一、大端方法和小端方法的来源
关于大端小端名词的由来,有一个风趣的故事,来自于Jonathan Swift的《格利佛行记》:Lilliput和Blefuscu这两个强国在曩昔的36个月中一直在苦战。战役的原因:咱们都知道,吃鸡蛋的时分,原始的办法是打破鸡蛋较大的一端,能够那时的皇帝的祖父由于小时侯吃鸡蛋,按这种办法把手指弄破了,因而他的父亲,就指令,指令一切的子民吃鸡蛋的时分,有必要先打破鸡蛋较小的一端,违令者重罚。然后老百姓对此法则极为恶感,期间产生了屡次暴乱,其间一个皇帝因而送命,另一个丢了王位,产生暴乱的原因就是另一个国家Blefuscu的国王大臣鼓动起来的,暴乱停息后,就逃到这个帝国流亡。据估计,先后几回有11000余人甘愿死也不肯去打破鸡蛋较小的端吃鸡蛋。这个其实挖苦其时英国和法国之间继续的抵触。Danny Cohen一位网络协议的开创者,第一次运用这两个术语指代字节次序,后来就被咱们广泛承受。
二、什么是大端和小端
Big-Endian和Little-Endian的界说如下:
1) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
2) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
举一个比方,比方数字0x12 34 56 78在内存中的表明方法为:
1)大端方法:
低地址 —————–> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端方法:
低地址 ——————> 高地址
0x78 | 0x56 | 0x34 | 0x12
可见,大端方法和字符串的存储方法相似。
3)下面是两个详细比方:
| 内存地址 | 小端方法寄存内容 | 大端方法寄存内容 |
| 0x4000 | 0x34 | 0x12 |
| 0x4001 | 0x12 | 0x34 |
32bit宽的数0x12345678在Little-endian方法以及Big-endian方法)CPU内存中的寄存方法(假定从地址0x4000开端寄存)为:
| 内存地址 | 小端方法寄存内容 | 大端方法寄存内容 |
| 0x4000 | 0x78 | 0x12 |
| 0x4001 | 0x56 | 0x34 |
| 0x4002 | 0x34 | 0x56 |
| 0x4003 | 0x12 | 0x78 |
4)大端小端没有谁优谁劣,各自优势就是对方下风:
小端方法 :强制转化数据不需求调整字节内容,1、2、4字节的存储方法相同。
大端方法 :符号位的断定固定为第一个字节,简单判别正负。
三、数组在大端小端状况下的存储:
以unsigned int value = 0x12345678为例,别离看看在两种字节序下其存储状况,咱们能够用unsigned char buf[4]来表明value:
Big-Endian: 低地址寄存高位,如下:
高地址
—————
buf[3] (0x78) — 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) — 高位
—————
低地址
Little-Endian: 低地址寄存低位,如下:
高地址
—————
buf[3] (0x12) — 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) — 低位
————–
低地址
四、为什么会有巨细端方法之分呢?
这是由于在计算机体系中,咱们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看详细的编译器),别的,关于位数大于8位的处理器,例如16位或许32位的处理器,由于寄存器宽度大于一个字节,那么必定存在着一个假如将多个字节安排的问题。因而就导致了大端存储方法和小端存储方法。例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。关于大端方法,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端方法,刚好相反。咱们常用的X86结构是小端方法,而KEIL C51则为大端方法。许多的ARM,DSP都为小端方法。有些ARM处理器还能够由硬件来挑选是大端方法仍是小端方法。
五、怎么判别机器的字节序
能够编写一个小的测验程序来判别机器的字节序:
- BOOLIsBigEndian()
- {
- inta=0x1234;
- charb=*(char*)&a;//经过将int强制类型转化成char单字节,经过判别开端存储方位。即等于取b等于a的低地址部分
- if(b==0x12)
- {
- returnTRUE;
- }
- returnFALSE;
- }
联合体union的寄存次序是一切成员都从低地址开端寄存,运用该特性能够轻松地获得了CPU对内存选用Little-endian仍是Big-endian方法读写:
- BOOLIsBigEndian()
- {
- unionNUM
- {
- inta;
- charb;
- }num;
- num.a=0x1234;
- if(num.b==0x12)
- {
- returnTRUE;
- }
- returnFALSE;
- }
六、常见的字节序
一般操作体系都是小端,而通讯协议是大端的。
4.1 常见CPU的字节序
Big Endian : PowerPC、IBM、Sun
Little Endian : x86、DEC
ARM既能够作业在大端方法,也能够作业在小端方法。
4.2 常见文件的字节序
Adobe PS – Big Endian
BMP – Little Endian
DXF(AutoCAD) – Variable
GIF – Little Endian
JPEG – Big Endian
MacPaint – Big Endian
RTF – Little Endian
别的,Java和一切的网络通讯协议都是运用Big-Endian的编码。
七、怎么进行转化
关于字数据(16位):
- #defineBigtoLittle16(A)((((uint16)(A)&0xff00)>>8)|
- (((uint16)(A)&0x00ff)<<8))
关于双字数据(32位):
- #defineBigtoLittle32(A)((((uint32)(A)&0xff000000)>>24)|
- (((uint32)(A)&0x00ff0000)>>8)|
- (((uint32)(A)&0x0000ff00)<<8)|
- (((uint32)(A)&0x000000ff)<<24))
八、从软件的视点了解端方法
从软件的视点上,不同端方法的处理器进行数据传递时必需求考虑端方法的不同。如进行网络数据传递时,必需求考虑端方法的转化。在Socket接口编程中,以下几个函数用于巨细端字节序的转化。
- #definentohs(n)//16位数据类型网络字节次序到主机字节次序的转化
- #definehtons(n)//16位数据类型主机字节次序到网络字节次序的转化
- #definentohl(n)//32位数据类型网络字节次序到主机字节次序的转化
- #definehtonl(n)//32位数据类型主机字节次序到网络字节次序的转化
其间互联网运用的网络字节次序选用大端方法进行编址,而主机字节次序依据处理器的不同而不同,如PowerPC处理器运用大端方法,而Pentuim处理器运用小端方法。
大端方法处理器的字节序到网络字节序不需求转化,此刻ntohs(n)=n,ntohl = n;而小端方法处理器的字节序到网络字节必需求进行转化,此刻ntohs(n) = __swab16(n),ntohl = __swab32(n)。__swab16与__swab32函数界说如下所示。
- #define___swab16(x)
- {
- __u16__x=(x);
- ((__u16)(
- (((__u16)(__x)&(__u16)0x00ffU)<<8)|
- (((__u16)(__x)&(__u16)0xff00U)>>8)));
- }
- #define___swab32(x)
- {
- __u32__x=(x);
- ((__u32)(
- (((__u32)(__x)&(__u32)0x000000ffUL)<<24)|
- (((__u32)(__x)&(__u32)0x0000ff00UL)<<8)|
- (((__u32)(__x)&(__u32)0x00ff0000UL)>>8)|
- (((__u32)(__x)&(__u32)0xff000000UL)>>24)));
- }
PowerPC处理器供给了lwbrx,lhbrx,stwbrx,sthbrx四条指令用于处理字节序的转化以优化__swab16和__swap32这类函数。此外PowerPC处理器中的rlwimi指令也能够用来完成__swab16和__swap32这类函数。
在对一般文件进行处理也需求考虑端方法问题。在大端方法的处理器下对文件的32,16位读写操作所得到的结果与小端方法的处理器不同。单纯从软件的视点了解上远远不能真实了解巨细端方法的差异。事实上,真实的了解巨细端方法的差异,必需求从体系的视点,从指令集,寄存器和数据总线上深化了解,巨细端方法的差异。
九、从体系的视点了解端方法
MSB:MoST Significant Bit ——- 最高有用位
LSB:Least Significant Bit ——- 最低有用位
处理器在硬件上由于端方法问题在规划中有所不同。从体系的视点上看,端方法问题对软件和硬件的规划带来了不同的影响,当一个处理器体系中巨细端方法一起存在时,必需求对这些不同端方法的拜访进行特别的处理。
PowerPC处理器主导网络商场,能够说绝大大都的通讯设备都运用PowerPC处理器进行协议处理和其他操控信息的处理,这也或许也是在网络上的绝大大都协议都选用大端编址方法的原因。因而在有关网络协议的软件规划中,运用小端方法的处理器需求在软件中处理端方法的改变。而Pentium主导个人机商场,因而大都用于个人机的外设都选用小端方法,包括一些在网络设备中运用的PCI总线,Flash等设备,这也要求在硬件规划中留意端方法的转化。
本文说到的小端外设是指这种外设中的寄存器以小端方法进行存储,如PCI设备的装备空间,NOR FLASH中的寄存器等等。关于有些设备,如DDR颗粒,没有以小端方法存储的寄存器,因而从逻辑上讲并不需求对端方法进行转化。在规划中,只需求将两边数据总线进行一一对应的互连,而不需求进行数据总线的转化。
假如从实践使用的视点说,选用小端方法的处理器需求在软件中处理端方法的转化,由于选用小端方法的处理器在与小端外设互连时,不需求任何转化。而选用大端方法的处理器需求在硬件规划时处理端方法的转化。大端方法处理器需求在寄存器,指令集,数据总线及数据总线与小端外设的衔接等等多个方面进行处理,以处理与小端外设衔接时的端方法转化问题。在寄存器和数据总线的位序界说上,依据巨细端方法的处理器有所不同。
一个选用大端方法的32位处理器,如依据E500内核的MPC8541,将其寄存器的最高位msb(most significant bit)界说为0,最低位lsb(lease significant bit)界说为31;而小端方法的32位处理器,将其寄存器的最高位界说为31,低位地址界说为0。与此向对应,选用大端方法的32位处理器数据总线的最高位为0,最高位为31;选用小端方法的32位处理器的数据总线的最高位为31,最低位为0。
巨细端方法处理器外部总线的位序也遵从着相同的规则,依据所选用的数据总线是32位,16位和8位,巨细端处理器外部总线的位序有所不同。大端方法下32位数据总线的msb是第0位,MSB是数据总线的第0~7的字段;而lsb是第31位,LSB是第24~31字段。小端方法下32位总线的msb是第31位,MSB是数据总线的第31~24位,lsb是第0位,LSB是7~0字段。大端方法下16位数据总线的msb是第0位,MSB是数据总线的第0~7的字段;而lsb是第15位,LSB是第8~15字段。小端方法下16位总线的msb是第15位,MSB是数据总线的第15~7位,lsb是第0位,LSB是7~0字段。大端方法下8位数据总线的msb是第0位,MSB是数据总线的第0~7的字段;而lsb是第7位,LSB是第0~7字段。小端方法下8位总线的msb是第7位,MSB是数据总线的第7~0位,lsb是第0位,LSB是7~0字段。
由上剖析,咱们能够得知关于8位,16位和32位宽度的数据总线,选用大端方法时数据总线的msb和MSB的方位都不会产生变化,而选用小端方法时数据总线的lsb和LSB方位也不会产生变化。
为此,大端方法的处理器对8位,16位和32位的内存拜访(包括外设的拜访)一般都包括第0~7字段,即MSB。小端方法的处理器对8位,16位和32位的内存拜访都包括第7~0位,小端方法的第7~0字段,即LSB。由于巨细端处理器的数据总线其8位,16位和32位宽度的数据总线的界说不同,因而需求别离进行评论在体系级别上怎么处理端方法转化。在一个大端处理器体系中,需求处理大端处理器对小端外设的拜访。
十、实践中的比方
尽管许多时分,字节序的作业已由编译器完成了,但是在一些小的细节上,依然需求去细心揣摩考虑,尤其是在以太网通讯、MODBUS通讯、软件移植性方面。这儿,举一个MODBUS通讯的比方。在MODBUS中,数据需求安排成数据报文,该报文中的数据都是大端方法,即低地址存高位,高地址存低位。假定有一16位缓冲区m_RegMW[256],由于是在x86平台上,所以内存中的数据为小端方法:m_RegMW[0].low、m_RegMW[0].high、m_RegMW[1].low、m_RegMW[1].high……
为了便利评论,假定m_RegMW[0] = 0x3456; 在内存中为0x56、0x34。
现要将该数据宣布,假如不进行数据转化直接发送,此刻发送的数据为0x56,0x34。而Modbus是大端的,会将该数据解释为0x5634而非原数据0x3456,此刻就会产生灾难性的过错。所以,在此之前,需求将小端数据转化成大端的,即进行高字节和低字节的交流,此刻能够调用过程五中的函数BigtoLittle16(m_RegMW[0]),之后再进行发送才能够得到正确的数据。
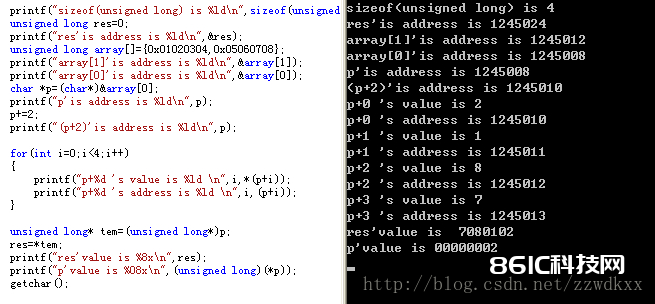
附面试题一道:(详见:http://tieba.baidu.com/p/3145609121)
unsigned long res=0;
unsigned long array ={0x01020304,0x05060708};
char *p= (char *)&array[0];
p+=2;
res = (unsigned long )*p; //原题此处错了,不然结果是2,应该这样写 res=*( (unsigned long)p )
res=?求最终res的值是多少。运转环境是win32
解析:咱们常用的X86结构是小端方法,而KEILC51则为大端方法。许多的ARM,DSP都为小端方法。有些ARM处理器还能够由硬件来挑选是大端方法仍是小端方法。巨细端的最低单位是字节。
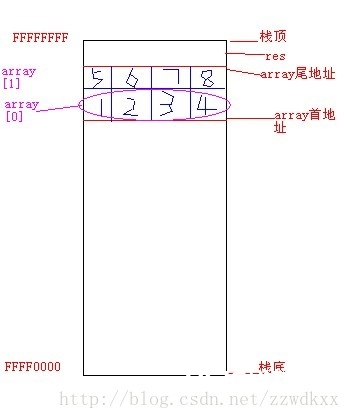 图像的不知道对不对,假如过错请纠正,谢谢~~
图像的不知道对不对,假如过错请纠正,谢谢~~
小端CPU下(低位地址存低位数据):
请留意这儿:res = (unsigned long )*p;
那么现在res的内存从低到高状况: 02 01 08 07
由于是小端CPU方法,还需求将内存存储状况转化回来,即:res=0x07080102
大端CPU方法(低位地址存高位数据):
res的内存状况: 03 04 05 06
大端方法下,无需转化,即:res=0x03040506
下面有这么一个验证: