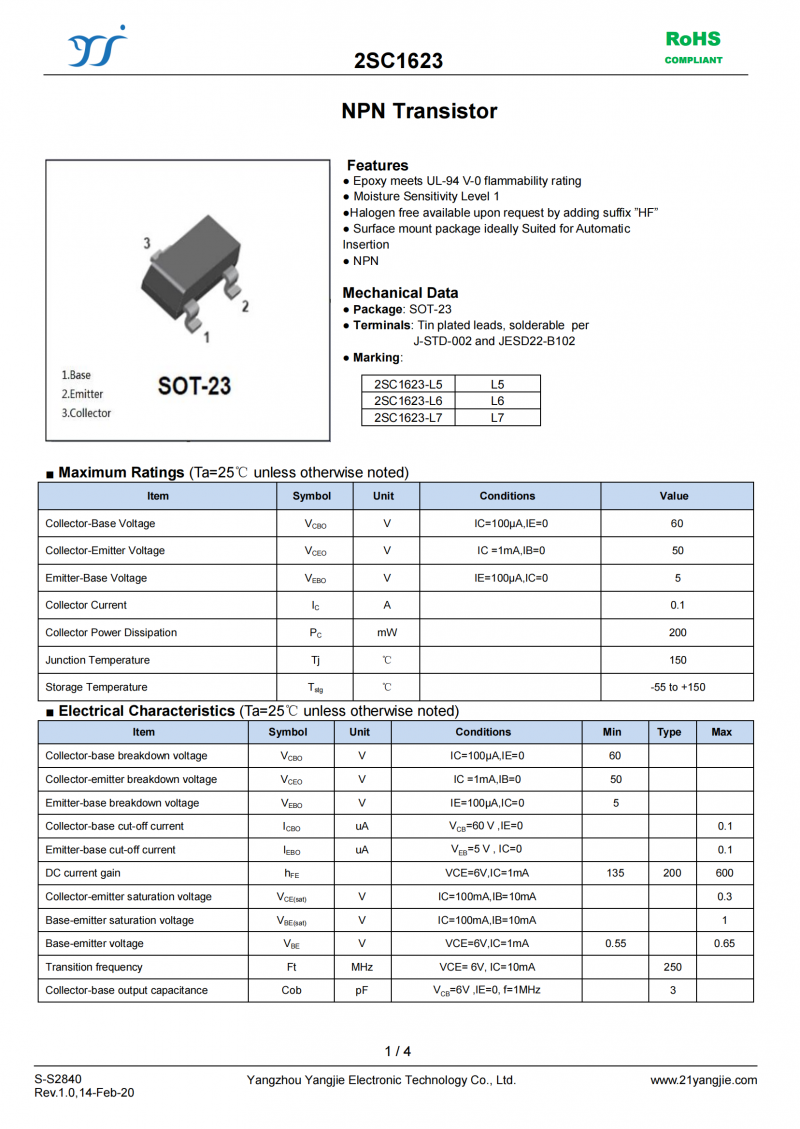
传统数字信号处理器 (DSP) 的架构在特定的信号处理核算运用中现已显得绰绰有余。而超长指令字 (VLIW) 和单指令/多数据 (SIMD) 架构的组合却可供给高核算功用所需的并行吞吐量,其数据一般为16、24 和 32 位字宽。这十分合适语音/音频和通讯等运用中运用的算法。在前几代 DSP 算法开发中,体系和软件开发人员会在 MathWorksMATLAB® 中开发体系算法,随后再将算法移至 DSP,在转移时,会将 MATLAB 的浮点数据类型输出转化为定点类型输出。 DSP开发者经过定点数据来满意循环和精确方面核算的需求,一起使硬件的运用和功耗降至最低水平。
因为上市时刻的需求,新的算法和核算运用自定义软件算法以及新产品更急进的上市时刻窗口来区别产品。当时体系或许跳过从浮点到定点的转化过程,而只保留在 DSP 上运转浮点。轿车 ADAS 和 RADAR/LiDAR 等较新运用要求在核算途径的一切部分中都具有高精度的需求。在前端 FFT 核算中,较大的点 FFT(例如 4K、8K 和更高的点 FFT)无法在定点(溢出)坚持位精度。因而,为了取得最高功用则需求合作单精度或半精度浮点数据类型。 在各种轿车运用中,尤其是 ADAS、动力总成和马达操控/办理中,用于更快/更流通的体系呼应的猜测建模正变得越来越遍及。猜测建模运用能够依据各种输入来猜测成果的核算模型。这种完成方法的优点在于DSP 处理器能够运转高度杂乱的模型,而且能够呼应更广规模的传感器和环境输入并更快地生成输出。机器学习算法关于匹配猜测模型的状况也很有协助,该算法能够协助学习预期的成果并进一步改进呼应时刻和输出质量。猜测建模最好在依据线性代数的算法中运用单精度浮点来完成,以确认核算数据的规模和精确性。一起,能够将数学核算归类为线性代数运算在 DSP 处理器上进行很多核算。 具有高功用处理的运用 – (例如每秒 10 吉比特数据速率的 5G 无线通讯,以及每秒需求 200 吉比特以上数据吞吐量的轿车 ADAS、RADAR 和 LiDAR)都需求具有十分宽的向量核算才能,以及具有高度并行履行才能的 DSP。这些新的 DSP 核算驱动要素改变了传统 DSP 内核的架构和指令集架构 (ISA) 要求。DSP 需求极高水平的核算吞吐量,并需一起具有高水平的单精度和半精度浮点核算。传统 DSP 处理器要点履行定点数据类型处理,而添加的浮点单元在处理才能和功耗方面并非是最佳挑选。传统的 DSP 处理器对线性代数的指令支撑有限,关于矩阵转置运算, 尽管供给 SQRT 和/或 1/SQRT 支撑,但关于线性代数算法的完好规模则有必要对数学运算进行软件仿真。
新一代的 DSP 内核能满意浮点和线性代数数据吞吐量的核算要求。该DSP 是 DesignWare® ARC® VPX5 处理器 IP计划会在其间作为本机架构的一部分来开发浮点和线性代数向量核算,并经过向量 SIMD 和 VLIW 架构有用完成超高水平的并行处理。DesignWare ARC VPX5 处理器 IP 具有四个并行履行维度(图 1)。

图 1:在 DesignWare ARC VPX5 处理器 IP 上并行履行的 4 个维度
第 1 维度:浮点的多 SIMD 核算引擎 根本向量数据长度为 512 位,然后能够对 8 位、16 位和 32 位数据,或半精度和单精度浮点数据的数据单元进行 SIMD 核算。一切 SIMD 引擎都运用 512 位向量长度进行核算;这就确认了 ARC VPX5 处理器的核算才能上限。 关于 8 位、16 位和 32 位长度的整数数据,有两个 512 位 SIMD 核算引擎以及三个 ALU 处理单元。这为机器学习卷积运算(5×5、3×3 和 1×1)等算法供给了十分高的核算水平。 关于半精度和单精度浮点核算,有三个向量 SIMD 核算引擎,一切引擎都支撑 512 位的最大向量长度。用于“惯例”浮点向量运算的双 SIMD 引擎,为包含FFT的DSP函数和矩阵运算等在内的浮点向量运算供给了超高功用。 第三向量 SIMD 浮点引擎专用于线性代数数学函数。这种专用引擎答应卸载和并行核算数学函数,将会在第 4 维度部分中进一步阐明。 第 2维度:凭仗多使命发布 VLIW 完成灵敏性 在 4 次发布 VLIW 计划中履行灵敏分配,使处理器能够尽或许分配最多的并行操作。VLIW 计划的开发与软件编译器的开发作业完成了密切合作,因而编译器会预先分配在原始 C 代码程序中编译的运算符。编译器与 VLIW 架构相结合,能够跨多个 SIMD 引擎并行履行操作 例如,图 2 显现了编译器怎么能够结合 VLIW 分配计划,仅运用两个 VLIW 插槽即可完成跨三个浮点 SIMD 引擎的并行履行,而且完成最佳的 VLIW 插槽分配和更小的指令代码巨细。因为两个向量 SIMD 浮点引擎具有零周期刺进推迟,一切能够在每个周期将向量数据加载到 SIMD 引擎中。线性代数向量 SIMD 引擎的刺进推迟为四个周期,因而在加载数据之后,需求额定等候三个周期,直到能够加载新的向量数据停止。编译器能够为这种不同的刺进推迟预先分配 VLIW 插槽,然后在一切三个向量 SIMD 浮点引擎上供给有用的并行履行。

图 2:三个并行向量 FPU 履行的编译器分配
第 3 维度:可装备为单核、双核及四核 DesignWare ARC VPX5 处理器 IP 与多个向量 SIMD 核算引擎并行,并带有 VLIW 分配功用, 答应将单核扩展到双核和四核装备。这样能够依据需求将单核 VPX5 的核算功用进步一倍或三倍,以满意更高的核算需求。DesignWare ARC metaWare 开发东西彻底支撑跨多核装备的代码编译和履行。此外,因为产品包含信号功用,所以可支撑多核使命履行和同步。 关于单核、双核和四核装备,数据移动是 VPX5 产品的要害。有一个 2D 直接内存拜访 (DMA) 引擎,可装备多达四个以上的通道,每个周期最多供给 512 位传输。DMA 能够在各个多核的数据存储器之间、本地集群存储器之间或在外部 AXI 总线的输入/输出之间并行移动数据。这种高功用 DMA 与 VPX5 处理器的高核算吞吐量相辅相成,使向量 SIMD 引擎能够不断拜访每个内核上与本地严密耦合的向量数据存储器中的新向量数据。 第 4 维度:线性代数核算 许多新一代算法运用依靠线性代数根本函数的数学方程式和核算来完成核算吞吐量。此类示例包含目标盯梢和辨认、猜测建模以及一些挑选操作。在这种新的驱动趋势之下,VPX 处理器在供给朴实用于线性代数的专用向量 SIMD 浮点核算引擎方面别出心裁。该引擎硬件加速了线性功用,例如除法、SQRT、1/SQRT、log2(x)、2^x、正弦、余弦和横竖切,并在 SIMD 向量中予以履行,然后供给了十分高的功用。
凭仗四维度并行处理功用,DesignWare ARC VPX5 处理器 IP 可满意高吞吐量运用对浮点和线性代数处理的需求。与具有相似架构的其他 DSP 处理器比较,该计划供给了业界抢先的功用指标 – 例如,装备最高的 VPX5 每周期可供给 512 次半精度浮点运算1.5GHz 运转,相当于 768 GFLOP。此外,ARC VPX5 依据线性代数运算的运用情况,每周期可供给 16 次数学浮点核算。关于机器学习核算算法中运用的 8 位整数数据,VPX5 每周期最多则可供给 512 个 MAC。 DesignWare ARC metaWare 开发东西现已可支撑VPX5处理器,该东西供给了完好的编译器、调试和仿真渠道。这使开发人员能够快速高效地将 C 代码算法编译到 VPX5 内核中的处理引擎。循环等效仿真渠道让开发人员能够自在评价循环计数功用,并查看要害算法和程序的最佳功用。DesignWare ARC metaWare 开发东西除了供给 DSP 库之外,还供给线性代数和机器学习揣度 (MLI) 库。这使得开发人员能够轻松地经过 API 接口将代码移植到数据库中,并很快到达最佳功用。在MLI 算法上则供给了各种依据神经网络的核算组件,以完成高功用软件 AI 核算。
DesignWare ARC VPX5 处理器 IP 是新一代 DSP,用于满意处理密集型运用的数据核算需求。浮点、AI 和线性代数核算算法的四个并行处理维度使 DesignWare ARC VPX5 处理器能够为轿车 ADAS 传感器节点(RADAR 和 LiDAR)、5G 新无线电 (NR) 通讯基带调制解调器、动力体系、引擎办理、机器人技能、马达操控和 5G 轿车通讯 (5G C-V2X) 等运用供给超高功用。VPX5 凭仗职业抢先的 512 FLOP/周期和针对线性代数的共同 16 数学 FLOP/周期,为体系开发人员供给了功用满意新一代高功用核算算法需求的 DSP。结合具有 DSP 和数学库的 ARC metaWare 开发东西,开发人员能够快速移植 C 代码算法并取得最佳功用,以加速产品上市时刻。 作者:Synopsys ARC 处理器产品营销司理 Graham Wilson