像MIPS技能公司最新的MIPS32 34K内核这样的多线程架构正吸引着越来越多的重视,这是由于这种架构无需添加太多的芯片资源或功耗即可取得可观的功用增益。这种硬件多线程的要害优势是,它能运用处理器在等候缓冲回填的闲暇周期处理其它线程的指令。
使消费类设备运用程序习惯多线程环境的价值一般很小,由于大多数程序现已规划为成组的半独立线程。运用程序线程能够分配给处理器顶用于处理单线程的专用硬件资源。多个线程能够被一起分配给这样的硬件,并经过同享CPU周期取得最大的功率。
嵌入式运算面对功用妨碍
消费类设备和其它嵌入式核算产品的制造商正在添加Wi-Fi、VoIP、蓝牙、视频等各种新的功用,以往功用的添加都要靠大幅进步处理器的时钟速度来完结。台式机的时钟速度现在现已添加到3GHz以上,即便嵌入式设备也挨近GHz级。
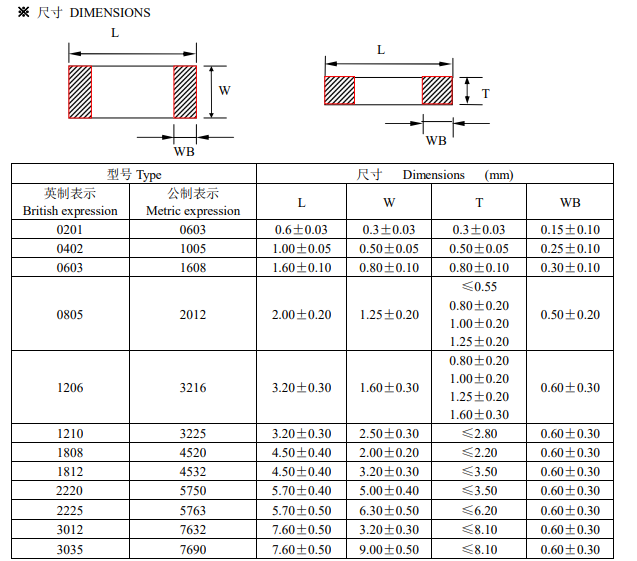
但在嵌入式运用领域,这种办法很快就失去了可行性,由于大多数设备的运转收到功耗和资源的束缚,这些都约束了处理器速度的进一步进步。时钟周期速度的进步将显著地增大功耗,因而对越来越多的嵌入式设备来说高周期速度将不大可行。别的,处理器速度的进一步进步并不能带来相应的功用改进,由于存储器功用的进步跟不上处理器速度进步的脚步,如上图1所示。
处理器速度现已比存储器快许多,在许多运用场合处理器有一半以上的时刻在等候缓存行(cache line)回填数据。每逢缓存丢掉(cache miss)或需求片外存储器拜访时,处理器就需求从存储器加载缓存行,将这些字写进缓存,再将旧的缓存行写进存储器,最终康复线程。
MIPS公司指出,每千条指令承受25次缓存丢掉(对多媒体代码来说是一个合理的值)的高端可归纳内核假如有必要等候50个缓存填充周期,那么将有50%以上的时刻处于中止状况。由于处理器速度仍在不断进步,并且比存储器速度的进步起伏大得多,这类问题将变得越来越杰出。
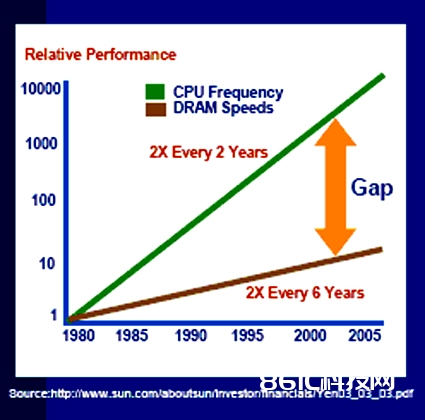
图1:处理器速度超越存储器。
多线程技能
多线程技能处理了这一难题,它能够运用处理器本来用于等候存储器拜访的闲暇时刻处理多个并行程序履行线程。当一个线程停下来等候存储器响应时,别的一个线程会立刻提交给处理器,然后坚持运算资源的充分运用。
值得注意的是,传统处理器不能选用这种办法,由于它需求很多指令周期才干完结线程之间的切换。要想使这种办法顺畅作业,多个运用程序线程有必要当即有用,并能逐周期运转。
34K处理器是来自面向消费类设备商场的嵌入式处理器首要供给商的首个多线程产品。每个软件线程在线程环境(Thread Context, TC)上履行,一个TC包含一整套通用寄存器和一个程序计数器(program counter)。
每个TC都有自己的指令预取行列,一切行列都彻底独立。这意味着内核能在线程间逐周期地进行切换,因而能够防止软件中发生开支。添加更多的TC只需添加很少的额定硅片。TC同享大部分CPU硬件,包含履行单元、ALU和缓存。并且,添加一个TC并不要求CPU具有别的一个OS软件运转CPU所需的CP0寄存器复制。
一组同享CP0寄存器以及与之相关的TC即组成一个虚拟处理单元(VPE)。一个TC运转一个线程,一个VPE办理一个操作体系:假如有两个VPE,那么就能够有两个独立的操作体系,或一个SMP风格的操作体系。带一个TC的VPE看起来就像是传统的MIPS32架构CPU,并且彻底兼容MIPS架构标准-其实便是一个完好的虚拟处理器。
34K内核最多能够有9个TC和2个VPE。TC到VPE的联络取决于运转时刻。默许状况下一切预备履行的TC都相等同享处理时刻,但34K内核也能在某个特殊要求线程或许会“挨饿”的状况下让某个程序影响线程调度,也便是说软件能够操控每个线程的服务质量(QoS)。运用软件与硬件战略办理器(Policy Manager)互动,战略办理器向各个TC分配动态改动的优先级。然后由硬件分发调度器将线程逐一周期地分配给履行单元,然后满意QoS要求。
在像34K这样的多线程环境中,功用能够大大地进步,由于只需一个线程处于等候存储器拜访状况,别的一个线程就会占用闲暇下来的处理器周期。上图2标明晰多线程是怎么加速程序履行速度的。当只要线程0运转时,13个处理器周期中只要5个用于指令履行,剩余7个悉数在等候缓存行的回填。在这种运用传统处理办法的状况下功率只要38%。
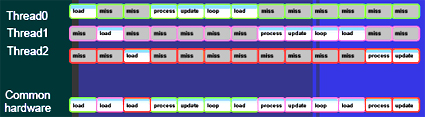
图2:多线程进步了管线功率。
添加线程1就或许运用上述5个用于等候的处理器周期。现在13个处理器周期顶用到了10个,功率进步到77%,与最基本状况比较速度加速了一倍。添加线程2后能够彻底加载处理器资源,13个履行指令周期能够悉数用上,功率到达100%。比较基本状况速度进步263%。
选用EEMBC功用基准的测验标明,34K内核与24KE系列产品比较,只用两个线程就能够提速60%,而硅片尺度只添加14%,如图3所示。
图3:EEMBC基准功用比如标明只用两个线程功用就有60%的进步。
使软件习惯多线程
多线程办法的要害优势是在大多数状况下现有软件只需做极少数的修正就能顺畅运转。大多数消费类设备程序现已写成一系列的半独立线程。每个线程能够被主动或人工地分配给专门的硬件TC。
假如当时正在履行的线程由于缓存丢掉或其它原因引起的时延而无法持续运转,CPU履行机制就会从那个TC切换到别的一个TC,该TC的线程能够在不糟蹋CPU周期的状况下运转。程序中线程越多,运用等候存储器拜访周期的或许性就越高。
多线程处理对运用或考虑运用RTOS的任何人来说都是十分抱负的,由于RTOS程序自身就具有多线程特性。无需为多线程从头编写RTOS程序,由于RTOS能够在程序操控下主动将程序线程映射为TC,其映射办法与将线程映射为传统处理器的办法相同。
假如线程数比TC多,一般需求用到传统的环境切换(context switch)。这些环境切换与传统处理器中的是相同的。RTOS保存当时使命的状况,加载别的一个使命的环境并开端履行。多线程环境明显要比传统处理器更适合更多环境的切换,所完结的环境切换速度也更快。
Linux/Windows与RTOS的多线程比较
本节要点介绍相对Linux和嵌入式Windows版别等操作体系而言快速RTOS的优势。Linux的典型实时功用在数百微秒到数毫秒。但在最坏状况下Linux实时功用并不抱负。而快速RTOS能够供给确认的实时功用,在单线程处理器上能够达1到2毫秒,在多线程处理器上还会更快。
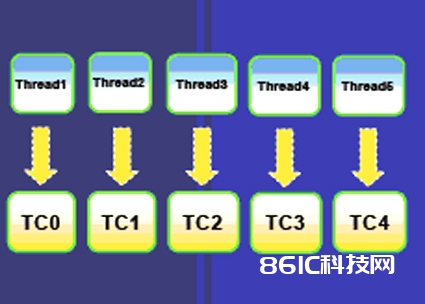
图4:将线程映射为TC
RTOS将仅有资源分配给仅有的TC。传统的做法是将单浮点单元(FPU)分配给TC0。任何履行硬件级浮点运算的线程都需求被映射为TC0,因而一切这类线程有必要同享TC0。这就形成了多种风趣的编程挑选,特别是用硬件仍是软件完结浮点运算的挑选。
用硬件完结浮点运算明显速度会更快,但另一方面需求同享FPU。假如线程只做少数的浮点运算,那么用软件完结将更有意义,而需求密布浮点运算的线程一般要用硬件完结,并被映射到TC0。值得注意的是,这个修正不需求记载,由于是否用硬件或软件浮点完结的决议能够由编译器切换完结。
给线程分配权重
假如程序没有给各个线程界说权重,那么程序调度器就会给一切线程分配相同的权重,别的也能够运用时刻分段技能使线程依据用户指定的权重同享CPU周期。分配权重相当于将恰当份额的CPU周期分配给各个详细线程。线程权重由RTOS透明地映射为硬件TC。
一些现有程序是针对传统处理器规划的,其前提条件是假定在有高优先级的线程预备好时低优先级线程将被制止运转。在嵌入式编程环境中,预备好的意思是线程运转所必需的悉数条件都得到了满意,阻挠它运转的仅有要素是它的优先级。
多线程可损坏这种条件,由于不管高优先级线程是否中止,低优先级线程都能运转。编写撤销这种状况的代码可优化功用。
别的一方面,依据这种条件编写的现有代码无需修正就能运转在多线程处理器上,只需简略地设置操作体系开关,使其只允许相同优先级的线程一起被加载到TC。在设置这个开关时,需求保证给那些能够并行运转的线程尽量分配相同的优先级。
可中止的重要性
在传统的嵌入式运用中中止是十分重要的,由于它们供给了首要的、在许多状况下也是仅有的线程间切换办法。中止在多线程运用中也起着相同的效果,但有一个重要的差异,即在多线程运用中,线程间的切换不只要经过中止,还要运用闲暇CPU周期。
需求尽量防止在修正要害数据结构时中止某个线程,一起重用别的一个线程对同一结构作其它修正。这将导致数据结构处于不一致的状况,极易引起灾难性结果。
大多数传统运用处理这个问题的办法是,当ISR或体系服务正在修正RTOS中要害的数据结构时暂时锁住中止。这种办法可靠地阻挠了任何其它程序跳进来对履行代码正在运用的要害区域做出不恰当的修正。
然而在多线程环境中这种办法是不行的,由于有或许被切换到不受中止确定操控的不同TC,然后或许对要害区域做出修正。该问题能够运用34K架构中的DMT指令处理,当数据结构在修正状况时可制止多线程功用。
除了这些相对简略的例外状况外,设备代码在从传统设备移植到多线程设备时无需修正就能直接运转。因而,咱们能够运用以往被传统RISC处理器糟蹋的CPU周期,充分发挥多线程功用优势。多线程能够满意当时和未来需求高功用的消费类、网络、存储和工业设备运用要求,而本钱和功耗只要少数的添加。
与首要的竞赛技能–多内核技能比较,多线程有更小的硅片面积和更低功耗的优势,并且编程简略,现有程序只需做少数修正乃至不必修正就能运转。多内核办法也有它自己的优势和强项,因而没有理由证明这两种办法不能融合出一种最佳办法。在要求高功用、低本钱和最小功耗的运用场合,多线程是一种极具竞赛力的计划。
作者:
John A. Carbone
产品行销副总裁
Express Logic公司