实时图画处理及高速数据运算处理要求体系规划具有数据处理速度快、数据吞吐率高级特色,并具有多任务处理功用。针对这些特色,本文规划并完成了依据DSP EMIF接口及FPGA的8个DSP(7个TMS320C6416T、1 个 TMS320DM642)通讯的嵌入式体系。规划中运用TMS320DM642进行数字视频信号捕获、显现、保存以及图画信号的预处理;运用TMS320C6416做算法运算;且每个DSP与FPGA都是无缝衔接。规划中运用了FPGA完成的软FIFO进行DSP之间的高速数据传输,以及多任务调度处理等。
其他,体系还供给一个高速数据通讯接口,以使体系能够便利地对外进行高速数据传输。
1 规划的体系结构
1.1 体系结构
图1所示为1个TMS320DM642(720MHz)与7个TMS320C6416T(1GHz)经过FPGA(EP2C70-7)完成互联的多DSP体系结构。一切的DSP经过EMIF(外部存储器接口)和FPGA无缝相连,DSP之间的数据传输经过FPGA内部互联FIFO网络和高速数据传输网络完成。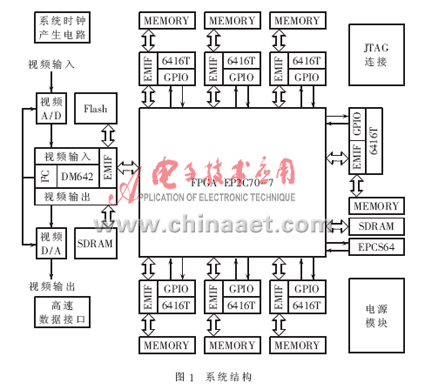
图2所示是一种互联的FIFO网络结构和高速数据传输网络结构。DM642和一切的C6416T经过FIFO彼此衔接,一切FIFO都是双向的,FIFO及其读写操控逻辑都在FPGA内部完成。
每个DSP的一部分GPIO口也衔接到EP2C70,能够作为FIFO读写状况操控,以及各DSP之间通讯前的同步握手信号等。
1.2 体系结构的特色
体系结构具有可重构特性。在硬件渠道不变的情况下,只需经过改动FPGA程序代码就能够彻底改动体系结构,以习惯不同的算法结构。若图2中屏蔽DSP1至DSP7之间的彼此通讯,就组成主从并行的流水线结构;若需求串行的流水线结构,只需DSP1至DSP7的其间一个与DSP0通讯即可。当然,若想规划更杂乱的串并混合性结构,也只需改动FPGA的代码就能够很简略的完成。
体系结构具有一个对外高速通讯接口。数据宽度64bit(双向),接口最大时钟200MHz(针对EP2C70-7),12根信号操控线(用户按自己需求经过FPGA界说),一个输出3.3V/1.5A电源。高速通讯接口不只使体系很便利与其他体系进行高速数据传输,还能够使两个本体系很简略地对接起来,构成更强壮的多DSP嵌入式体系结构。
2 TMS320DM642与视频A/D、视频D/A接口
2.1 TMS320DM642主器材简介[1][2]
TMS320DM642是TI公司2002年推出专门用于多媒体处理的高功能DSP。内部选用程序总线和数据总线别离的哈佛总线结构,使得取指令和履行指令并行;作业时钟高达720MHz,峰值处理才能为5760MIPS(百万条指令每秒);内部选用两级CACHE;有三个独立的可编程视频接口、一个64bit EMIF接口、16个GPIO等丰厚的外部接口;其他,DM642还具有64个独立的EDMA通道,使其具有很强的数据搬移才能。
2.2 接口完成[1-4]
TMS320DM642的三个独立视频接口都支撑视频捕获/显现形式,可直接与视频编解码芯片无缝衔接。在捕获形式下,器材捕获速率可达80MHz;在显现形式下,其显现速率为110MHz。体系规划时将TMS320DM642的VP0接口装备为8bit/10bit或Y/C 16bit/20bit、YUV4:2:2捕获形式,与视频解码芯片TVP5146衔接;VP1接口装备为8bit、YUV4:2:2显现形式,与视频编码芯片SAA7121衔接。TMS320DM642与视频修改解码芯片接口图如图3所示。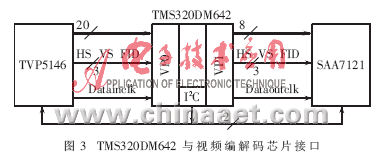
VP0装备为单通道视频输入,VP0CKL0作为输入时钟(Datainclk);VP0CTL0、VP0CTL1和VP1CTL0别离作为输入视频HS、VS、FID。
VP1装备为单通道视频输出,VP1CKL1作为视频输出时钟(Dataoutclk),VP1CKL0作为输入时钟,VP1CTL0、VP1CTL1和VP1CTL2别离作为输出视频HS、VS、FID。
其他,DM642上集成I2C总线,其数据传输速率最高可达400kb/s,别离与编解码芯片相连。规划时选用100kb/s数据传输速率对TVP5146和SAA7121的作业参数进行装备。
3 依据DSP EMIFA与FPGA完成软FIFO接口
3.1 DSP的EMIFA接口[1][2][5]
TMS320DM642和 TMS320C6416T都能够经过外部存储器接口(EMIFA)拜访片外存储器。EMIFA由64bit数据线D[63:0]、20bit地址线A[22:03]、8bit字节使能线BE[7:0]、4bit地址区域片选线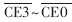 和各类存储器的读/写操控信号组成。
和各类存储器的读/写操控信号组成。
TMS320DM642和TMS320C6416T的每个/CEx空间都有256MB寻址空间,并且可装备为与SRAM、SDRAM、ZBTSRAM、Flash、FIFO等各类存储器接口。
EMIFA读/写各类存储器的时钟可由软件装备为EMIF的AECLKIN,或CPU/4、CPU/6。本规划装备为EMIF的AECLKIN,且为133MHz。
3.2 FPGA主器材及其完成FIFO[6]
FPGA选用Atera的CycloneII EP2C70-896C7。EP2C70具有68 416个逻辑单元(LE);嵌入250个RAM存储块,总容量1.152Mbit;150个专用18×18乘法器;4个锁相环(PLL);最高作业频率250MHz。
选用FPGA完成多时钟电路体系时,需求处理不一起钟域之间的速率匹配,可运用FPGA内部生成的异步FIFO来处理。异步FIFO首要有双端口RAM、写地址发生模块、读地址发生模块、满空标志发生模块组成。双端口RAM能够由FPGA的Block RAM块构成,EP2C70-896C7的Block RAM读写时钟频率能够到达216.73MHz,因而选用Block RAM作为存储体,不只速度快,并且规划简略。规划时,一个端口装备成写端口,另一端口装备成读端口,然后把Block RAM的管脚与相对应的操控信号相接即可。读写地址经过FPGA芯片内部的二进制进位逻辑发生,以对应Read_En/Write_En作为使能信号在读/写时钟的操控下进行计数。空或满标志能够由读或写地址的相对方位来取得。
3.3 EMIF与软FIFO接口完成[7]
DSP之间经过EMIF口与FPGA完成的异步FIFO进行通讯。EMIF异步接口的每个读/写周期分为三个阶段:SETUP(树立时刻)、STROBE(触发时刻)、HOLD(坚持时刻)。每个阶段时刻可编程设置,以习惯不同的读写速度。图4是DSP写异步FIFO的时序图[7]。图5是DSP读异步FIFO的时序图[7]。DSP读写FIFO操控信号由FPGA发生,其逻辑关系如下:
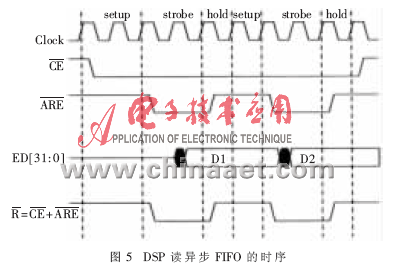
读FIFO信号:rdclk=AECLKOUT
rdreq=!(/CE+/AARE)
写FIFO信号:wdclk= AECLKOUT
wdreq=!(/CE+/AAWE)
其他,写FIFO的DSP要相应满状况标志,读FIFO的DSP则相应半满状况标志。
4 体系的DSP间数据通讯
不同的算法代码在渠道上对应不同的算法调度办法,但DSP之间数据通讯分两个进程,一是数据通讯协议,另一个是数据通讯。数据通讯协议格局如表1(x表明0、1、…7)。
Send/Receive:MDSPx经过FPGA恳求DSPx接纳(D0=1)或发送。
MDSPx:向FPGA宣布恳求的DSP。
DSPx:MDSPx向FPGA提出要求呼应的DSP。
Data_leng:MDSPx恳求DSPx接纳或发送的数据长度。
Data_Unit:1表明接纳或发送为Data_leng K(1K= 1024bit),0表明接纳或发送Data_leng。
Data_Block:表明MDSPx恳求DSPx接纳或发送Data_Block个Data_leng K或Data_leng。
Data _Character:MDSPx恳求DSPx接纳或发送的算法代码中心运转成果或终究成果。
Interr_Priority:中止优先权。
Odd_Check:奇偶校验位。
设SUM,若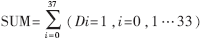 为奇数,则Odd_Check=1,否则为0。
为奇数,则Odd_Check=1,否则为0。
Over_Lable:完毕标志位,用户可自己界说。
数据通讯的完成进程:若FPGA接纳到MDSPx发来的恳求信号,先依据D[0:37]计算出校验数据,然后与Odd_Check比较。若不等,FPGA向MDSPx宣布重发恳求信号的恳求;若持平,且DSPx空闲时,FPGA再由Send/Receive告诉DSPx接纳或发送数据,并将接纳到的数据传输给DSPx,一起使对应的FIFO数据通道使能。DSPx依据收到的数据信息,相同计算出校验数据,若与Odd_Check持平,则依据Send/Receive标志位,选用EDMA方法向EMIF口接纳或发送Data_Block*Data_leng(或Data_Block*Data_leng K)数据。
假如FPGA一起接纳到两个或两个以上的MDSPx发来的恳求信号,还要由Interr_Priority判其履行的先后。
5 体系的功能剖析
多DSP嵌入式处理体系中,DSP间的数据通讯功能是影响体系功能的重要因素,而数据通讯带宽和数据传输推迟是衡量数据通讯功能的首要目标。
若体系中DSP读写FIFO的带宽为B(单位时刻内DSP间的数据通讯量),则: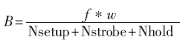
其间,f是DSP读写FIFO的时钟,w是FIFO数据总线宽度。本规划装备Nsetup=Nstrobe=1,Nhold=0,w=32 bit,f=133MHz,因而B理论值266MB/s。
但DSP间数据通讯的实践带宽Bf首要受握手时刻τhandshake、写FIFO到半满时刻τfifo_hf、呼应GPIO口中止发动读操作时刻τgpio_int err、接纳数据时刻τdata_receive四个推迟时刻影响。其间τhandshake、τgpio_int err、τdata_receive是传输数据必需的固定时刻,而τfifo_hf是因为运用FIFO缓存数据引进的额定时刻。明显,FIFO的深度越长,τfifo_hf越大,额定时刻就越长,则实践带宽Bf就越小,反之则越大。
为了确保DSP间正确的数据通讯,要求DSPx开端从FIFO读取数据时,MDSPx还没有写满FIFO,即:
表2是DSP0别离与DSP1~DSP7传输不同巨细数据时测得的均匀推迟时刻。图6是依据测验数据绘出的实践带宽Bf曲线。能够看出,跟着传输的数据增大,Bf逐步迫临B。因而,运用FPGA完成多DSP间的彼此数据通讯,既取得了较大的继续带宽,又降低了数据传输推迟。

本文规划的多DSP嵌入式体系可重构性灵敏,完成简略,功能安稳,数据吞吐量大,处理数据才能强。该嵌入式体系现已成功应用到某公司的超声图画智能辨认产品中。该产品运用体系中TMS320DM642对B超图画进行收集、保存、图画预处理、显现;运用7个TMS320C6416T对超声图画做相关算法处理。经测验,算法代码在单DSP(DM642 720MHz)渠道处理时刻小于0.4s,而在此渠道处理时刻小于40ms,满意实时要求。
其他,该体系还能够广泛适用于图画处理、电子对抗、雷达信号处理等各个领域。