英文原文:A Journey Through the CPU Pipeline
作为程序员,CPU 在咱们的作业中扮演了中心人物,因而了解处理器内部的作业方法对程序员来说不无裨益。
CPU 是怎么作业的呢?一条指令履行需求多长时刻?当咱们谈论某个新款处理器具有 12 级流水线仍是 18 级流水线,乃至是更深的 31 级流水线时,这到些都意味着什么呢?
使用程序一般会将 CPU 看作是黑盒子。程序中的指令依照次序顺次进入 CPU,履行完之后再按次序顺次从 CPU 中出来,而内部究竟产生了什么,咱们一般并不了解。
对咱们程序员来说,尤其是对做程序功用调优作业的程序员来说,学习 CPU 内部的细节十分必要。不然,假如你不知道 CPU 的内部结构,那怎么才干针对 CPU 做功用优化?
本文所重视的便是专门针对 X86 处理器流水线的作业原理。
你需求把握的准备常识
首要,阅览本文你需求了解编程,最好了解一点汇编语言。假如你还不知道指令指针(instruction pointer)是什么,那么本文对你来说或许有些难。你需求知道什么是寄存器,指令和缓存,假如不明白它们是什么,你需求赶快查找材料了解一下。
第二,CPU 的作业原理是一个十分庞大和杂乱的论题,本文只是是仓促一瞥,很难以用一篇文章翔实叙说。假如我有什么遗漏,请经过谈论告诉我。
第三,我只是重视英特尔处理器及其 X86 架构。当然除了 X86,还有许多其他架构的处理器。尽管 AMD 公司引进了许多新特性到 X86 架构,可是 X86 架构是 Intel 公司发明,并且发明了 X86 指令集,其间绝大多数特性是由 Intel 引进的。所以为了坚持叙说的简略和一致性,我仅重视 Intel 的处理器。
终究,当你读到这篇文章时,它现已是“过期”的了。更新款的处理器现已规划出来,其间一些会在未来几个月之内发布。我很快乐技能能如此快速的开展,我期望有一天一切这些技能都会过期,发明出具有更惊人核算才干的 CPU.
处理器流水线根底
从一个十分广的视点来说,X86 处理器架构在近 35 年来并没有改动太多。尽管 X86 架构被附加了许多新功用,可是开端的规划(包括简直一切开端的指令集)依然底子上是完好保存的,即便在最新的处理器上依然被支撑。
开端的 8086 处理器支撑 14 个寄存器,这些寄存器在现在最新的处理器中依然存在。这 14 个寄存器中,有 4 个是通用寄存器:AX,BX,CX 和 DX;有 4 个是段寄存器,段寄存器用来辅佐指针的完结:代码段(CS),数据段(DS),扩展段(ES)和仓库段(SS);有 4 个是索引寄存器,用来指向内存地址:源引证(SI),意图引证(DI),基指针(BP),栈指针(SP);有 1 个寄存器包括状况位;终究是最重要的寄存器:指令指针(IP)。
指令指针寄存器是一个具有特别功用的指针。指令指针的功用是指向行将运转的下一条指令。
一切的 X86 处理器都依照相同的形式运转。首要,依据指令指针指向的地址获得下一条行将运转的指令并解析该指令(译码)。在译码完结后,会有一个指令的履行阶段。有些指令用来从内存读取数据或许向内存写数据,有些指令用来履行核算或许比较等作业。当指令履行完结后,这条指令会经过退出(retire)阶段并将指令指针修正为下一条指令。
译码,履行和退出三级流水线组成了 X86 处理器指令履行的底子形式。从开端的 8086 处理器到最新的酷睿 i7 处理器都底子遵从了这样的进程。尽管更新的处理器增加了更多的流水级,但底子的形式没有改动。
35 年来产生了什么改动
相较于如今的规范,开端的处理器规划显得过分简略。开端的 8086 处理器的履行进程可以简述为从当时指令指针获得指令,经过译码,履行终究退出,然后持续从指令指针指向的下一条指令处获得指令。
新的处理器增加了新的功用,有些增加了新的指令,有些增加了新的寄存器。我将首要重视和本文主题有联系的改动,这些改动影响了 CPU 指令履行的流程。其他的一些改动比方虚拟内存或许并行处理尽管都很有意义并且风趣,可是并不在本文主题的范围内。
指令缓存在 1982 年被加入到处理器中。经过指令缓存,处理器可以一次性从内存读取更多指令并放在指令缓存中,而不必每条指令都从内存中取。指令缓存仅有几个字节巨细,只能包容数条指令,可是由于消除了之后每次取指往复内存和处理器的时刻,极大的进步的功率
1985 年的 386 处理器引进了数据缓存,并且扩展了指令缓存的规划。数据访存恳求经过一次性读取更多的数据放在数据缓存中,然后提高了功用。并且,数据缓存和指令缓存都从几个字节扩大到几千字节。
19巴久年推出的 i486 处理器引进了五级流水线。这时,在 CPU 中不再仅运转一条指令,每一级流水线在同一时刻都运转着不同的指令。这个规划使得 I486 比同频率的 386 处理器功用提高了不止一倍。五级流水线中的取指阶段将指令从指令缓存中取出(i486 中的指令缓存为 8KB);第二级为译码阶段,将取出的指令翻译为详细的功用操作;第三级为转址阶段,用来将内存地址和偏移进行转化;第四级为履行阶段,指令在该阶段真实履行运算;第五级为退出阶段,运算的成果被写回寄存器或许内存。由于处理器一起运转了多条指令,大大提高了程序运转的功用。
1993 年 Intel 推出了飞跃(Pentium)处理器。由于诉讼问题,Intel 无法持续沿袭本来的数字编号。因而,用飞跃代替了 586 作为新款处理器的代号。飞跃处理器相对 i486 处理器对流水线做出了更多修正。飞跃处理器架构增加了第二条独立的超标量流水线。干流水线作业方法类似于 i486,第二条流水线则并行的运转一些较简略的指令,比方说定点算术,并且该流水线能更快的进行该运算。
1995 年 Intel 推出了飞跃 Pro (Pentium Pro)处理器。和之前的处理器比较,飞跃 Pro 采用了彻底不同的规划。该处理器采用了许多新特性以进步功用,包括乱序(Out-of-Order, OOO)履行的部件以及猜想履行。流水线扩展到了 12 级,并且引进了“超标量流水线”的概念,使得许多指令可以被一起处理。咱们稍后将翔实的介绍乱序履行的部件。
在 1995-2002 年之间,乱序履行部件经过了数次严重改善。处理器中加入了更多的寄存器;单指令多数据(Single Instruction Multiple Data, or SIMD)的引进使得一条指令可以进行多组数据运算;现有的缓存变得更大并且引进了新的缓存;有些流水级被拆分红更多流水级,有些流水级被兼并,使得愈加合适实践的使用。这些改动对全体功用的提高有重要作用,但它们都没有从底子影响数据在处理器中的活动方法。
2002 年发布的飞跃 4 处理器引进了超线程技能。乱序履行部件的规划使得指令被履行的速度比处理器可以供给指令的速度更快。因而关于大部分使用,CPU 的乱序履行部件在大部分时刻处于闲暇状况,乃至在高负载的情况下也不能充沛利用。为了让指令流能充沛的流入乱序履行部件,Intel 加入了第二套前端部件(译注:在处理器结构中,前端是指取指,译码,寄存器重命名等模块,经过前端部件的处理后,指令等候发射进入乱序履行部件)。尽管实践上只要一个乱序履行部件,但关于操作系统来说,它能看到两个处理器。前端部件包括两组相同功用的 X86 寄存器,两个指令译码器依据两个指令指针指向的地址别离处理。一切的指令被一个同享的乱序履行部件履行,但对使用程序来说并不知情。当乱序履行部件履行完结,像之前相同退出流水线后,终究成果回来虚拟的两个处理器。
2006 年 Intel 发布了酷睿(Core)微架构。为了品牌效应,它被称做酷睿2(二总比一好)。令人惊奇的是,处理器频率不升反降,并且超线程也被去掉了。经过下降时钟频率,每一级流水线可以做更多作业。乱序履行部件也被扩展的更宽。各种不同的缓存和行列都相应做的更大。并且处理器被从头规划,以习惯双核和四核的同享缓存结构。
2008 年,Intel 开端用酷睿 i3, i5, i7 的方法来命名新的处理器。新处理器从头引进了超线程。这三个系列的处理器首要差异在于内部缓存巨细不同。
未来的处理器:Intel 的下一代微结构被称为 Haswell.Haswell 据称将于 2013 年发布。现在已知的文档阐明它将具有 14 级流水级的乱序履行部件,所以它依然遵从从飞跃 Pro 以来的底子规划思路。
那么,流水线究竟是什么?乱序履行部件是什么?他们怎么提高了处理器的功用呢?
CPU 指令流水线
依据之前描绘的根底,指令进入流水线,经过流水线处理,从流水线出来的进程,关于咱们程序员来说,是比较直观的。
I486 具有五级流水线。别离是:取指(Fetch),译码(D1, main decode),转址(D2, translate),履行(EX, execute),写回(WB)。某个指令可以在流水线的任何一级。

可是这样的流水线有一个显着的缺点。关于下面的指令代码,它们的功用是将两个变量的内容进行交流。
XOR a, b
XOR b, a
XOR a, b
从 8086 直到 386 处理器都没有流水线。处理器一次只能履行一条指令。再这样的架构下,上面的代码履行并不会存在问题。
可是 i486 处理器是首个具有流水线的 x86 处理器,它履行上面的代码会产生什么呢?当你一下去调查许多指令在流水线中运转,你会觉得紊乱,所以你需求回头参阅上面的图。
第一步是第一条指令进入取指阶段;然后在第二步第一条指令进入译码阶段,一起第二条指令进入取指阶段;第三步第一条指令进入转址阶段,第二条指令进入译码阶段,第三条指令进入取指阶段。可是在第四步会出现问题,第一条指令会进入履行阶段,而其他指令却不能持续向前移动。第二条 xor 指令需求第一条 xor 指令核算的成果a,可是直到第一条指令履行完结才会写回。所以流水线的其他指令就会在当时流水级等候直到第一条指令的履行和写回阶段完结。第二条指令会等候第一条指令完结才干进入流水线下一级,相同第三条指令也要等候第二条指令完结。
这个现象被称为流水线堵塞或许流水线气泡。
别的一个关于流水线的问题是有些指令履行速度快,有些指令履行速度慢。这个问题在飞跃处理器的双流水线架构下显得愈加显着。
飞跃 Pro 具有 12 级流水线。当这个数字被初次宣告后,一切的程序员都倒抽了一口气,由于他们知道超标量流水线是怎么作业的。假如 Intel 依然依照曾经的思路规划超标量流水线的话,流水线的堵塞和履行速度慢的指令会严重影响履行速度。但一起,Intel 宣告了彻底不同的流水线规划,叫做乱序履行部件(Out-of-Order core)。单从叙说上很难了解这些改动带来的优点,但 Intel 坚信这些改善是令人激动的。
让咱们来更深化的看看这个乱序履行的部件吧!
乱序履行流水线
在描绘乱序履行流水线时,往往是一图胜千言。所以咱们首要以图例进行介绍。
CPU 流水线图例
I486 处理器具有 5 级流水线。这种规划在实际国际中的其他处理器中很常见,并且功率不错。
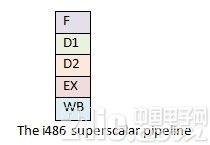
而飞跃处理器的流水线比 i486 更好。两条流水线可以并行运转,并且每条流水线可以一起有多条指令在不同流水级履行。它简直可以一起履行比 i486 多一倍的指令。
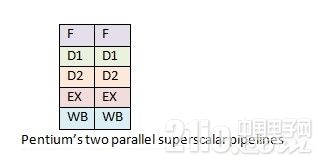
可以快速完结的指令需求等候前面履行慢的指令即便在并行流水线中也依然是一个问题。流水线依然是线性的,导致处理器面对功用瓶颈难以逾越。
乱序履行部件和之前处理器规划中的线性通路有很大不同,它增加了一些杂乱度,引进了非线性的通路。