ARM指令集:
ADC 带进位的32位数加法
ADD 32位数相加
AND 32位数的逻辑与
B 在32M空间内的相对跳转指令
BIC 32位数的逻辑位清零
BKPT 断点指令
BL 带链接的相对跳转指令
BLX 带链接的切换跳转
BX 切换跳转
CDP\CDP2 协处理器数据处理操作
CLZ 零计数
CMN 比较两个数的相反数
CMP 32位数比较
EOR 32位逻辑异或
LDC\LDC2 从协处理器取一个或多个32位值
LDM 从内存送多个32位字到ARM寄存器
LDR 从虚拟地址取一个单个的32位值
MCR\MCR2\MCRR 从寄存器送数据到协处理器
MLA 32位乘累加
MOV 传送一个32位数到寄存器
MRC\MRC2\MRRC 从协处理器传送数据到寄存器
MRS 把状况寄存器的值送到通用寄存器
MSR 把通用寄存器的值传送到状况寄存器
MUL 32位乘
MVN 把一个32位数的逻辑“非”送到寄存器
ORR 32位逻辑或
PLD 预装载提示指令
QADD 有符号32位饱满加
QDADD 有符号双32位饱满加
QSUB 有符号32位饱满减
QDSUB 有符号双32位饱满减
RSB 逆向32位减法
RSC 带进位的逆向32法减法
SBC 带进位的32位减法
SMLAxy 有符号乘累加(16位*16位)+32位=32位
SMLAL 64位有符号乘累加((32位*32位)+64位=64位)
SMALxy 64位有符号乘累加((32位*32位)+64位=64位)
SMLAWy 32位有号乘累加((32位*16位)>>16位)+32位=32位
SMULL 64位有符号乘累加(32位*32位)=64位
SMULxy 32位有符号乘(16位*16位=32位)
SMULWy 32位有符号乘(32位*16位>>16位=32位)
STC\STC2 从协处理器中把一个或多个32位值存到内存
STM 把多个32位的寄存器值寄存到内存
STR 把寄存器的值存到一个内存的虚地址内间
SUB 32位减法
SWI 软中止
SWP 把一个字或许一个字节和一个寄存器值沟通
TEQ 等值测验
TST 位测验
UMLAL 64位无符号乘累加((32位*32位)+64位=64位)
UMULL 64位无符号乘累加(32位*32位)=64位
依据RISC 的ARM CPU
ARM是一种RISC体系结构的处理器芯片。和传统的CISC体系结构不同,RISC 有以下的几个特征:
◆ 简练的指令集——为了确保CPU能够在高时钟频率下单周期碑文指令,RISC指令集只供给很有限的操作(例如add,sub,mul等),而杂乱的操作都需求由这些简略的指令来组合进行模仿。并且,每一条指令不只碑文时间固定,其指令长度也是固定的,这样,在译码阶段就能够对下一条指令进行预取。
◆ Load-Store 结构——这个应该是RISC 规划中比较有特征的一部分。在RISC 中,CPU并不会对内存中的数据进行操作,一切的核算都要求在寄存器中完结。而寄存器和内存的通讯则由独自的指令来完结。而在CSIC中,CPU是能够直接对内存进行操作的,这也是一个比较特别的当地。
◆ 更多的寄存器——和CISC 比较,依据RISC的处理器有更多的通用寄存器能够运用,且每个寄存器都能够进行数据存储或许寻址。
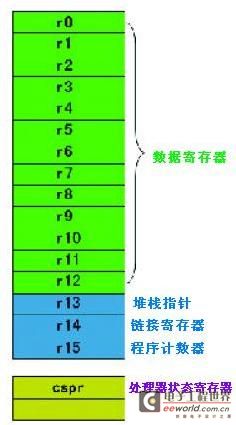
图:user方法下ARM处理器体系结构
◆ r13 – 指向其时栈顶,适当于x86的esp,这个东西在汇编指令中要用sp 一共
◆ r14 – 称作链接寄存器,指向函数的回来地址。用lr一共,这和x86将回来地址保存在栈中是不同的
◆ r15 – 类似于x86的eip,其值等于其时正在碑文的指令的地址+8(咱们在取址和碑文之间多了一个译码的阶段),这个用pc一共
ARM 指令集
ARM处理器能够支撑3种指令集——ARM,Thumb和Jazelle。
选用那种指令集,由cspr中的标志位来决议。大体说来:
◆ ARM——这是ARM本身的32 位指令集
◆ Thumb ——这是一个全16 位的指令集,在16 位外部数据总线宽度下,这个指令集的功率要比32 位的ARM指令高一些。
◆ Jazelle ——这是一个8位指令集,用来加快Java字节码的碑文
{S} [Rd], [Rn], [Rm]
其间:
* {S} —— 加上这个后缀的指令会更新cpsr 寄存器
* [Rd] —— 意图寄存器
* [Rn]/[Rm] —— 源寄存器
一般来说,arm 指令有3个操作数,其间Rm寄存器在碑文指令前能够进入桶形移位器进行移位操作,而Rn则会直接进入ALU 单元。假如一条arm 指令只需2 个操作数,那么源寄存器依照Rm 来处理。例如,一条加法指令:
add r0, r1, #1
就会把r1+1的成果寄存到r0中。
Load-Store 指令体系
◆ 单寄存器传输(这是与x86 最为相像的)
◆ 多寄存器传输
◆ 沟通指令
单寄存器传输
先看榜首个,很简略:把单一的数据传入(LDR) 或传出(STR)寄存器,对内存的拜访能够是DWORD(32-bit), WORD(16-bit)和BYTE(8-bit)。指令的格局如下:
DWORD:
Rd, addressing1
WORD:
H Rd, addressing2 无符号版
SH Rd, addressing2 有符号版
BYTE:
B Rd, addressing1 无符号版
SB Rd, addressing2 有符号版
addressing1 和addressing2 的分类下面再说,现在了解成某种寻址方法就能够了。
在单寄存器传输方面,还有以下三种变址方法,他们是:
◆ preindex
这种变址方法和x86的寻址机制是很类似的,先对寄存器进行运算,然后寻址,可是在寻之后,基址寄存器的内容并不产生改动,例如:
ldr r0, [r1, #4]
的含义便是把r1+4 这个地址处的DOWRD 加载到r0,而寻址后,r1 的内容并不改动。
◆ preindex with writeback
这种变址方法有点类似于++i的含义,寻址前先对基地址寄存器进行运算,然后寻址. 其底子的语法是在寻址符[]后边加上一个”!” 来一共.例如:
ldr r0, [r1, #4]!
就能够分解成:
add r1, r1, #4
ldr r0, [r1, #0]
◆ postindex
天然这种变址方法和i++的方法就很类似了,先运用基址寄存器进行寻址,然后对基址寄存器进行运算,其底子语法是把offset 部分放到[]外面,例如:
ldr r0, [r1], #4
就能够分解成:
ldr r0, [r1, #0]
add r1, r1, #4
假如你还记得x86 的SIB 操作的话,那么你必定想ARM是否也有,答案是有也没有。在ss上面提到的addressing1 和addressing2的差异便是份额寄存器的运用,addressing1能够运用[base, scale, 桶形移位器]来完结SB 的作用,或许经过[base,offset](这儿的offset 能够是当即数或许寄存器)来完结SI 的作用,而addressing2则只能用后者了。所以每一种变址方法最多能够有3 种寻址方法,这样一来,最多能够有9种用来寻址的指令方法。例如:
ldr r0, [r1, r2, LSR #0x04]!
ldr r0, [r1, -#0x04]
ldr r0, [r1], LSR #0x04
每样找了一种,大约便是这个意思。到此,单寄存器传输就完毕了,把握这些满足敷衍差事了。下面来看看多寄存器传输吧。
多寄存器传输
<寻址方法> Rn{!}, {r^}
咱们先来搞了解寻址方法,多寄存器传输方法有4 种:
也便是说以A最初的都是在Rn的原地开端操作,而B最初的都是以Rn的下一个方位开端操作。假如你依然感到困惑,咱们无妨看个比方。
一切的示例指令碑文前:
mem32[0x1000C] = 0x04
mem32[0x10008] = 0x03
mem32[0x10004] = 0x02
mem32[0x10000] = 0x01
r0 = 0x00010010
r1 = 0x00000000
r3 = 0x00000000
r4 = 0x00000000
1) ldmia r0!, {r1-r3} 2) ldmib r0!, {r1-r3}
碑文后:
r0 = 0x0010001C
r1 = 0x01
r2 = 0x02
r3 = 0x03
至于DA 和DB 的方法,和IA / IB 是类似的,不多说了。
终究要说的是,运用ldm 和stm指令对进行寄存器组的维护是很常见和有用的功用。配对方案:
stmia / ldmdb
stmib / ldmda
stmda / ldmib
stmdb / ldmia
持续来看两个比方:
碑文前:
r0 = 0x00001000
r1 = 0x00000003
r2 = 0x00000002
r3 = 0x00000001
碑文的指令:
stmib r0!, {r1-r3}
mov r1, #1 ; These regs have been modified
mov r2, #2
mov r3, #3
其时寄存器状况:
r0 = 0x0000100C
r1 = 0x00000001
r2 = 0x00000002
r3 = 0x00000003
ldmia r0!, {r1-r3}
终究的成果:
r0 = 0x00001000
r1 = 0x00000003
r2 = 0x00000002
r3 = 0x00000001
别的,咱们还能够运用这个指令对完结内存块的高效copy:
loop
ldmia r9!, {r0-r7}
stmia r10!, {r0-r7}
cmp r9, r11
bne loop
提到这儿,读者应该对RISC的Load-Store体系结构有一个大约的了解了,能够正确配对运用指令,是很重要的。
ARM 反常处理
假如您阅览ARM手册,您会发现,在ARM中,常常着重Exception(反常)这个概念,在ARM里,Interrupt(中止)也是一种方法的反常。ARM的Exception同其所界说的5种反常方法是密切相关的,CPU在捕获到任何一个Exception后,必定会进入某个反常方法,反常类型及捕获到该反常后CPU所进入的反常方法之间的对应联络是ARM所预先界说好的。
假如您对X86比较了解,您会发现,不象X86,体系界说了不同的中止,比方键盘中止,鼠标中止等等,并且体系也界说了这些中止所对应的中止向量。ARM没有界说这些,ARM只会告知你,有外部中止产生,并切换到IRQ或FIQ方法,然后碑文IRQ或FIQ所对应的中止向量。至于终究是键盘中止,仍是鼠标中止,这得由操作体系供给的中止函数自己去判别,比方经过查询中止操控器的某个或某些寄存器。ARM这样做的原因是:ARM仅仅一个CORE,它并不界说也不去设想其外部环境,这样能够使得ARM CORE愈加紧凑和简练,一同也给SOC规划者供给了更多的灵敏性和发挥空间。您必定要信任,ARM被如此广泛运用不是“盖”的,从体系开发者视点看,ARM是一种最简略、最灵敏的CPU,它的高雅和简练性就像C言语相同。呵呵,C言语是我最喜爱的言语。
好了,“臭屁”了这么多,咱们言归正传。对ARM反常处理的研讨务必要弄清楚以下几个方面:
(1) 反常类型
(2) 反常类型及处理该反常时CPU的碑文方法
(3) 反常向量地址
(4) 反常处理进程
反常类型
ARM界说了如下类型的反常(江南七怪,这样好记):
(1)
(2)
(3)
(4)
(5)
(6)
(7)
碑文方法
当产生反常后,CPU会进入相应的反常方法并处理该反常:
向量地址
ARM的反常向量地址能够处于4G物理空间的低端(0x00000000起),也能够处于高端(0xffff0000起),详细是哪种状况,依据详细的CPU及其装备而定。下面是7种反常的向量地址(挎弧内为高端景象):
(1)
(2)
(3)
(4)
(5)
(6)
(7)
每个中止向量为4字节,一般的操作体系在该地址处放置一条跳转指令“LDR PC,终端处理函数地址”。别的要留意的是,在IRQ反常和Data Abort反常之间空了4个字节,这4个字节是保存的。
处理进程
Linux BOOTLOADER全程详解
网上关于Linux的BOOTLOADER文章不少了,可是大都是vivi,blob等比较巨大的程序,读起来不太便利,编译出的文件也比较大,并且更多的是面向开发用的引导代码,做成产品时还要削减,这必定程度影响了开发速度,对初学者学习开支也比较大,在此剖析一种简略的BOOTLOADER,是在三星公司供给的2410BOOTLOADER上略微修正后的成果,编译出来的文件巨细不超越4k,期望对咱们有所协助.
1.几个重要的概念
COMPRESSED KERNEL and DECOMPRESSED KERNEL
紧缩后的KERNEL,依照文档材料,现在不发起运用DECOMPRESSED KERNEL,而要运用COMPRESSED KERNEL,它包含了解压器.因而要在ram分配时给紧缩和解压的KERNEL供给满足空间,这样它们不会彼此掩盖.当碑文指令跳转到 COMPRESSED KERNEL后,解压器就开端作业,假如解压器探测到解压的代码会掩盖掉COMPRESSED KERNEL,那它会直接跳到COMPRESSED KERNEL后寄存数据,并且从头定位KERNEL,所以假如没有满足空间,就会犯错.
Jffs2 File System
能够使armlinux运用中产生的数据保存在FLASH上,我的板子还没用到这个.
RAMDISK
运用RAMDISK能够使ROOT FILE SYSTEM在没有其他设备的状况下发动.一般有两种加载方法,我就介绍最常用的吧,把COMPRESSED RAMDISK IMAGE放到指定地址,然后由BOOTLOADER把这个地址经过发动参数的方法ATAG_INITRD2传递给KERNEL.详细看代码剖析.
发动参数(摘自IBM developer)
在调用内核之前,应该作一步准备作业,即:设置 Linux 内核的发动参数。Linux 2.4.x 今后的内核都期望以符号列表(tagged list)的方法来传递发动参数。发动参数符号列表以符号 ATAG_CORE 开端,以符号 ATAG_NONE 完毕。每个符号由标识被传递参数的 tag_header 结构以及随后的参数值数据结构来组成。数据结构 tag 和 tag_header 界说在Linux 内核源码的include/asm/setup.h 头文件中.
在嵌入式 Linux 体系中,一般需求由 BOOTLOADER 设置的常见发动参数有:ATAG_CORE、ATAG_MEM、ATAG_CMDLINE、ATAG_RAMDISK、ATAG_INITRD等。
(注)参数也能够用COMMANDLINE来设定,在我的BOOTLOADER里,我两种都用了.
2.开发环境和开发板装备:
CPU:S3C2410,BANK6上有64M的SDRAM(两块),BANK0上有32M NOR FLASH,串口当然是逃不掉的.这样,依照数据手册,地址分配如下:
0x4000_0000开端是4k的片内DRAM.
0x0000_0000开端是32M FLASH 16bit宽度
0x3000_0000开端是64M SDRAM 32bit宽度
留意:操控寄存器中的BANK6和BANK7部分有必要相同.
0x4000_0000(片内DRAM)寄存4k以内的BOOTLOADER IMAGE
0x3000_0100开端寄存发动参数
0x3120_0000 寄存COMPRESSED KERNEL IMAGE
0x3200_0000 寄存COMPRESSED RAMDISK
0x3000_8000 指定为DECOMPRESSED KERNEL IMAGE ADDRESS
0x3040_0000 指定为DECOMPRESSED RAMDISK IMAGE ADDRESS
开发环境:Redhat Linux,armgcc toolchain, armlinux KERNEL
怎样树立armgcc的编译环境:主张运用toolchain,而不要自己去编译armgcc,偶试过好屡次,都以失利告终.
先下载arm-gcc 3.3.2 toolchain
将arm-linux-gcc-3.3.2.tar.bz2 解压到 /toolchain
# tar jxvf arm-linux-gcc-3.3.2.tar.bz2
# mv /usr/local/arm/3.3.2 /toolchain
在makefile 中在把arch=arm CROSS_COMPILE设置成toolchain的途径还有便是INCLUDE = -I ../include -I /root/my/usr/local/arm/3.3.2/include.,不然库函数就不能用了
3.发动方法:
能够放在FLASH里发动,或许用Jtag仿真器.咱们运用NOR FLASH,依据2410的手册,片内的4K DRAM在不需求设置便能够直接运用,而其他存储器有必要先初始化,比方告知memory controller,BANK6里有两块SDRAM,数据宽度是32bit,= =.不然memory control会依照复位后的默许值来处理存储器.这样读写就会产生过错.
所以榜首步,经过仿真器把碑文代码放到0x4000_0000,(在编译的时分,设定TEXT_BASE=0x40000000)
第二步,经过 AxD把linux KERNEL IMAGE放到方针地址(SDRAM)中,等候调用
第三步,碑文BOOTLOADER代码,从串口得到调试数据,引导armlinux
4.代码剖析
讲了那么多碑文的进程,是想让咱们对发动有个大约选用,接着便是BOOTLOADER内部的代码剖析了,BOOTLOADER文章内容网上许多,我这儿精简了下,删除了不必要的功用.
BOOTLOADER一般分为2部分,汇编部分和c言语部分,汇编部分碑文简略的硬件初始化,C部分担任仿制数据,设置发动参数,串口通讯等功用.
BOOTLOADER的生命周期:
1. 初始化硬件,比方设置UART(至少设置一个),检测存储器= =.
2. 设置发动参数,这是为了告知内核硬件的信息,比方用哪个发动界面,波特率 = =.
3. 跳转到Linux KERNEL的首地址.
4. 消亡
当然,在引导阶段,象vivi等,都用虚地址,假如你嫌烦的话,就用实地址,都相同.
咱们来看代码:
2410init.s
.global _start//开端碑文处
_start:
//下面是中止向量
b reset @ Supervisor Mode//从头发动后的跳转
⋯⋯
⋯⋯
reset:
ldr r0,=WTCON /WTCON地址为53000000,watchdog的操控寄存器 */
ldr r1,=0x0
str r1,[r0]
ldr r0,=INTMSK
ldr r1,=0xffffffff
str r1,[r0]
ldr r0,=INTSUBMSK
ldr r1,=0x3ff
str r1,[r0]
ldr r0, =GPFCON
ldr r1, =0x55aa
str r1, [r0]
ldr r0, =GPFUP
ldr r1, =0xff
str r1, [r0]
ldr r0,=GPFDAT
ldr r1,=POWEROFFLED1
str r1,[r0]
ldr r0,=CLKDIVN
ldr r1,=0x3
str r1,[r0]
ldr r0,=LOCKTIME
ldr r1,=0xffffff
str r1,[r0]
ldr r0,=MPLLCON
ldr r1,=((M_MDIV<<12)+(M_PDIV<<4)+M_SDIV) //Fin=12MHz,Fout=203MHz
str r1,[r0]
ldr r1,=GSTATUS2
ldr r10,[r1]
tst r10,#OFFRST
bne 1000f
//以上这段,我没动,就用三星写的了,下面是首要要改的当地
add r0,pc,#MCDATA – (.+8)// r0指向MCDATA地址,那里寄存着MC初始化要用到的数据
ldr r1,=BWSCON // r1指向MC操控器寄存器的首地址
add r2,r0,#52 // 仿制次数,偏移52字
1: //依照偏移量进行循环仿制
ldr r3,[r0],#4
str r3,[r1],#4
cmp r2,r0
bne 1b
.align 2
MCDATA:
.word (0+(B1_BWSCON<<4)+(B2_BWSCON<<8)+(B3_BWSCON<<12)+(B4_BWSCON<<16)+(B5_BWSCON<<20)+(B6_BWSCON<<24)+(B7_BWSCON<<28))
上面这行便是BWSCON的数据,详细参数含义如下:
需求更改设置DW6 和DW7都设置成10,即32bit,DW0 设置成01,即16bit
下面都是每个BANK的操控器数据,大都是时钟相关,能够用默许值,设置完MC后,就跳到调用main函数的部分
.word ((B0_Tacs<<13)+(B0_Tcos<<11)+(B0_Tacc<<8)+(B0_Tcoh<<6)+(B0_Tah<<4)+(B0_Tacp<<2)+(B0_PMC)) .word ((B1_Tacs<<13)+(B1_Tcos<<11)+(B1_Tacc<<8)+(B1_Tcoh<<6)+(B1_Tah<<4)+(B1_Tacp<<2)+(B1_PMC)) .word ((B2_Tacs<<13)+(B2_Tcos<<11)+(B2_Tacc<<8)+(B2_Tcoh<<6)+(B2_Tah<<4)+(B2_Tacp<<2)+(B2_PMC)) .word ((B3_Tacs<<13)+(B3_Tcos<<11)+(B3_Tacc<<8)+(B3_Tcoh<<6)+(B3_Tah<<4)+(B3_Tacp<<2)+(B3_PMC)) .word ((B4_Tacs<<13)+(B4_Tcos<<11)+(B4_Tacc<<8)+(B4_Tcoh<<6)+(B4_Tah<<4)+(B4_Tacp<<2)+(B4_PMC)) .word ((B5_Tacs<<13)+(B5_Tcos<<11)+(B5_Tacc<<8)+(B5_Tcoh<<6)+(B5_Tah<<4)+(B5_Tacp<<2)+(B5_PMC)) .word ((B6_MT<<15)+(B6_Trcd<<2)+(B6_SCAN)) .word ((B7_MT<<15)+(B7_Trcd<<2)+(B7_SCAN)) .word ((REFEN<<23)+(TREFMD<<22)+(Trp<<20)+(Trc<<18)+(Tchr<<16)+REFCNT) .word 0xB2 .word 0x30 .word 0x30 .align 2 .global call_main //调用main函数,函数参数都为0 call_main: ldr sp,STACK_START mov fp,#0 mov a1, #0 mov a2, #0 bl main STACK_START: .word STACK_BASE undefined_instruction: software_interrupt: prefetch_abort: data_abort: not_used: irq: fiq:
2410init.c file int main(int argc,char **argv) { u32 test = 0; void (*theKERNEL)(int zero, int arch, unsigned long params_addr) = (void (*)(int, int, unsigned long))RAM_COMPRESSED_KERNEL _BASE; //紧缩后的IMAGE地址 int i,k=0; // downPt=(RAM_COMPRESSED_KERNEL_BASE); chkBs=(_RAM_STARTADDRESS);//SDRAM开端的当地 // fromPt=(FLASH_LINUXKERNEL); MMU_EnableICache(); ChangeClockDivider(1,1); // 1:2:4 ChangeMPllValue(M_MDIV,M_PDIV,M_SDIV); //Fin=12MHz FCLK=200MHz Port_Init();//设置I/O端口,在运用com口前,有必要调用这个函数,不然通讯芯片底子得不到数据 Uart_Init(PCLK, 115200);//PCLK运用默许的200000,拨特率115200 Uart_SendString("ntLinux S3C2410 Nor BOOTLOADERn"); Uart_SendString("ntChecking SDRAM 2410loader.c...n"); for(;chkBs<0x33FA0140;chkBs=chkBs+0x4,test++)//
//依据我的阅历,最好以一个字节为递加,咱们的板子,在256byte递加检测的时分是没问题的,可是
//以1byte递加就犯错了,第13跟数据线随几的会冒”1”,检测出来是硬件问题,现象如下
//用仿真器下代码测验SDRAM,开端没贴28F128A3J FLASH片子,测验成果很好,但在上了FLASH片子//之后,测验数据(data)为0x00000400
接连成批写入读出时,操作大约1k左右内存空间就会犯错,//并且随机。那个犯错数据总是变为0x00002400,数据总线10位和13位又没短路
产生。用其他数据//测验比方0x00000200;0x00000800没这问题。dx协助。
//至今没有处理,所以我用不了Flash.
{
chkPt1 = chkBs;
*(u32 *)chkPt1 = test;//写数据
if(*(u32 *)chkPt1==1024))//读数据和写入的是否相同?
{
chkPt1 += 4;
Led_Display(1);
Led_Display(2);
Led_Display(3);
Led_Display(4);
}
else
goto error;
}
Uart_SendString("ntSDRAM Check Successful!ntMemory Maping...");
get_memory_map();
//取得可用memory 信息,做成列表,后边会作为发动参数传给KERNEL
//所谓内存映射便是指在4GB 物理地址空间中有哪些地址规模被分配用来寻址体系的 RAM 单元。
Uart_SendString("ntMemory Map Successful!n");
//我用仿真器把KERNEL,RAMDISK直接放在SDRAM上,所以下面这段是不需求的,可是假如KERNEL,RAMDISK在FLASH里,那就需求.
Uart_SendString("tLoading KERNEL IMAGE from FLASH... n "); Uart_SendString("tand copy KERNEL IMAGE to SDRAM at 0x31000000n"); Uart_SendString("ttby LEIJUN DONG dongleijun4000@hotmail.com n"); for(k = 0;k < 196608;k++,downPt += 1,fromPt += 1)//3*1024*1024/32linux KERNEL des,src,length=3M * (u32 *)downPt = * (u32 *)fromPt; Uart_SendString("ttloading COMPRESSED RAMDISK...n"); downPt=(RAM_COMPRESSED_RAMDISK_BASE); fromPt=(FLASH_RAMDISK_BASE); for(k = 0;k < 196608;k++,downPt += 1,fromPt += 1)//3*1024*1024/32linux KERNEL des,src,length=3M * (u32 *)downPt = * (u32 *)fromPt; Uart_SendString("ttloading jffs2...n"); downPt=(RAM_JFFS2); fromPt=(FLASH_JFFS2); for(k = 0;k < (1024*1024/32);k++,downPt += 1,fromPt += 1) * (u32 *)downPt = * (u32 *)fromPt; Uart_SendString( "Load Success...Run...n "); setup_start_tag();//开端设置发动参数 setup_memory_tags();//内存选用 setup_commandline_tag("console=ttyS0,115200n8");//发动命令行 setup_initrd2_tag();//root device setup_RAMDISK_tag();//ramdisk image setup_end_tag(); asm ("mrc p15, 0, %0, c1, c0, 0": "=r" (i)); i &= ~0x1000; asm ("mcr p15, 0, %0, c1, c0, 0": : "r" (i)); asm ("mcr p15, 0, %0, c7, c5, 0": : "r" (i));
//下面这行就跳到了COMPRESSED KERNEL的首地址
theKERNEL(0, ARCH_NUMBER, (unsigned long *)(RAM_BOOT_PARAMS));
//发动kernel时分,I-cache能够开也能够关,r0有必要是0,r1有必要是CPU类型
(能够从linux/arch/arm/tools/mach-types中找到),r2有必要是参数的物理开端地址
error: Uart_SendString("nnPanic SDRAM check error!n"); return 0; } static void setup_start_tag(void) { params = (struct tag *)RAM_BOOT_PARAMS;//发动参数开端的地址 params->hdr.tag = ATAG_CORE; params->hdr.size = tag_size(tag_core); params->u.core.flags = 0; params->u.core.pagesize = 0; params->u.core.rootdev = 0; params = tag_next(params); } static void setup_memory_tags(void) { int i; for(i = 0; i < NUM_MEM_AREAS; i++) { if(memory_map[i].used) { params->hdr.tag = ATAG_MEM; params->hdr.size = tag_size(tag_mem32); params->u.mem.start = memory_map[i].start; params->u.mem.size = memory_map[i].len; params = tag_next(params); } } } static void setup_commandline_tag(char *commandline) { int i = 0; params->hdr.tag = ATAG_CMDLINE; params->hdr.size = 8; //console=ttyS0,115200n8 strcpy(params->u.cmdline.cmdline, p); params = tag_next(params); } static void setup_initrd2_tag(void) { params->hdr.tag = ATAG_INITRD2; params->hdr.size = tag_size(tag_initrd); params->u.initrd.start = RAM_COMPRESSED_RAMDISK_BASE; params->u.initrd.size = 2047;//k byte params = tag_next(params); } static void setup_ramdisk_tag(void) { params->hdr.tag = ATAG_RAMDISK; params->hdr.size = tag_size(tag_ramdisk); params->u.ramdisk.start = RAM_DECOMPRESSED_RAMDISK_BASE; params->u.ramdisk.size = 7.8*1024; //k byte params->u.ramdisk.flags = 1; // automatically load ramdisk params = tag_next(params); } static void setup_end_tag(void) { params->hdr.tag = ATAG_NONE; params->hdr.size = 0; } void Uart_Init(int pclk,int baud)//串口是很重要的 { int i; if(pclk == 0) pclk = PCLK; rUFCON0 = 0x0; //UART channel 0 FIFO control register, FIFO dISAble rUMCON0 = 0x0; //UART chaneel 0 MODEM control register, AFC dISAble //UART0 rULCON0 = 0x3; //Line control register : Normal,No parity,1 stop,8 bits 下面这段samsung好象写的不太对,可是我依照Normal,No parity,1 stop,8 bits算出来的确是0x245 // [10] [9] [8] [7] [6] [5] [4] [3:2] [1:0] // Clock Sel, Tx Int, Rx Int, Rx Time Out, Rx err, Loop-back, Send break, Transmit Mode, Receive Mode // 0 1 0 , 0 1 0 0 , 01 01 // PCLK Level Pulse DISAble Generate Normal Normal Interrupt or Polling rUCON0 = 0x245; // Control register rUBRDIV0=( (int)(PCLK/16./ baud) -1 ); //Baud rate divisior register 0 delay(10); }
经过以上的折腾,接下来便是kernel的活了.能不能发动kernel,得看你编译kernel的水平了.
ARM嵌入式入门的主张
咱们许多人总问这个问题,所以这儿做一个总结文档供咱们参阅。这儿有必要先阐明,以下的进程都是针对Linux体系的,并不面向WinCE。惹祸你会留意到,现在做嵌入式的人中,做linux研讨的人远比做WinCE的人多,许多产家供给的材料也是以linux为主。我一向很难了解,其实WinCE的界面比linux的界面美观多了,运用起来也很便利,更为重要的是,WinCE的开发和Windows下的开发底子相同,学起来简略得多,可是学linux或许运用linux做嵌入式的人便是远比WinCE多。在和许多作业的人沟通时我了解到,他们公司从没考虑运用WinCE,咱们本钱高,都是运用linux进行开发。我读研讨生的的试验室中也没有运用WinCE的,大都研讨linux,也有少部分项目运用vxwork,可是就没有传闻过运用WinCE的,原因便是开源!当然现在WinCE6.0传闻也开源,不过在本钱和资源上linux现已有了无人能挡的优势。与此相对应的是,越来越多的电子厂商现已开端运用linux开发产品。举个比方,Google近期开发的智能手机操作体系Android其实便是运用linux-2.6.23内核进行改善得到的。
榜首,学习底子的裸机编程。
关于学硬件的人而言,有必要先对硬件的底子运用方法有理性的知道,更有必要深入知道该硬件的操控方法,假如一开端就学linux体系、学移植那么只会立刻就堕入一个很深的漩涡。我在刚刚开端学ARM的时分是挑选ARM7(主见是其时ARM9还很贵),学ARM7的时分仍是保持着学51单片机的思想,运用ADS去编程,榜首个试验便是操控led。学过一段时间ARM的人都会笑这样很笨,实际上也不是,我却是觉得有这个进程会好许多,咱们不管做多杂乱的体系终究都会落实到这些最底层的硬件操控,因而对这些硬件的操控有了理性的知道就好许多了
学习裸机的编程的一同要好好了解这个硬件的构架、操控原理,这些我称他为了解硬件。所谓的了解硬件便是说,了解这个硬件是怎样安排这么多资源的,这些资源又是怎样由cpu、由编程进行操控的。比方说,s3c2410中有AD转换器,有GPIO(通用IO口),还有nandflash操控器,这些东西都有一些寄存器来操控,这些寄存器都有一个地址,那么这些地址是什么意思?又怎样经过寄存器来操控这些外围设备的作业?还有,norflash内部的每一个单元在这个芯片的内存中都有一个相应的地址单元,那么这些地址与刚刚说的寄存器地址又有什么联络?他们是相同的吗?而与norflash相对应的nandflash内部的贮存单元并不是线性排放的,那么s3c2410怎样将nandflash的地址映射在内存空间打听行运用?或许简略地说应该怎样用nandflash?再有,运用ADS进对ARM9行编程时都需求运用到一个初始化的汇编文件,这个文件终究有什么用?他晒干的代码是什么意思?不要这个能够吗?
诸如此类都是对硬件的了解,了解了这些东西就对硬件有很深的了解了,这对今后更深一步的学习将有很大的协助,假如越过这一步,我信任越往后学越会觉得苍茫,越觉得这写东西莫测高深。咱们,你的根基没打好。
不过先声明一下,自己并没有运用ADS对ARM9进行编程,我是学完ARM7后直接就运用ARM9学linux体系的,因而触及运用ADS对ARM9进行编程的问题我很难答复^_^,自己去研讨研讨吧。
关于这部分不久将供给一份教程,这个教程中的例程并不是我为咱们所署理的板子写的,是我在咱们学院试验室拿的,英培特为他们自己的试验箱写的,不过很有学习含义,能够作为一份有价值的参阅。
第二,运用linux体系进行一些底子的试验。
第三,研讨完好的linux体系的的运转进程。
所谓完好的linux体系包含哪些部分呢?
三部分:bootloader、linux kernel(linux内核)、rootfile(根文件体系)。
那么这3部分是怎样彼此协作来构成这个体系的呢?各自有什么用呢?三者有什么联络?怎样联络?体系的碑文流程又是怎样样的呢?搞清楚这个问题你对整个体系的运转就很清楚了,关于下一步制造这个linux体系就打下了另一个重要的根基。介绍这方面的材料网上能够发掘到几吨,自己好好研讨吧。
第四,开端做体系移植。
上面提到完好的linux有3部分,并且你也知道了他们之间的联络和作用,那么现在你要做的便是自己着手学会制造这些东西。
当然我不或许叫你编写这些代码,这不完结。事实上这个3者都能在网下载到相应的源代码,可是这个源代码不或许下载编译后就能在你的体系上运转,需求许多的修正,直到他能运转在你的板子上,这个修正的进程就叫移植。在进行移植的进程中你要学的东西许多,要懂的相关常识惹祸多,等你完结了这个进程你会发现你现已算是一个初出茅庐的高手了。
在这个进程中假如你很有研讨精力的话你必然会想到看源代码。许多书介绍你怎样阅览linux源代码,我不发起无意图地去看linux源代码,用许三多的话说,这没有含义。等你在做移植的时分你觉得你有必要去看源代码时再去找底子好书看看,这儿我引荐一本好书倪继利的《linux内核的剖析与编程》,这是一本针对linux-2.6.11内核的书,说得很深,主张先进步自己的C言语编程水平再去看。
至于每个部分的移植网上也能够找到许多吨的材料,自己研讨研讨吧,不过要提示的是,许多介绍自己阅历的东西都或多或少有所保存,你依照他说的去做总有一些问题,可是他不会告知你怎样处理,这时就要靠自己,假如自己都靠不住就找我一同研讨研讨吧,我也不能确保能处理你的问题,咱们我未必遇到过你的问题,不过我信任能给你一点主张,惹祸有助你处理问题。
这一步的终究意图是,从源代码的官方主页上(都是外国的,悲痛)下载规范的源代码包,然后进行修正,终究运转在板子上。
盗用阿基米德的一句话:“给我一根网线,我能将linux搞定”。
第五,研讨linux驱动程序的编写。
移植体系并不是终究的意图,终究的意图是开发产品,做项目,这些都要进行驱动程序的开发。
Linux的驱动程序能够说是形形色色,linux2.4和linux2.6的编写有适当大的差异,便是同为linux2.6可是不同版别间的驱动程序也有差异,因而编写linux的驱动程序变都不是那么简单的工作,关于最新版别的驱动程序的编写乃至还没有满足的参阅材料。那么我的主张便是运用、移植一个不算很新的版别内核,这样届时学驱动的编程就有满足的材料了。
这部分的引荐书本能够参阅另一篇文章《引荐几本学习嵌入式linux的书本》。
第六,研讨运用程序的编写。
做著作做项目除了编写驱动程序,终究还要编写运用程序。现在的趋势是图形运用程序的开发,而图形运用程序中用得最多的仍是qt/e函数库。我一向就运用这个函数库来开发自己的运用程序,不过我期望你能运用国产的MiniGUI函数库。盗用周杰伦的广告词便是“支撑国产,支撑MiniGUI”。MiniGUI的编程比较类似Windows下的VC编程,比较简单上手,作用应该说是适当不错的,我曾运用过来开发ARM7的程序。不过MiniGUI最大的欠好便是没有像qtopia这样的图形操作渠道,这大大约束了他的推行,我从前幻想过与北京飞漫公司(便是MiniGUI的版权具有者)协作运用MiniGUI函数库开发像qtopia这样的图形操作渠道,不过咱们水平有限这只能是幻想了,呵呵。
完结这一步你底子就学完了嵌入式linux的全部内容了。
还有一个小小的阅历想和咱们共享。我在学习嵌入式linux的进程中很少问人,客观原因是身边的教师、同学师兄都没有这方面的高手,片面原因是我不喜爱问人,喜爱自己研讨处理问题。这样做有个优点,便是能够进步自己处理问题的才能,咱们做这些东西总有许多问题你难以了解,他人也没有这方面的阅历,也不是一切问题都有人给你答案,这时有必要要自己处理问题,这样,个人的处理问题才能就显得十分要害了。因而我的主张便是一般的问题到网上查找一下,的确找不到答案了就问问高手,仍是不行了就自己去研讨,不要一味去等他人帮你处理问题。
记住,问题是学习的最好时机。