摘要:文中具体地剖析了Altera公司Cyclone V FPGA器材的硬核存储操控器底层架构和外部接口,并在此基础上对Controller和PHY进行了功用仿真。仿真结果表明硬核存储操控器和PHY合作作业时的功用与规划预期相符,功用优秀,合适于在当时FPGA的外部存储带宽需求日益增长的场合下运用。
现在,越来越多的运用场景都需求FPGA可以和外部存储器之间树立数据传输通道,如视频、图画处理等范畴,而且对数据传输通道的带宽也提出了较大的需求,这就导致了FPGA和外部Memory接口的实践有用带宽成为了限制体系功用的瓶颈,所以Memoiy操控器的效能,则成为提高体系功用的要害要素。Altera最新一代28nm器材中的Cyclone V和Arria V系列FPGA都集成了硬核存储操控器HMC(Hard Memory Controll er)单元,比较于以往的软核解决方案,硬核解决方案可以在协助下降体系功耗的一起明显提高接口作业功用,合适运用于对Memory接口带宽有较大需求的场合。
1 存储器接口的底层架构
QuartusII 11.0及今后版别供给的Controller操控器均为High Performance ControllerII(HPC II),相对于前期供给的HPC,有了部分功用和功用上的晋级和改善。CycloneII/IV运用的是ALTMEMPHY,而Cyclone V可以运用新的UniPHY架构。存储器接口的底层架构和外部接口如图1所示。
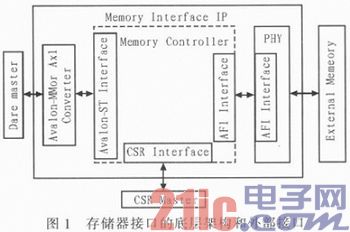
从图1可见,整个存储接口是由三部分组成的,Controller单元、PHY单元及一些相关接口。其间首要的就是Controller单元、PHY单元。Controller单元首要担任操控初始化、改写等Memory的指令操作,还可以完结拜访地址和数据的安排排序,支撑大带宽、较高的作业频率。别的,Controller单元还支撑数据重排,可以下降拜访抵触,添加体系作业的功率。PHY单元作业在Controller单元和外部Memory之间,首要担任完结物理层的数据途径及数据途径的时序处理。
Controller单元和PHY单元之间是经过Altera PHYInterface,即AFI接口进行衔接的。与规范的DDR PHYInterface,即DFI接口比较,AFI接口愈加合适依据ALTMEMPHY和UniPHY的开发。AFI接口可以被认为是DFI接口的子集,是对DFI接口进行了少数的简化和修正而来的。
2 MPFE的功用及底层架构
在视频和图画处理范畴,FPCA需求频频地拜访Memory接口,完结数据的写入和渎出操作。Cyclone V的HMC可以支撑多端口前端的并行拜访,极大当地便了读写数据交互的操作。多端口前端,即MPFE(Multi-port Front End),底层架构如图2所示。
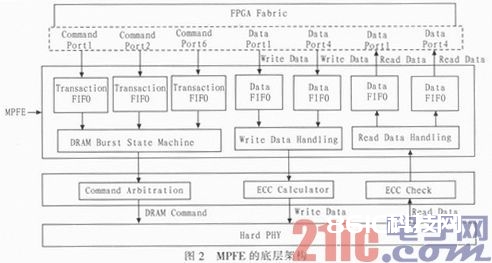
MPFE可以使得FPGA的多个处理进程同享一个Memory的指令行列。这样不同的端口都可以拜访Memory接口,完结对Memory的读写操作。MP FE都是依据Avalon总线的时序进行地址、指令和数据的交互的。在实践有用带宽必定的状况下,MPFE可以将带宽依照不同的需求分配到相应的端口。
如图2所示,MPFE是由6个指令FIFO,4个64bit位宽的读FIFO和4个64bit位宽的写FIFO组成,经过这些FIFO来完结指令和数据的交互。其间,读FIFO可以被装备为单向的读FIFO,写FIFO可以被装备为单向的写FIFO,也可以在一个Port里运用双向FIFO、此刻该Port会调用1个读FIFO和1个写FIFO来完结。
假如前端的数据位宽比较大,也可以将FIFO拼接起来,组合为128bit或256bit位宽的FIFO,128bit位宽状况下,会调用2个读或写FIFO 256bit位宽状况下,会调用4个读或写FIFO。假如一个Port设置为256bit位宽,一起设置为双向FIFO.则该Port会耗费悉数的读写FIFO,此刻也就相当于将多端口前端作为单端口前端来运用了。
假如前端的数据位宽比较小,也可以将64bit位宽的FIFO设置为32bit位宽,此刻仍会占用1个FIFO,高32bit的数据位宽则会搁置。
由此可见,MPFE在运用上非常灵敏,可以习惯不同的运用方法,满意FPGA内部不同逻辑模块对Memory的读写拜访。
3 多端口前端的调度战略
MPFE自身相当于一个调度器,选用分时复用的方法,对来自不同端口的数据和指令进行调度。若干个端口之间的调度遵从两个条件,即端口的优先级(Priority)和权重(Weight)。优先级参数和权重参数是可以指定的,如图3所示,在IP例化时的Controller Settings界面中,手动填写端口的这两个参数值。
优先级参数可以在1~7之间恣意指定,优先级参数值越大,代表该端口的优先级越高。高优先级的端口相对于低优先级的端口会被优先调度。优先级是一个肯定的参数,假如一个端口的优先级设置为7,则这个端口享有最高优先级,它在任何状况下都会被优先调度,这样别的的优先级为6或更低优先级的端口有必要等候优先级为7的端口作业完结之后才会被调度。
假如两个端门的优先级相同,那么相对的优先级会取决于端口的权重参数。权重参数可以在0~31之间设置。为了防止高优先级的某个端口长期占用接口总线的带宽,引入了加权循环调度算法(Weighted Round Robin,WRR),WRR算法仍然会优先处理高优先级的端口,可是低优先级的端口也不会呈现不被调度的状况。WRR是依据端口权重与一切排队等候调度的端口的权重总和的比来平等地分配带宽。因而,在处理多个端口的高优先等级的事务时,可以保证每个端口都不会过度地占用接口的总线带宽。
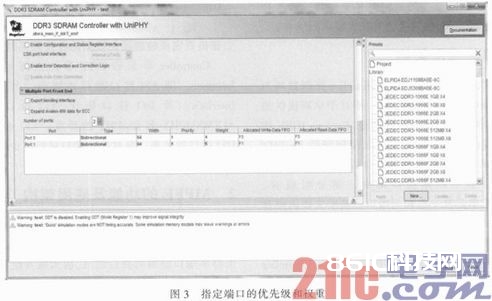
在端口的优先级参数都相同的状况下,权重参数可以决议端口间相对的带宽分配,如图3所示,端口0和端口1的优先级均为1,权重参数值分e为4和6,则端口0和端口1分e会占用大致40%和60%的Memory接口总带宽。
4 HMC的ModelSim功用仿真
仿真进程不只可以观察到HMC内部作业的时序,还可以大致测箅出HMC作业时的有用带宽。在体系规划开端阶段,可以用于评价Memory接口实践有用带宽是否满意规划需求。如图4和图5所示。
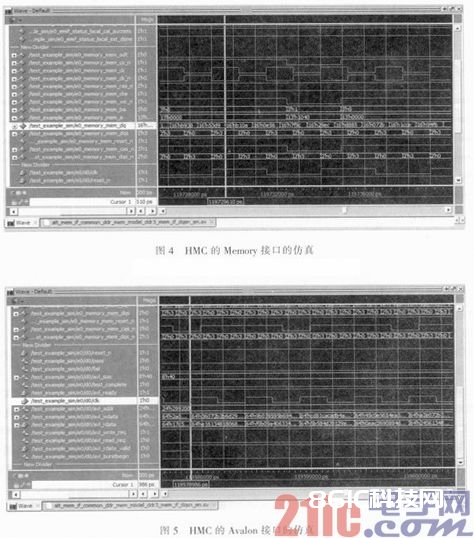
体系规划的进程需求保证Avalon侧和Memory侧的带宽持平,所以在IP例化参数挑选时,依据DDR3器材参数,DQ数据线挑选的是16 bits位宽,mem_ck为400 MHz;Avalon侧的数据位宽为64 bits,时钟挑选200 MHz即可。两边带宽为16 bitsx400 Mhzx2(DDR双沿传输)=64 bitsx200 MHz=12.8 Gbps,这也是HMC的理论带宽。
5 定论
在一些视频、图画等高带宽按口运用中,Cyclone V器材的HMC理论上可以到达至少12.8Gbps的带宽,假如DQ位宽变为32位,则理论带宽翻倍到25.6Gbps,这也是一个HMC所能到达的理论带宽的上限。部分Cyclone V器材带有2个HMC,则全体的理论带宽上限值为51.2Gbps,已可以满意高带宽存储场合对FPGA和DDR3间接口带宽的要求。