FPGA中的硬件逻辑与软件程序的差异,信任我们在做除法运算时会有深化领会。若其间一个操作数为常数,可通过简略的移位与求和操作替代,但用硬件逻辑完结两变量间除法运算会占用较多的资源,电路结构杂乱,且一般无法在一个时钟周期内完结。因而FPGA完成除法运算并不是一个“/”号能够处理的。

好在此类根本运算均有免费的IP核运用,自己运用的VIVADO 2016.4开发环境供给的divider gen IP核均选用AXI总线接口,现已不再支撑naTIve接口。故做除法运算的要点从规划算法电路改变成了调用AXI总线IP核以及HDL中有符号数的表明问题,极大下降了开发难度。以下就上述两个方面进行讨论。
VerilogHDL中默许数据类型为无符号数,因而需求数学运算的场合有必要要用“signed”声明,如:reg signed [8-1:0] signal_a; wire signed [32-1:0] signal_b;需求留意一点,FPGA将一切有符号数视为二进制补码方法,运算的成果相同为补码。再来看看除法器IP核装备界面。
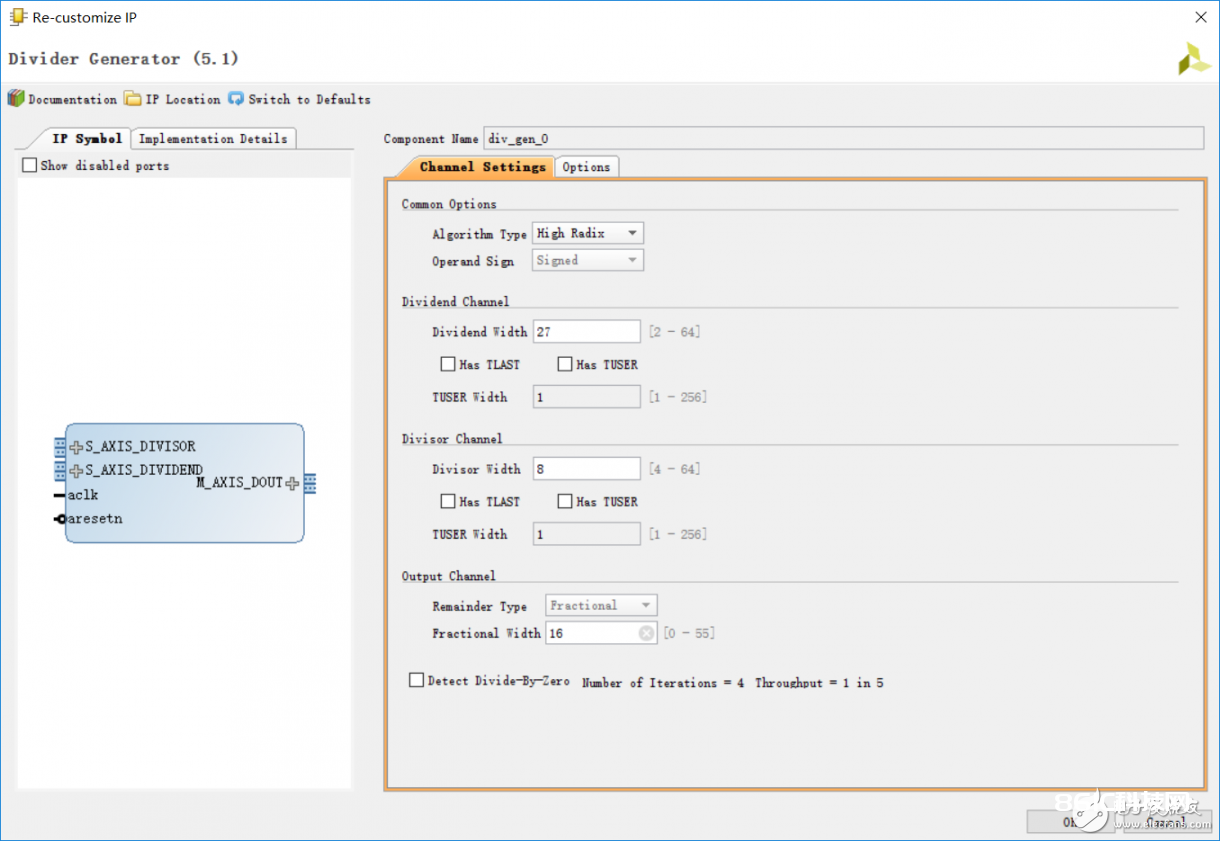

一共就两页,非常简略。需求要点重视的有三个当地:1 算法完成结构(algorithm type)2 被除数与除数的位宽 3 第二页flow control形式。现来逐个阐明:
就算法结构来说官方文档pg151 LogiCORE IP Product Guide中说得很详细:LUTMult结构操作数最好不要高于12bit,且充分运用DSP slice和BRAM以下降对FPGA 逻辑资源的耗费。Radix-2操作数不要超越16bit,且运用资源与LUTMulTI相反,许多运用register和LUT然后将DSP slice和BRAM资源节约出来用在其他当地。最终一个High Radix结构支撑超越16bit的大位宽操作数,运用DSPslice等专用硬件资源。依据自己的需求挑选即可。
位宽问题没什么好说的,需求特别留意保存位宽满意核算规模,也便是运算之前的“补码符号位扩展”。至于flow control 形式与接口和AXI总线有关。

接口划分得非常明晰,被除数 除数和商通道以及必要的时钟和复位逻辑接口。每个AXI总线通道总是包含tdata tuser tlast 和握手信号tvalid tready,其间tuser为附加信息,tlast表明流形式下最终一个数据,相当于数据包中的包尾处。数据传输仅在tvalid和tready一起拉高时有用并更新。
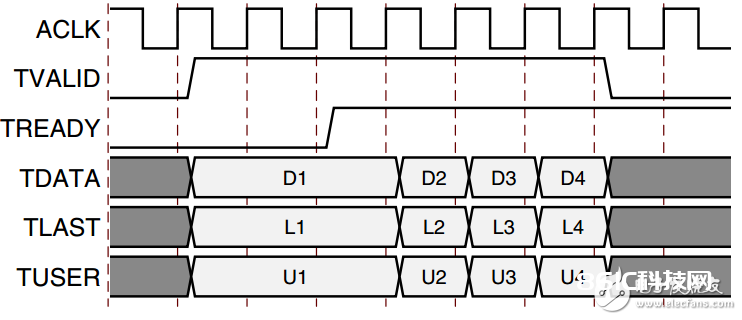
而Non Blocking Mode在除法运算时较常用,一句话归纳:IP核接口不带有FIFO缓存,输出通道数据有必要被下流模块实时处理。上图就理解了:
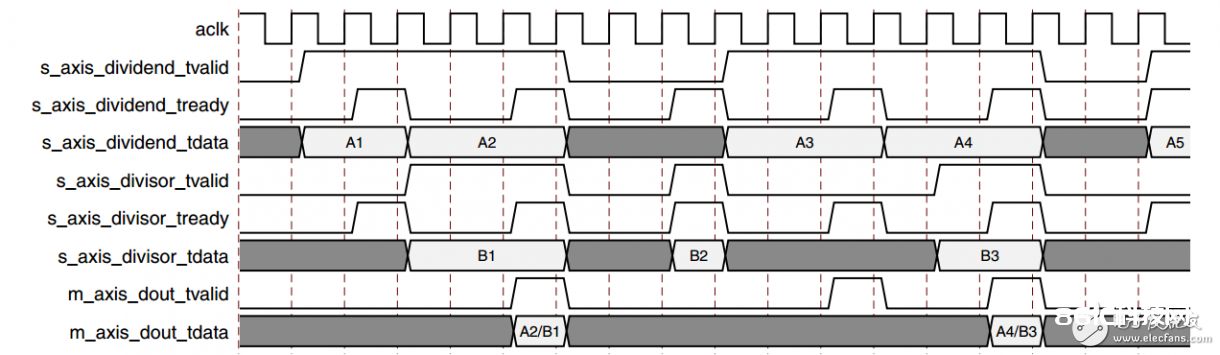
这一形式实际上是对AXI总线的简化,许多场合下并不彻底需求AXI总线强壮的流控功用,特别是在AXI总线模块的上下流均为可进行实时处理的FPGA逻辑电路的情况下。AXI总线的另一个特色便是data packing,需求将不是8bit倍数位宽的数据高位填充然后保证数据最小单位是1byte,详细填充方法有所不同。很简单想到,这样的data packing 功用对SOC中PL与PS部分的交互是非常友爱的。
整体来说,在FPGA中做根本的数学运算没什么难度,即使是指数 对数 开根号之类的杂乱运算也有浮点IP Core的支撑。