今日,面临AI如此重要的江湖位置,深度学习作为重要的一个研讨分支,简直出现在当下一切抢手的AI应用范畴,其间包含语义了解、图画辨认、语音辨认,自然语言处理等等,更有人以为当时的人工智能等同于深度学习范畴。
假如在这个人工智能的年代,作为一个有志向志向的程序员,或许学生、爱好者,不明白深度学习这个超热的论题,好像现已跟年代脱节了。
但是,深度学习对数学的要求,包含微积分、线性代数和概率论与数理统计等要求,让大部分的有志向志向青年踟蹰前行。那么问题来了,了解深度学习,究竟需不需求这些常识?关子就不卖了,标题现已阐明。
前段时刻,修改闲逛各大社区论坛,发现一篇十分适宜初学者学习的深度学习的回复帖子,用诙谐的文言和比方浅显易懂的剖析了深度学习的进程,十分浅显易懂。经过与在西门子从事人工智能范畴的杨安国教师交流,取得内容修改授权,把内容重新整理批改,内容愈加浅显易懂,期望人人都能够了解深度学习。
关于深度学习,网上的材料许多,不过形似大部分都不太适宜初学者。杨教师总结了几个原因:
1、深度学习的确需求必定的数学根底。假如不用浅显易懂地办法讲,有些读者就会有畏难的心情,因此简略过早地抛弃。
2、中国人或美国人写的书本或文章,遍及比较难一些。
深度学习所需求的数学根底并没有幻想中的那么难,只需求知道导数和相关的函数概念即可。高等数学也没学过?很好,这篇文章其实是想让文科生也能看懂,只需求学过初中数学就彻底能够。
其实不用有畏难的心情,比较推重李书福的精力,在一次电视采访中,李书福说:谁说中国人不能造轿车?造轿车有啥难的,不便是四个轮子加两排沙发嘛。当然,他这个定论有失偏颇,不过精力可嘉。
导数是什么?无非便是改动率。
比方:王小二本年卖了100头猪,上一年卖了90头,前年卖了80头。。。改动率或许添加率是什么?每年添加10头猪,多简略。这儿需求留意有个时刻变量—年。王小二卖猪的添加率是10头/年,也便是说,导数是10。
函数y=f(x)=10x+30,这儿咱们假定王小二第一年卖了30头,今后每年添加10头,x代表时刻(年),y代表猪的头数。
当然,这是添加率固定的景象,而现实日子中,许多时分,改动量也不是固定的,也便是说添加率不是稳定的。比方,函数或许是这样: y=f(x)=5×2;+30,这儿x和y仍然代表的是时刻和头数,不过添加率变了,怎样算这个添加率,咱们回头再讲。或许你爽性记住几个求导的公式也能够。
深度学习还有一个重要的数学概念:偏导数,偏导数的偏怎样了解?偏头疼的偏,仍是我不让你导,你偏要导?都不是,咱们还以王小二卖猪为例,方才咱们讲到,x变量是时刻(年),但是卖出去的猪,不但跟时刻有关啊,跟着事务的添加,王小二不只扩展了养猪场,还雇了许多职工一同养猪。所以方程式又变了:y=f(x)=5×2;+8x + 35x +30
这儿x代表面积,x代表职工数,当然x仍是时刻。
上面咱们讲了,导数其实便是改动率,那么偏导数是什么?偏导数无非便是多个变量的时分,针对某个变量的改动率。在上面的公式里,假如针对x求偏导数,也便是说,职工关于猪的添加率奉献有多大,或许说,跟着(每个)职工的添加,猪添加了多少,这儿等于35—每添加一个职工,就多卖出去35头猪。 核算偏导数的时分,其他变量都能够当作常量,这点很重要,常量的改动率为0,所以导数为0,所以就剩对35x求导数,等于35. 关于x求偏导,也是相似的。
求偏导咱们用一个符号表明:比方 y/ x就表明y对x求偏导。
废话半响,这些跟深度学习究竟有啥联系?当然有联系,深度学习是选用神经网络,用于处理线性不可分的问题。关于这一点,咱们回头再评论,咱们也能够网上搜一下相关的文章。这儿首要讲讲数学与深度学习的联系。先给咱们看几张图:
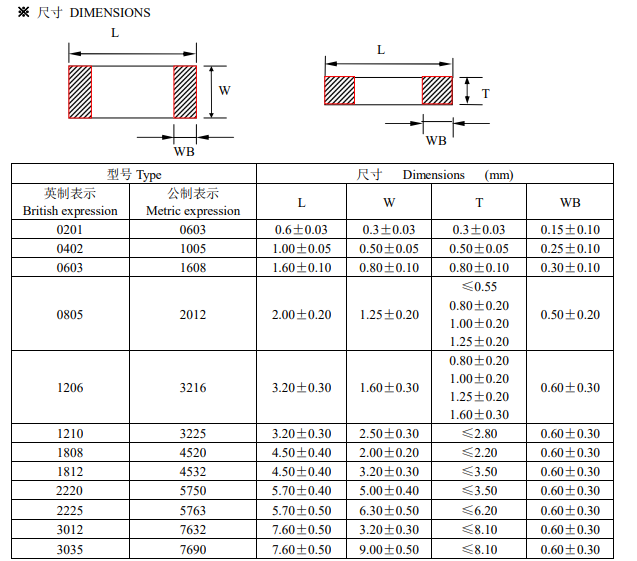
图1. 所谓深度学习,便是具有许多个隐层的神经网络。

图2.单输出的时分,怎样求偏导数

图3.多输出的时分,怎样求偏导数。
后边两张图是日本人写的关于深度学习的书,感觉写的不错,把图盗来用一下。所谓入力层,出力层,中间层,别离对应于中文的:输入层,输出层,和隐层。咱们不要被这几张图吓着,其实很简略的。再举一个比方,就以撩妹为例。男女爱情咱们大致能够分为三个阶段:
1.初恋期。相当于深度学习的输入层。他人招引你,必定是有许多要素,比方:身高,身段,脸蛋,学历,性情等等,这些都是输入层的参数,对每个人来说权重或许都不相同。
2.热恋期。咱们就让它对应于隐层吧。这个期间,两边各种磨合,柴米油盐酱醋茶。
3.稳定时。对应于输出层,是否适宜,就看磨合得咋样了。咱们都知道,磨合很重要,怎样磨合呢?便是不断学习练习和批改的进程嘛!比方女朋友喜爱草莓蛋糕,你买了蓝莓的,她的反应是negaTIve,你下次就别买了蓝莓,改草莓了。
看完这个,有些小伙或许要开端对自己女友调参了。有点不放心,所以弥补一下。撩妹和深度学习相同,既要避免欠拟合,也要避免过拟合。所谓欠拟合,对深度学习而言,便是练习得不可,数据缺乏,就比方,你撩妹经历缺乏。要做到拟合,送花当然是最基本的,还需求进步其他方面,比方,进步自身说话的诙谐感等,因为本文要点并不是撩妹,所以就不打开讲了。这儿需求提一点,欠拟合当然欠好,但过拟合就更不适宜了。过拟合跟欠拟合相反,一方面,假如过拟合,她会觉得你有陈冠希教师的潜质,更重要的是,每个人状况不相同,就像深度学习相同,练习集作用很好,但测验集不可!就撩妹而言,她会觉得你受上一任(练习集)影响很大,这是大忌!假如给她这个形象,你今后有的烦了,牢记牢记!
深度学习也是一个不断磨合的进程,刚开端界说一个规范参数(这些是经历值,就比方情人节和生日有必要送花相同),然后不断地批改,得出图1每个节点间的权重。为什么要这样磨合?试想一下,咱们假定深度学习是一个小孩,咱们怎样教他看图识字?必定得先把图片给他看,并且告知他正确的答案,需求许多图片,不断地教他,练习他,这个练习的进程,其实就相似于求解神经网络权重的进程。今后测验的时分,你只需给他图片,他就知道图里面有什么了。
所以练习集,其实便是给小孩看,带有正确答案的图片,关于深度学习而言,练习集便是用来求解神经网络的权重,最终构成模型;而测验集,便是用来验证模型的准确度。
关于现已练习好的模型,如下图所示,权重(w1,w2.。.)都已知。
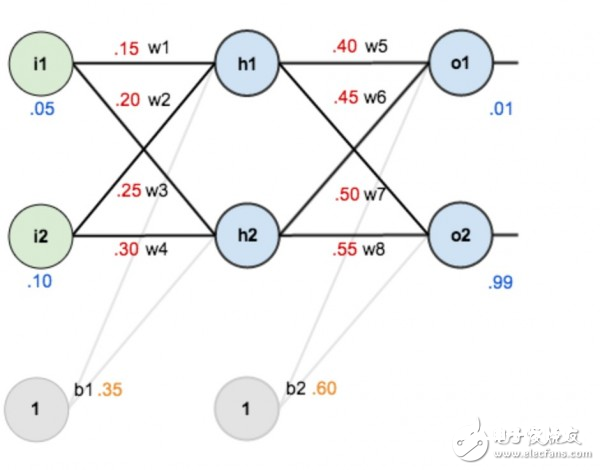
图4
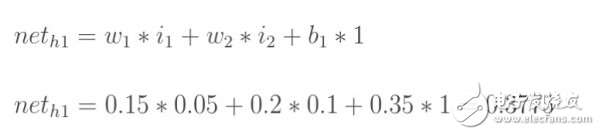
图5
咱们知道,像上面这样,从左至右简略算出来。但反过来咱们上面讲到,测验集有图片,也有预期的正确答案,要反过来求w1,w2.。..。.,怎样办?
绕了半响,总算该求偏导进场了。现在的状况是:
1.咱们假定一个神经网络现已界说好,比方有多少层,每层有多少个节点,也有默许的权重和激活函数等。输入(图画)确认的状况下,只要调整参数才干改动输出的值。怎样调整,怎样磨合?方才咱们讲到,每个参数都有一个默许值,咱们就对每个参数加上必定的数值?,然后看看成果怎样?假如参数调大,距离也变大,你懂的,那就得减小?,因为咱们的方针是要让距离变小;反之亦然。所以为了把参数调整到最佳,咱们需求了解差错对每个参数的改动率,这不便是求差错关于该参数的偏导数嘛。
2.这儿有两个点:一个是激活函数,这首要是为了让整个网络具有非线性特征,因为咱们前面也说到了,许多状况下,线性函数没办法对输入进行恰当的分类(许多状况下辨认首要是做分类),那么就要让网络学出来一个非线性函数,这儿就需求激活函数,因为它自身便是非线性的,所以让整个网络也具有非线性特征。别的,激活函数也让每个节点的输出值在一个可控的范围内,这样核算也便利。
形似这样解说仍是很不浅显,其实还能够用撩妹来打比方:女生都不喜爱白开水相同的日子,因为这是线性的,日子中当然需求一些浪漫情怀了,这个激活函数嘛,我感觉相似于日子中的小浪漫,小惊喜,是不是?共处的每个阶段,需求时不时激活一下,制作点小浪漫,小惊喜。比方,一般女生见了心爱的小杯子,瓷器之类都迈不开脚步,那就在她生日的时分送一个特别款式,要让她感动得想哭。前面讲到男人要诙谐,这是为了让她笑,恰当的时分还要让她激动得哭。一哭一笑,多整几个回合,她就离不开你了。因为你的非线性特征太强了。
当然,过为己甚,小惊喜也不是越多越好,但彻底没有就成白开水了。就比方每个layer都能够加激活函数,当然,不见得每层都要加激活函数,但彻底没有,那是不可的。
关键是怎样求偏导。图2和图3别离给了推导的办法,其实很简略,从右至左挨个求偏导就能够。相邻层的求偏导其实很简略,因为是线性的,所以偏导数其实便是参数自身嘛,就跟求解x?的偏导相似。然后把各个偏导相乘就能够了。
这儿有两个点:一个是激活函数,其实激活函数也没啥,便是为了让每个节点的输出都在0到1的区间,这样好算账嘛,所以在成果上面再做了一层映射,横竖都是1对1的。因为激活函数的存在,所以在求偏导的时分,也要把它算进去,激活函数,一般用sigmoid,也能够用Relu等。激活函数的求导其实也十分简略:
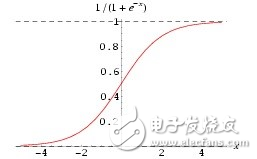
求导: f‘(x)=f(x)*[1-f(x)]
这个方面,有时刻能够翻看一下高数,假如没时刻,直接记住就行了。至于Relu,那就更简略了,便是f(x) 当x《0的时分y等于0,其他时分,y等于x。当然,你也能够界说你自己的Relu函数,比方x大于等于0的时分,y等于0.01x,也能够。
另一个是学习系数,为什么叫学习系数?方才咱们上面讲到?增量,究竟每次添加多少适宜?是不是等同于偏导数(改动率)?经历告知咱们,需求乘以一个百分比,这个便是学习系数,并且,跟着练习的深化,这个系数是能够变的。
当然,还有一些很重要的基本常识,比方SGD(随机梯度下降),mini batch 和 epoch(用于练习集的挑选),限于篇幅,今后再侃吧。其实参阅李宏毅的那篇文章就能够了。其实上面描绘的,首要是关于怎样调整参数,归于初级阶段。上面其实也说到,在调参之前,都有默许的网络模型和参数,怎样界说最初始的模型和参数?就需求进一步深化了解。不过关于一般做工程而言,只需求在默许的网络上调参就能够,相当于用算法;关于学者和科学家而言,他们会创造算法,这有很大的难度。向他们问候!