环境切换,如 CPU 开端出现网页时能够启用大 CPU,而在网页得到出现后能够切换到较小的 CPU,直至需求载入新网页时才切换到大 CPU。因而无需把运用程序跨CPU 切开,SoC 的电源办理设备能够瞬间切换到相应巨细的 CPU 元件中。
第四个也是最终一个需求保证的是这些引擎能够在一般情况下也能作业。
咱们需求保证有一种简略的软件办法来操控 big.LITTLE 切换,与现成的电源办理机制坚持一致。当今的智能手机和平板设备将动态电压与频率调理 (DVFS) 技能和多个闲暇形式运用于运用处理器 SoC内单个 CPU 内核和 IP 模块上。咱们所施行的 big.LITTLE 修改了后端驱动程序来操控处理器的 DVFS 运转点(例如 Linux/Android 中的 cpu_freq)。现在不再运用三个或四个 DVFS 运转点,而是经过驱动程序来感知两个 CPU 群集,每个群集都或许具有三至四个独立的电压和频率运转点,然后扩展了现有智能手机电源办理解决计划运用的功用调理的规模。big.LITTLE CPU 群集能够在纯切换形式下进行操作,即每一时刻只要一个 CPU 群集在 DVFS 驱动程序的操控下处于活动状况,也能够在异构多处理形式下进行操作,即操作体系能够为大型或小型 CPU 群集供给显式线程分配操控,并因而感知不同内核的存在。
总而言之,ARM big.LITTLE 处理所具有的这些属功用够为现代移动设备供给最佳的两种切换解决计划:与当今高端的智能手机运用处理器比较,其能耗节约了 70%,而且其最高功用比 2011款的最高端智能手机高许多。请注意这不是一个非此即彼的计划,而是在相同的作业负载下使功用和能耗均到达最优的解决计划。因为智能手机和平板电脑的作业负载具有高度动态性,因而很有或许需求两种切换形式。关于网络阅读、视频流、休闲游戏和 mp3 播映等重要的作业负载,运用 CPU 在最低的 DVFS 运转点中所用的运转时刻占 70% 至 90%,而在最高的 DVFS 运转点中所用的运转时刻仅不到 5% 左右。即便是高端的游戏作业负载或负载过重的互动网站,其最高运转点也一般只占 CPU 运转时刻的 20~30%,这样便有时机切换到或将线程分配至小 CPU 中,使其 CPU 运转时刻到达 70~80% 或更高。这能够很好地与 big.LITTLE 处理坚持一致,其间较小 Cortex-A7 能够处理一切一般的使命,但不能处理当时出售的高端运用处理器 CPU 的两个最高运转点。这能够保证 Cortex-A7 在 80% 以上的 CPU 运转时刻里供给所需的同一等级功用,这样便大大地减少了能耗,然后再根据需求瞬间切换到高功用 Cortex-A15 CPU 以完成最大的功用。让咱们再回到轿车类比中,这就像有一个处于待机状况的涡轮增压 V8 引擎在需求爬坡时从中止状况忽然加快,然后当您稍稍松开油门时,在不到一眨眼的功夫便切换到节能的引擎中。
现在在工程业界,我已领略到这国际上还真没有免费的午饭。您不或许在既有高功用又有高能效的一起,不支付一点价值。就本例而言咱们需支付的是占用面积,相关于高功用的 CPU 自身而言,附加的 CPU 群集只占用很少的一点额定区域。而在 28nm 等现代工艺结构中,Cortex-A7 CPU 的每个内核所占用的面积不到一平方毫米的一半,因而片上本钱的费用很低而且整合后的体系彻底符合专为 CPU 群集定制的芯片空间巨细要求。为了使均匀能耗比当今干流智能手机更低,功用比当今具有最高功用的智能手机还高,即便有必要在 SoC 上占用很少的一点额定区域也是适当合算的。我只期望这种做法也能运用在轿车上:经济高效、长行程、至高功用的愿望车!