嵌入式体系往往履行比较单一的使命,针对某种特定运用而专门规划,但现在在嵌入式体系中选用的微处理器绝大部分都是通用嵌入式微处理器,其通用的指令集面临千差万别的嵌入式运用时暴露出专用性差,履行功率低的缺点。另一个问题是,现在运用的嵌入式微处理器都是硬核,功用模块和指令集都是固定的,当运用发生较大改变时,很难经过对微处理器功用模块和指令集进行扩展来习惯改变,往往只能换用一款新的微处理器,乃至从头规划整个嵌入式体系的硬件和软件,浪费了很多的时刻和金钱。因而,怎么进步指令集的针对性,进步指令的履行功率以及怎么增强嵌入式微处理器的扩展才干成了困扰嵌入式体系开发人员的两个难题。
1.ASIP和FPGA
ASIP的提出是微处理器规划理念的一项严重立异。ASIP(Application-Specific InstrucTIon set Processor)即专用指令集处理器,它相对传统微处理器最大的特色便是其指令集针对特定运用专门规划,一条指令就能够完结该种运用常做的一系列运算,例如一些常用算法,这样就极大的进步了指令的履行功率,往往若干条一般指令几十个时钟周期完结的操作用一条专用指令几个时钟周期就完结了。
选用ASIP理念规划微处理器能够在很大程度上处理上一节说到的指令集专用性差,指令履行功率低的问题,但这是要支付价值的,由于这些专用指令一般需求专门硬件电路支撑才干完结。
ASIP用传统的集成电路技能完结是不现实的,集成电路规划杂乱,开发周期长,定型后无法进行扩大,这样每遇到一种新运用,就得从头规划一款专用芯片,成本是不行承受的,这在一个时期内约束了ASIP的开展,直到FPGA(Field Programmable Gate Array,现场可编程门阵列)的呈现,才为ASIP的完结供给了或许。
FPGA内部包含可装备逻辑模块CLB(Configurable Logic Block),能够便利的用硬件描绘言语进行开发。硬件描绘言语描绘要完结的电路的功用,经过编译、归纳构成装备FPGA芯片的字节码文件,经下载后就能够在CLB内部构成一块模仿的专用电路,功用与实践电路彻底相同,这样就能够完结对ASIP中专用指令的支撑。用FPGA完结ASIP,相对传统的集成电路来说,最大的长处是扩展性好,遇到新运用时,彻底能够对一个较小的软核原型进行扩大,经过增加新模块,完结对针对该运用规划的专用指令的支撑,敏捷完结新的规划。此外,FPGA还有规划便利,开发周期短,可重复编程等长处。
依据以上评论,能够看出ASIP+FPGA规划形式能够从很大程度上处理导言中说到的两个难题。为了进行更深化的研讨,咱们对该规划形式进行了测验,用VHDL硬件描绘言语在FPGA上完结了一个8位微处理器软核(以下称为WolfMCU),并为该微处理器完结了6条专用指令,每一条专用指令都由FPGA芯片中的专用电路支撑。
2.WolfMCU体系结构规划
微处理器常用的体系结构有两种――冯氏结构和哈佛结构。在冯氏结构中,指令和数据运用同一个存储器,经由同一个总线传输,而在哈佛结构中,运用两个独立的存储器,别离存储指令和数据,而且运用两条独立的总线,别离作为CPU与每个存储器之间的专用通讯途径,这样就确保了体系具有较高的可靠性,嵌入式体系寻求的便是高可靠性,因而哈佛结构的嵌入式微处理器在嵌入式体系中被广泛运用,本文介绍的WolfMCU也选用了哈佛结构。
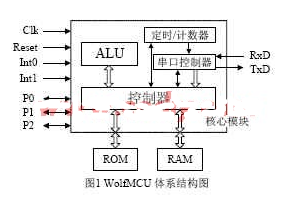
2.1 WolfMCU的体系结构
WolfMCU由6个模块组成,包含操控器、运算器、定时器/计数器、存储器、串口通讯操控器和并行通讯接口,如图1所示。
操控器是WolfMCU的大脑,在它的操控下,各模块和谐有序的作业。操控器包含四个模块――译码模块、有限状况机模块、存储器操控模块和中止处理模块。译码模块对指令进行译码,发生相应的操控信号。有限状况机模块操控WolfMCU在不同作业状况之间进行转化。WolfMCU共有四种作业状况:STARTUP、FETCH、EXEC1和EXEC2。STARTUP是WolfMCU加电后的初始状况,WolfMCU复位后也回到这个状况;FETCH是取指令状况,EXEC1和EXEC2是指令履行状况,处理器依据译码成果在这两个状况下取操作数进行核算。存储器操控模块在译码模块发生的操控信号的作用下取指令和操作数,并送往正确的当地。中止处理模块接纳外部中止并进行处理,WolfMCU共有两个中止源:Int0和Int0。
运算器在操控器的操控下完结指定的运算。WolfMCU的运算器支撑8位数据的加、减、乘、与、或、非等根本运算,还支撑十进制调整、乘加、乘减、平方后加、平方后减、取绝对值等特别运算,这些特别运算由专用指令完结,由专用电路支撑。
体系内不同部件的作业时钟或许与体系时钟不一致,比方串口操控器,它的作业时钟依据不同波特率而不同,这就要求体系供给相应的时钟,以确保其正常作业,定时器/计数器能够完结对体系时钟进行分频以遍供给给相应的部件运用。
存储器包含100字节的ROM、和100字节RAM(ROM和RAM都能够扩大容量)。ROM里寄存要履行的程序,RAM中寄存运算进程中发生的数据。ROM中的程序可由上位PC机经过串口写入。

2.2 试验验证
2.1节介绍了WolfMCU的体系结构,接下来以一个小程序为例剖析WolfMCU作业的具体进程。
该程序完结加法的操作,图2所示是该程序的三条指令及其在软核ROM中的存储状况,第一条指令NOP是空操作指令,第二条指令把当即数56H送到累加器Acc中去,第三条指令给累加器Acc加上当即数5FH,成果保存在累加器Acc中,终究Acc中的成果是56H+5FH=B5H。
第一条空操作指令比较简略,体系不进行任何操作,仅仅状况由初始状况(STARTUP),变为取指令状况(FETCH),PC指针加1,指向下一条指令MOV。
在第二个指令周期里,体系处于FETCH状况,存储器操控模块从ROM的001地址处读出8位数据(01110100),把它送往译码模块译码,译码模块依据指令码(01110100)识别出这是MOV_Acc_imm指令(把当即数送往累加器Acc),知道该指令需求有一个操作数,所以把PC指针加1,并把体系下一个状况置为EXEC1,为下一个周期取该指令的操作数做好预备。
第三个指令周期开端,存储器操控模块取出操作数56H(01010110),一起译码模块宣布操控信号,指出这是从ROM输入的数据(由于体系处在EXEC1状况),方针寄存器是累加器Acc,然后PC指针加1,置体系下一个状况为FETCH,为取下一条指令做好预备。在这个时钟周期内,存储器操控模块现已把56H送到累加器Acc中了。
ADD指令的履行进程和MOV指令相似,这儿就不做胪陈,仅有不同的是ADD指令履行进程中经过了两次译码,第一次和MOV相同,第2次是在操控器把加法操控信号发送到ALU之后,ALU还要识别出这条加法指令是要把当即数和累加器中的操作数相加,这样才干终究完结操作。
至此,这段程序履行结束,正确输出成果B5H。下载到Memec V2mb1000 FPGA开发板上的运转,经过七段数码管显现的成果,如图3所示:

3.WolfMCU指令集规划
关于桌面核算机体系来说,由于要面临不同的运用,指令集功用越强壮越好,通用性越强越好。但关于嵌入式体系来说,由于只面临某种特定的运用,所以在满意运用需求的条件之下指令集越小越好,指令越专用,功率越高越好。
归纳考虑了指令集尺度和专用性,WolfMCU的指令集共有22条指令,包含16条通用指令和6条专用指令。16条通用指令都是最常用的指令,今后再规划其他专用指令集微处理器时能够在此基础上进行扩大,通用指令包含数据传送指令,算术运算指令,逻辑运算指令,操控搬运指令等四类,在这不再胪陈。6条专用指令,如表1所列,增强了WolfMCU的运算才干。
除了指令的功用之外,指令的寻址方法也是指令集规划的一个重要方面, WolfMCU共支撑4种寻址方法:当即寻址、寄存器寻址、直接寻址、寄存器直接寻址。

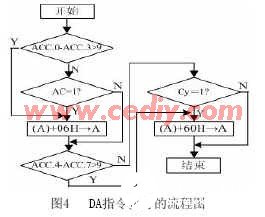
ASIP的规划,要点和难点是专用指令的完结,下面以DA指令(十进制调整)为例介绍一下专用指令的完结。这条指令跟在加法指令后,对累加器Acc中8位成果进行调整,使它调整为紧缩得BCD码的数,以完结十进制加法运算功用。DA指令履行的流程图如图4所示,具体代码不再具体介绍,这段代码编译后构成一个模块连接在WolfMCU的操控器上,下载到FPGA芯片之后,相当于有一块专用电路支撑DA指令,操控器只要把ACC中的内容发送到这个模块,就能够回来调整后的成果,大大进步了该指令的履行功率。用下面的程序测验DA指令的履行作用:

程序履行十进制的8和9相加,在WolfMCU软核上履行后,输出0107(图5所示为经过七段数码管显现成果),阐明DA指令履行正确。
其他专用指令的完结方法和DA指令相似,也是作为一个模块连接在WolfMCU软核之上,调用这些指令时,只需把操作数传送给这些模块。
4.专用指令完结与一般指令完结的功能比照
上表中列出的乘加、乘减等指令也像十进制调整指令相同,由于有专门的电路支撑这些指令,因而能够在几个时钟周期内敏捷输出成果。

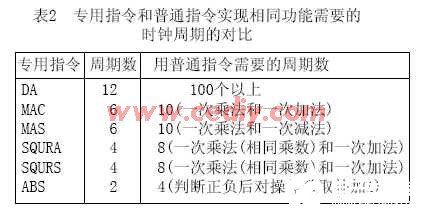
上面说到的十进制调整指令,首要需求判别累加器的低四位是否大于9,辅佐进位标志位是否为1,二者满意其一就给低四位加上06H,然后判别高四位,若高四位或进位标志为1,则给高四位加上60H,假如运用一般指令编程完结,至少需求上百个时钟周期,而选用专用指令之后,只需求12个时钟周期,表2列出了选用专用指令和一般指令时需求的时钟周期的比照。
由表2能够看出,选用专用指令后,所需时钟周期数至少降低了40%,为完结这些专用指令支付的硬件价值仍是值得的。
5.总结
本文介绍了一种进步嵌入式微处理器指令履行功率和扩展性的规划思路–ASIP+FPGA,并对这种思路进行了测验,完结了一个8位的微处理器软核,为这个软核规划了16条通用指令和6条专用指令,经过与一般指令的完结开支进行比照,验证了ASIP+FPGA规划形式的优势,这个简略的8位微处理器软核能够作为规划杂乱ASIP的原型,能够很简单的扩展成16位、32位,也能够很便利的增加新的专用指令,满意新运用的需求。
本文作者立异点:1.提出了一种嵌入式微处理器规划形式–ASIP+FPGA形式,从体系结构和专指令集规划两方面临该规划形式进行了剖析。2.选用该规划形式,在Xilinx V2MB1000
FPGA开发板上规划并完结了一款嵌入式微处理器软核(WolfMCU),验证了该设规划形式的优势。3.WolfMCU选用模块化规划,能够便利的扩展到16位或增加新的功用模块。
责任编辑:gt