通讯体系不可防止地要遭到各种搅扰的影响,使接纳端收到的信息与发送端宣布的信息不一致,即接纳端收到的信息发生了误码。为了下降数据通讯线路传输的误码率,一般有改进数据通讯线路传输质量和过失检测操控两种办法。过失检测操控的办法许多,本文评论在10G以太网接人体系中并行完结CRC-32编解码的办法、并行CRC算法的Unfolding算法能够完结并行CRC的核算,可是并行电路所用的资源添加到了本来的J倍。8位并行CRC算法、并行CRC-16的编码逻辑、USB技能中并行CRC算法给出的并行算法都建立在公式递推的根底上。当并行深度较小时,递推算法比较适用。而当并行深度很大的状况下(10G以太网接人体系运用64比特并行数据通路),递推进程就显得过于烦琐而缺少实用性。为此,本文提出了矩阵法、代入法和流水线法等三种算法,处理了深度并行状况下CRC算法的完结问题。运用本文提出的算法,能够得出64比特并行CRC核算的逻辑表达式,并用于10G以太网接入体系的规划。设M/(x)为信息多项式,G(x)为生成多项式。一般的CRC编码办法是:先将信息码多项式左移r位,即M(x)·xr,然后作模2除法
(M(x)· x r)/G(x)=Q(x)+R(x)/G(x) (1)
所得到的月(x)便是CRC校验码。以二进制码0x9595H的CRC-32编码为例: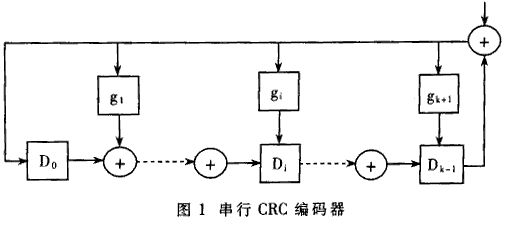
· 将信息码左移32比特变成0x959500000000H,记为m。
·CRC-32G的生成多项G(x)=x32+x26+x23+x22+x16+x12+xll+x10+x8+x7+x5+x4+x2+x+1,转换成16进制码为g=0x104C01DB7H。用m除以g(模2除法),所得余数0x3738F30BH便是0x9595H的CRC-32码。完结0x9595H的根本CRC-32编码的Matlab程序如下:
g(33:-1:1)=[1,0 0 0 0 0 1 0 0,1 1 0 0 0 0 0 1,0 0 0 1 1 1 0 1,1 0 1 1 0 1 1 1];
a(48:-1:1)=[1 0 0 1 0 1 0 1,1 0 0 1 0 1 0 1,0 0 0 0 0 0 0 0,0 0 0 0 0 0 0 0,0 0 0 0 0 0 0 0,0 0 0 0 0 0 0 0];
for i=48:-1:33,
if a(i)= =1
a(i:-1:i-32)=xor(a(i:-1:i-32),i(33:-1:1));
end
end
crc=a(32:-1:1)
假如想用以上CRC-32程序核算其他长为L的序列的根本CRC-32码,只需将数组α的上界和for循环中i的初始值改为32+L,并用该序列替代数组。开端的序列1001010110010101即可。用数字电路完结的串行CRC编码器如图1所示。图1中每个矩形表明D触发器。gi的取值规划是1或许0。取1时表明通路,取0时表明断路。进行根本CRC-32编码时,每个D触发器初始状况为0,从数据端串行输入二进制的信息码。信息码输入完毕后,D触发器中锁存的数值便是信息码的根本CRC-32编码。此电路适用于信息码长为恣意值的状况。在某些信息体系中以根本CRC发生算法为根底附加了新的规则。例如IEEE802.3协议规则,以太网的FES(帧校验序列)域以CRC-32为根底,并且在编码时首要将信息码的开始4个字节取反码,对意图地址、源地址、长度/类型域、数据域、PAD域求出根本CRC-32码之后再将成果取反,终究的成果才是FCS。同上述进程等价的另一种完结办法是将图1中一切D触发器的初值置1,这样成果不用取反。为使电路规划者验证其FCS编码正确,IEEE802.3还给出了一个样本,即:将序列0xBED723476B8FB3145EFB3559H重复126次,终究得到的FCS值应该为0x94D254ACH。10G以太网是IEEE802.3ae作业组提出的主张。它坚持了曾经以太网的帧结构,可是线速度到达了10Gbps的量级。为了下降10G以太网接入体系的功耗并到达芯片加工工艺的要求,有必要选用并行数据通路。为核算FCS需求研讨并行CRC算法。所规划的10G以太网接入体系选用64比特并行数据通路,因此本文首要评论64比特并行CRC-32的完结办法。本文共介绍三种完结办法,其间矩阵法和代入法是根据组合逻辑的直接完结办法,第三种办法是根据流水线的完结办法。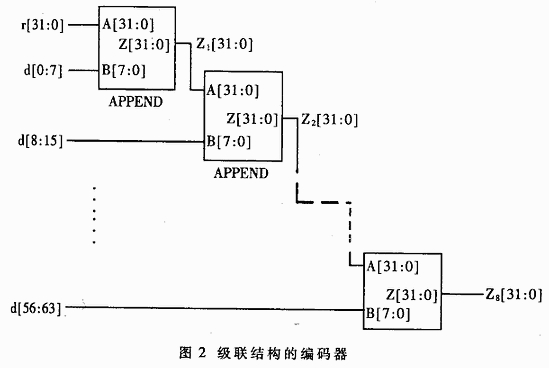
1 矩阵法
记图1中的32个D触发器的输出从右至左依次为d31,d30,…,d0。信息码元的输入端为i。令D=[d0d1…d31]T表明编码器当时所在的状况,I=[i63i62…i0]表明第1至第64个时钟的信息码元输入,向量Dˊ=[d0ˊd1ˊ,…d31ˊ] T表明编码器的下一个状况,D(64)表明64个时钟之后CRC编码器所在的状况。则规划64位并行CRC逻辑编码器,便是找出函数联系D(64)=f(D,I)。
do=d31+i63
d1=d0+d31+i63
d2=d1+d31+i63
d3=d2
…
d31=d30
写成行列式,有D=TD+Si63
其间:

2个时钟之后编码器的状况为:
D=TD+Si62=T)TD+Si63)+Si62=T2D+TSi63+Si62
依此类推,有:
D(64)=T64D+T63Si63+T62Si62+…+TSi1+Si0 (2)
这儿一切矩阵运算和代数运算中的加号的语义都是模2加法。为了。规划64位并行CRC电路,有必要核算(2)式中的大规划矩阵乘法T64、T63S等。
2 代入法
矩阵法的长处在于其直观性。可是需求做大规划乘法运算。下面评论的代入法能够得到与矩阵法相同的成果。一起能够防止大规划矩阵乘法运算。设8比特并行CRC-32电路的初始状况是d31,d30,…,d0,输入是i7,i6,…,j0,输出是z31,Z30,…,z0。运用前面所述的矩阵法,能够得出8比特并行CRC-32编码器的组合逻辑表达式。如表1所示。
即:
z31=d23+d29+i5;
z30=d22+d31+i7+d28+i4
…
z0=d24+d30+i6+i0
表1 8位行CRC逻辑表
| z0 | d24,d30,i6,i0 |
| z1 | d25,d31,i7,i1,d24,d30,i6,i0 |
| z2 | d26,i2,d25,d31,i7,i1,d24,d30,i6,i0 |
| z3 | d27,i3,d26,i2,d25,d31,i7,i1 |
| z4 | d28,i4,d27,i3,d26,i2,d24,d30,i6,i0 |
| z5 | d29,i5,d28,i4,d27,i3,d25,d31,i7,i1,d24,d30,i6,i0 |
| z6 | d30,i6,d29,i5,d28,i4,d26,i2,d25,d31,i7,i1 |
| z7 | d31,i7,d29,i5,d27,i3,d26,i2,d24,i0 |
| z8 | d0,d28,i4,d27,i3,d25,i1,d24,i0 |
| z9 | d1,d29,i5,d28,i4,d26,i2,d25,i1 |
| z10 | d2,d29,i5,d27,i3,d26,i2,d24,i0 |
| z11 | d3,d28,i4,d27,i3,d25,i1,d24,i0 |
| z12 | d4,d29,i5,d28,i4,d26,i2,d25,i1,d24,d30,i6,i0 |
| z13 | d5,d30,i6,d29,i5,d27,i3,d26,i2,d25,d31,i7,i1 |
| z14 | d6,d31,i7,d30,i6,d28,i4,d27,i3,d26,i2 |
| z15 | d7,d31,i7,d29,i5,d28,i4,d27,i3 |
| z16 | d8,d29,i5,d28,i4,d24,i0 |
| z17 | d9,d30,i6,d29,i5,d25,i1 |
| z18 | d10,d31,i7,d30,i6,d26,i2 |
| z19 | d11,d31,i7,d27,i3 |
| z20 | d12,d28,i4 |
| z21 | d13,d29,i5 |
| z22 | d14,d24,i0 |
| z23 | d15,d25,i1,d24,d30,i6,i0 |
| z24 | d16,d26,i2,d25,d31,i7,i1 |
| z25 | d17,d27,i3,d26,i2 |
| z26 | d18,d28,i4,d27,i3,d24,d30,i6,i0 |
| z27 | d19,d27,i5,d28,i4,d25,d31,i7,i1 |
| z28 | d20,d30,i6,d29,i5,d26,i2 |
| z29 | d21,d31,i7,d30,i6,d27,i3 |
| z30 | d22,d31,i7,d28,i4 |
| z31 | d23,d29,i5 |
下文用+表明按位模2和运算,{,}表明链接运算。从CRC的(1)式很简单得出以下算法:
算法1:已知序列N的CRC-32为A[31:0],序列B(=[b7,b6,…,b0])的CRC-32码为Y[31:0]。序列A[31:24]的CRC-32为X[31:0],则延拓序列{N,B}的CRC-32码为{Y[31:24]+X[31:24]+A[23:16],Y[23:16]+X[23:16]+A[15:8]+A[7:0],Y[7:0]+X[7:0]}。
推论:已知序列N的CRC-32为A[31:0],序列A[31:24]的CRC-32为X[31:0],则补0延拓序列{N,O}的CRC-32码为{X[31:24]+A[23:16]+A[15:8],X[15:8]+A[7:0],X[7:0]}。
运用上述算法结构APPEND模块,其端口A和B别离表明前导序列的CRC和延拓的8比特序列,则其输出端口Z为拓宽之后序列的CRC。图2运用APPEND模块结构了级联结构的64比特并行CRC编码器。这种级联结构的编码器规划比较简单。其间间节点:
Z1(n)=f(r,d[0:7] n[31,0]
Z2(n)=f(Z1,d[8:15])=f(f(r,d[0:7]),d{8:15])
… (3)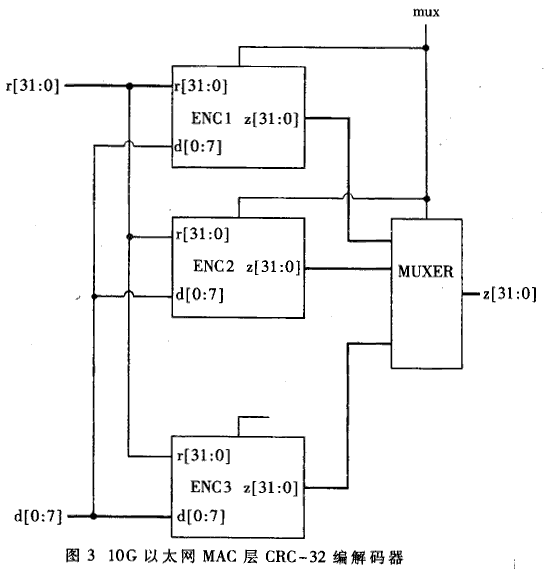
明显(3)还能够进一步化简。冗余的逻辑使得这种级联结构占用芯片面积大,且只能用于低速场合。对(3)进一步化简,能够得到Z2的最简异或表达式。同理能够得到Z3…Z8的表达式。Zl,Z2,…,Z8别离对应8比特、16比特、……、64比特的并行CRC运算表达式。详细表达式限于篇幅不在这儿给出。Z8中最长的异或运算表达式有52项参与运算,假如运用4-异或门则只需求用三级,即能在一般CMOS工艺的一级传输延迟时间之内完结。当用于以太网接入体系时,由于以太网帧不一定完毕在64比特鸿沟,因此编码器应该有一起核算8、16、24、……、64比特并行编码的才能。详细电路如图3。由于一般状况下很多用到64比特并行编码,因此平常使能信号mux使其他7个编码模块不作业以下降功耗。在帧尾部根据详细状况运用这7个模块进行剩下字节的编码。
3 流水线法
矩阵法和代入法本质上都是规划直接并行编码电路的办法,二者的终究作用是相同的。直接并行完结的CRC编码电路操控逻辑比较简单,可是需求进行杂乱的组合逻辑运算。为了在更高频率下进行并行CRC编码,能够进一步用流水线的办法简化编码逻辑,所支付的价值是整个帧的处理延迟了8个时钟周期。图4给出了CRC编码的流水线完结。将并行输入的64比特分红7个字节,别离用D0、D1、……、D7表明。P模块(P0~P7)核算形如Di,O,O,O,O,O,O,O,Di的序列的CRC,其间Diˊ,是Di方位上的上一次输入。Diˊ的CRC码由端口R[31:0]输入,Di由端口D[7:0]输入,成果由Z[31:0]端口输出。
C模块(C1~C7)的输入是D0,O,O,O,O,O,O,O,D0和D1ˊ,O,O,O,O,O,O,O,D1的CRC(别离由端口R1和R2输入),输出是D0ˊ,D1ˊ,O,O,O,O,O,O,D0,D1 CRC。求P的逻辑表达式时,重复运用算法1的推论,能够求出Diˊ,O,O,O,O,O,O,Di的CRC码,再运用算法1,就能够求出Diˊ,O,O,O,O,O,O,O,Di的CRC码。直接运用算法1能够求出C模块的逻辑表达式。P模块和C模块进行异或运算的长度远小于直接并行CRC电路中的ENC8模块,因此更有利于在高速电路中运用。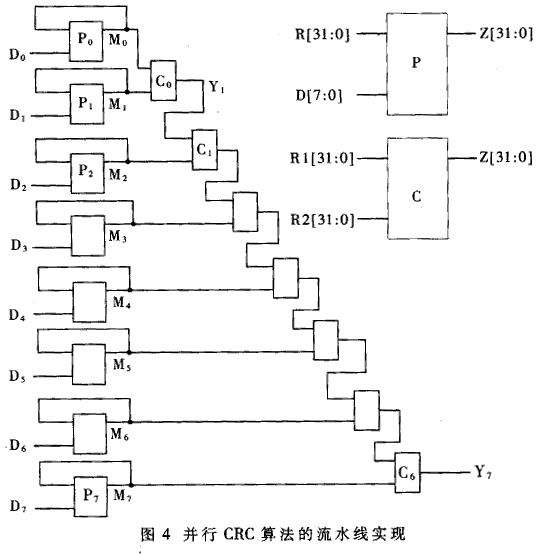
4 10G以太网接入体系中的CRC编解码器规划
10G以太网接人体系所需接口速率高达10Gbps以上。从下降体系功耗和芯片制作本钱的视点考虑期望接口能作业在200MHz以下。选用并行化规划尽管能够下降体系时钟频率,但也从以下两方面添加了规划难度。首要,数据通路的并行程度越高,对它的操控就越杂乱。体系选用8字节并行数据通路,则发送的以太网帧可能在8个并行字节中的恣意一个方位上完毕,操控逻辑的规划就有必要考虑一切这些可能性并逐个做出相应的处理。其次,体系中的CRC编码器、扰码器等的规划须选用并行算法。为了满意IEEE802.3协议对以太网帧CRC编码的要求,实践的编解码器模块还需求能对输入输出信号进行恣意字节数的求反运算。考虑到10G接入体系的杂乱性,该模块功用应该高度集成化,以便用宏信号端口对其进行操作。在对收到的以太网帧进行校验时,没必要先核算不包含FCS域的序列的CRC编码(成果取反)再与FCS域做比照。在编码正确且没有误码的状况下,对整个以太网帧(包含FCS域)进行成果不取反的CRC编码的成果应该为序列0xC704DD7BH。选用这种判别办法,无需在帧的完毕前中止核算CRC编码,因此能够大大简化电路规划。
5 CRC编码器的完结
本文提出的各种算法的硬件完结现已通过了FPGA验证,并被运用到详细芯片。运用Xilinx公司的Virtex2系列FPGA中的XC2V1000别离仿真了选用上述代入法和流水线法规划的CRC编码器和解码器,验证了规划办法的正确性。在归纳考虑逻辑杂乱度、所占用的芯片面积和工艺要求后,终究在所规划的10G以太网接入芯片中,选用了代入法规划的CRC编码器和解码器。
10G以太网接入体系中需求选用并行CRC编码器。本文提出了根据组合逻辑的直接完结和根据流水线的完结办法。其间直接完结的办法又分为矩阵法和代入法两种。通过详细推导发现直接完结的编码器能够满意延时要求,因此被本体系所选用。而根据流水线的规划由于其延时较小,能够用于更高速的场合。本文提出的三种并行化规划办法现已通过了硬件验证。这些规划思维相同适用于其他线性移位寄存器,如扰码器的规划。