咱们调查PPT的时分,面临整个场景,不会一会儿处理悉数场景信息,而会有挑选地分配注意力,每次重视不同的区域,然后将信息整合来得到整个的视觉形象,然后辅导后边的眼球运动。将感兴趣的东西放在视界中心,每次只处理视界中的部分,疏忽视界外区域,这样做最大的优点是下降了使命的复杂度。
深度学习范畴中,处理一张大图的时分,运用卷积神经网络的核算量跟着图片像素的添加而线性添加。假如参考人的视觉,有挑选地分配注意力,就能挑选性地从图片或视频中提取一系列的区域,每次只对提取的区域进行处理,再逐渐地把这些信息结合起来,树立场景或许环境的动态内部标明,这便是本文所要叙述的循环神经网络注意力模型。
怎样完成的呢?
把注意力问题作为一系列agent决议计划进程,agent能够理解为智能体,这儿用的是一个RNN网络,而这个决议计划进程是方针导向的。扼要来讲,每次agent只经过一个带宽约束的传感器 调查环境,每一步处理一次传感器数据,再把每一步的数据跟着时刻交融,挑选下一次怎么装备传感器资源;每一步会承受一个标量的奖赏,这个agent的意图便是最大化标量奖赏值的总和。
调查环境,每一步处理一次传感器数据,再把每一步的数据跟着时刻交融,挑选下一次怎么装备传感器资源;每一步会承受一个标量的奖赏,这个agent的意图便是最大化标量奖赏值的总和。

下面咱们来详细解说一下这个网络。
如上所示,图A是带宽传感器,传感器在给定方位选取不同分辨率的图画块,大一点的图画块的边长是小一点图画块边长的两倍,然后resize到和小图画块相同的巨细,把图画块组输出到B。
图B是glimpse network,这个网络是以theta为参数,两个全衔接层构成的网络,将传感器输出的图画块组和对应的方位信息以线性网络的方法结合到一同,输出gt。
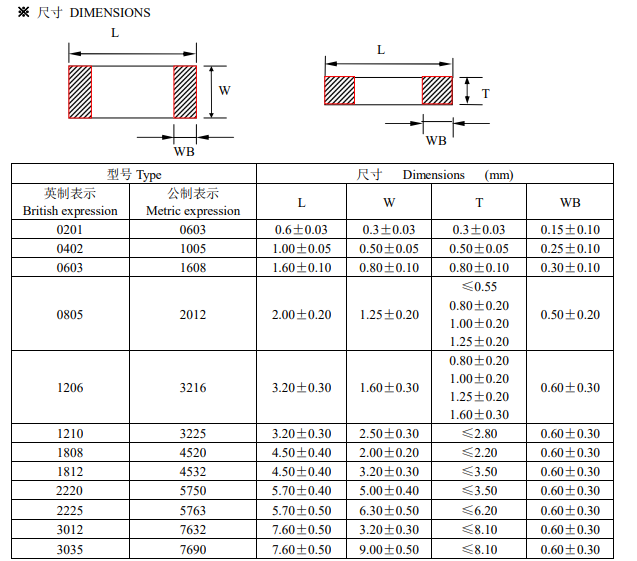
图C是循环神经网络即RNN的主体,把glimpse network输出的gt投进去,再和之前内部信息ht-1结合,得到新的状况ht,再依据ht得到新的方位lt和新的行为at,at挑选下一步装备传感器的方位和数量,以更好的调查环境。在装备传感器资源的时分,agent也会遭到一个奖赏信号r,比方在辨认中,正确分类r是1,过错分类r是0,agent的方针是最大化奖赏信号r的和:
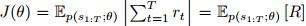
梯度的近似能够标明为:

公式(1)也叫做增强学习的规矩,它包含运用当时的战略运转agent去取得交互序列,然后依据能够增大奖赏信号的行为调整theta。它的练习进程便是用增强学习的方法学习详细使命战略。关于给定使命,依据模型做出的一系列决议给出体现点评,最大化体现点评,对其进行端到端的优化。
首要为什么要用增强学习呢?由于数据的状况不是十分清晰的,不是能够直接监督或许非监督来练习的,比方机器人的操控很难彻底准确。
那么什么是增强学习呢?
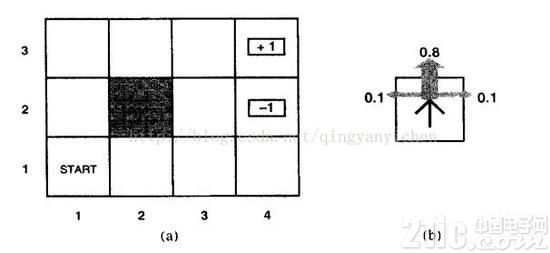
增强学习重视的是智能体怎么在环境中采纳一系列行为,然后取得最大的累积报答。RL是从环境状况到动作的映射的学习,咱们把这个映射称为战略。经过增强学习,一个智能体(agent)应该知道在什么状况下应该采纳什么行为。
假定一个智能体处于下图(a)中所示的4×3的环境中。从初始状况开端,它需求每个时刻挑选一个行为(上、下、左、右)。在智能体抵达标有+1或-1的方针状况时与环境的交互停止。假如环境是确认的,很简单得到一个解:[上,上,右,右,右]。惋惜智能体的举动不是牢靠的(相似实践中对机器人的操控不可能彻底准确),环境不一定沿这个解开展。下图(b)是一个环境搬运模型的暗示,每一步举动以0.8的概率到达预期,0.2的概率会垂直于运动方向移动,撞到(a)图中黑色模块后会无法移动。两个停止状况别离有+1和-1的报答,其他状况有-0.4的报答。现在智能体要处理的是经过增强学习(不断的试错、反应、学习)找到最优的战略(得到最大的报答)。
上述问题能够看作为一个马尔科夫决议计划进程,终究的方针是经过一步步决议计划使全体的报答函数希望最优。
说到马尔科夫,咱们一般会马上想起马尔可夫链(Markov Chain)以及机器学习中愈加常用的隐式马尔可夫模型(Hidden Markov Model, HMM)。它们都具有一起的特性便是马尔可夫性:当一个随机进程在给定现在状况及一切曩昔状况状况下,未来状况的条件概率散布仅依赖于当时状况;换句话说,在给定现在状况时,它与曩昔状况是条件独立的,那么此随机进程即具有马尔可夫性质。具有马尔可夫性质的进程一般称之为马尔可夫进程。
马尔可夫决议计划进程(Markov Decision Process),其也具有马尔可夫性,与上面不同的是MDP考虑了动作,即体系下个状况不只和当时的状况有关,也和当时采纳的动作有关。
一个马尔科夫决议计划进程(Markov Decision Processes, MDP)有五个要害元素组成{S,A,{Psa},γ,R},其间:

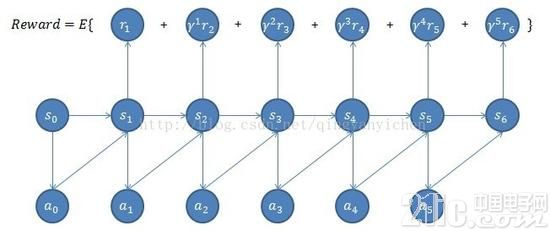


这个便是马尔科夫决议计划进程。讲完马尔科夫决议计划之后咱们回过头回忆一下练习的进程:每次agent只经过一个带宽约束的传感器调查环境,每一步处理一次传感器数据,再把每一步的数据跟着时刻交融,挑选下一次怎么装备传感器资源;每一步会承受一个标量的奖赏,这个agent的意图便是最大化标量奖赏值的总和。
注意力模型的效果怎么
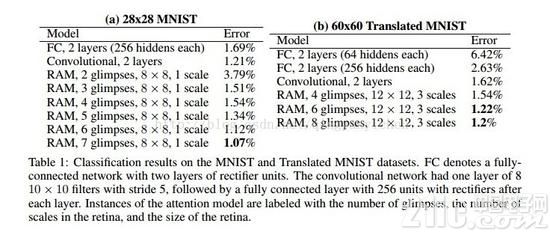
把注意力模型和全衔接网络以及卷积神经网络进行比较,试验证明了模型能够从多个glimpse结合的信息中成功学习,而且学习的效果优于卷积神经网络。
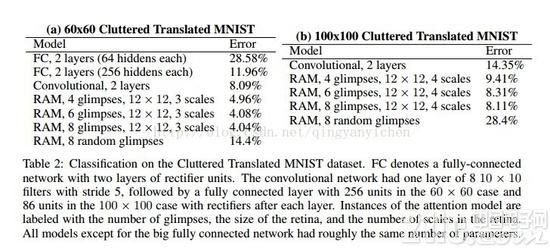

由于注意力模型能够重视图画相关部分,忽视无关部分,所以能够在在有搅扰的状况下辨认,辨认效果也是比其他网络要好的。下面这个图体现的是注意力的途径,标明网络能够避免核算不重要的部分,直接探究感兴趣的部分。
根据循环神经网络的注意力模型比较有特征的当地就在于:
● 进步核算功率,处理比较大的图片的时分十分好用;
● 堵塞状况下也能辨认。
咱们讲了半响,一个重要的概念没有讲,下面来讲讲循环神经网络RNN。
咱们做卷积神经网络的时分样本的次序并不遭到重视,而关于自然语言处理,语音辨认,手写字符辨认来说,样本呈现的时刻次序是十分重要的,RNNs呈现的意图是来处理时刻序列数据。
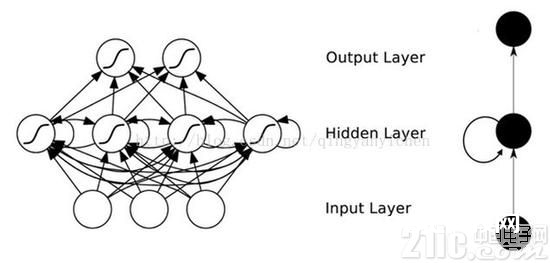
这个网络最直观的形象是什么呢,便是线多。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全衔接的,每层的节点之间是无衔接的。可是这种一般的神经网络关于许多问题却没有方法。例如,要猜测句子的下一个单词,一般需求用到前面的单词,由于一个句子中前后单词并不是独立的。RNNs之所以称为循环神经网路,即一个序列当时的输出与前面的输出也有关,网络会对前面的信息进行回忆并应用于当时输出的核算中,详细的体现形式为即躲藏层之间的节点不再无衔接而是有衔接的,而且躲藏层的输入不只包含输入层的输出还包含上一时刻躲藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。可是在实践中,为了下降复杂性往往假定当时的状况只与前面的几个状况相关,下图便是一个典型的RNNs:
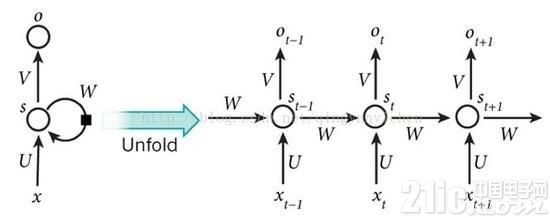
T时刻的输出是该时刻的输入和一切前史一起的成果,这就到达了对时刻序列建模的意图。RNN能够当作一个在时刻上传递的神经网络,它的深度是时刻的长度。关于t时刻来说,它发生的梯度在时刻轴上向前史传达几层之后就消失了,根本就无法影响太悠远的曩昔。因而,之前说“一切前史”一起效果仅仅抱负的状况,在实践中,这种影响也就只能保持若干个时刻戳。
为了处理时刻上的梯度消失,机器学习范畴开展出了长短时回忆单元LSTM,经过门的开关完成时刻上回忆功用,并避免梯度消失。
RNN还能够用在生成图画描绘之中,用CNN网络做辨认和分类,用RNN网络发生描绘句子,这便是李飞飞的试验室所研讨的内容。