发现了程序的问题再回头去调试,在查找程序过错时就不可防止地要花很多时刻。要调高开发功率,最好是在编写代码时就防止一些常见的初级过错,这样能够节省很多的调试时刻。
有些编程过错差不多是每个 LabVIEW 程序员都曾遇到过的。在编写相关代码的时分,对这些问题多留神一下,就能够大大削减调试时刻。
1. 数值溢出
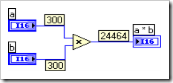
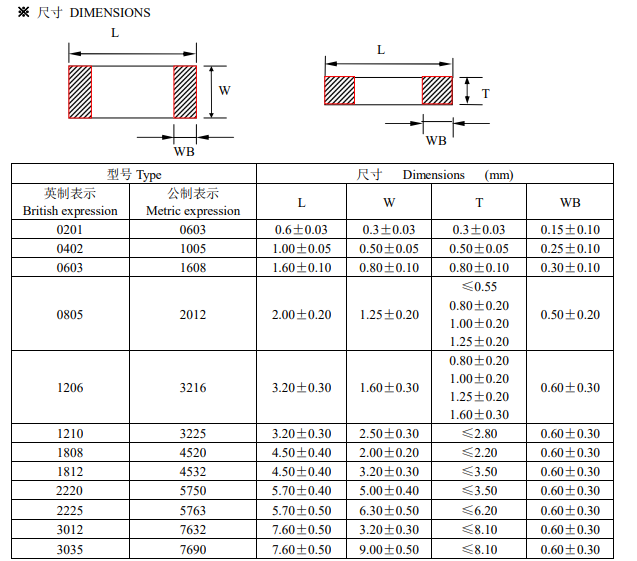
图1:数值溢出过错
图1 中的 VI 只做了一个简略乘法 300*300 ,不加思索就应该知道答案是 90000,但程序中乘法节点给出的成果却是 24464。乘法节点是不会错的,过错是由于程序中运用的数据类型是 I16。I16 能表明的最大数目只要32767,所以在乘法核算中呈现了溢出。
防止此类过错的办法是,在程序中运用短数据类型时,必定要承认程序中的数据绝不会超出该类型能够表明的规模。
2. For 循环的地道
循环相关的介绍能够参阅《循环结构》。
数据传入传出循环结构能够经过移位寄存器(Shift Register)和地道(Tunnel)两种方法。地道又有两种类型:带索引的和不带索引的。
移位寄存器一般用在需求局部变量的状况下,循环运转一次的输出数据要作为下次运转的输入数据运用;循环外的数组数据经过带索引的地道在循环体内就能够直接得到数组元素;除此之外,简略地在循环表里传递数据,运用一般的地道就能够了。
值得一提的是,假如一个数据传入循环体,又传出来,那么就应该运用移位寄存器或带索引的地道来传递这个数据,尽量不要运用不带索引的地道。由于 For 循环在运转时,循环次数有或许为0。在循环次数为0时,大大都状况,用户仍是期望传出循环的数据便是传入值,但运用不带索引地道时,输入值有时会被丢掉的。假如运用移位寄存器,即便循环次数为0,也不会丢掉传入的数据。由于移位寄存器在循环上的两个接线柱指向的实践是同一块内存(参阅:LabVIEW 程序的内存优化),而输入输出两个地道指向的是不同的内存,数据不用定相同。
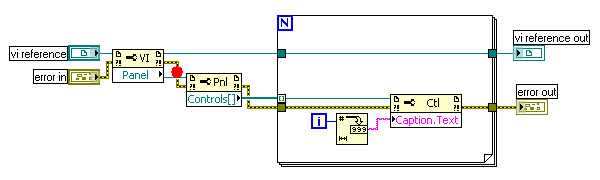
图2:For 循环上的地道
图2中的程序, vi reference 传入,再传出循环均运用了地道。假如循环次数为0(Controls数组为空),vi reference 再传出循环时,信息就丢掉了。这不但有或许形成后续程序的过错,并且由于 vi reference 的信息丢掉,再无法封闭翻开的 vi,形成了程序走漏。
Error 数据线(黄绿色的粗线)在传入传出数组时,必定要运用移位寄存器。原因还不仅是为了防止在循环次数为0时,过错信息丢掉。一般一个节点的 Error Out 有过错输出,意味着后续的程序都不应该履行。在过错的状况下持续履行程序代码,危险非常大,或许会引起程序,乃至体系溃散。只要运用移位寄存器,某次循环发生的过错才会被传递到后续的循环中,然后及时阻挠后续循环中的代码被运转。
3. 循环次数
与其它言语比较,LabVIEW 的 For 循环有一大特色,在某些状况下它并不要求必定要输入循环次数,而能够依据输入数组的巨细主动决议循环次数。经过带索引的地道,能够把数组分解成元素传递到循环体内,此刻不需另行设置循环次数N,循环的次数便是数组的长度。每次循环,带索引的地道便给出一个元素。
循环体上能够有两个或更多的输入数组运用带索引的地道,此种状况下简略引起过错。这时,循环的次数等于几个数组中长度最短的那个数组的长度。假如别的又设置了循环次数N,那么循环次数便是N与输入数组长度这两者的最小值。调试时,假如发现一个本该运转屡次的循环没有运转,那么很或许便是由于它的一个输入数组是空的。
While 循环相同也能够运用带索引的地道,可是我不主张我们这么用——假如需求用到带索引的地道,仍是运用 For 循环更为适合。由于 while 循环的循环次数不由数组个数决议,而是由中止条件决议的。如运用了带索引的地道,你还需求考虑当数组大于、小于循环次数时,程序应该怎样处理,所以仍是在循环体内作索引比较便利。假如期望循环次数与数组巨细保持一致,那自然是用 For 循环的程序愈加明晰易懂了。
4. 移位寄存器的初始化
图3:没有初始化的移位寄存器
看图3中这个程序,由于它在 while 循环上运用了带索引的地道,所以可读性不那么好。array out 的运转成果是什么,还要考虑一阵子才干给出答案。实践上这个程序,即便输入不变,每运转一次,array out 的成果都是不一样的,它的长度一直在添加。这个问题就出在没有给程序中的移位寄存器一个初始值。
没有初始化的移位寄存器,总是保存前次运转完毕时的数据。这个特色在某些状况下能够被程序员运用,比方用它当作全局变量,随时把数据存入或取出(一个比方是《怎样运用 VI 的重入特点》中的图4)。但大都状况下移位寄存器仍是被用作为循环内部的局部变量的,这时就必定要对它初始化,以防止潜在的过错。
5. Cluster
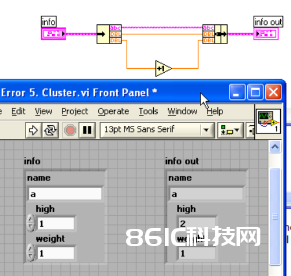
图4:Cluster 传递数据犯错
图4的程序中有个古怪的过错,分明应该是 weight 加 1 怎样运转完后的成果变成了high 加 1 了呢?直接揭开谜底吧,原因是 Cluster 中的元素有个次第,这个次第能够和界面上看到的次第不一致。别离鼠标右击程序中的两个 Cluster,挑选“Reorder Controls in Cluster”,就能够看到每个元素在 cluster 中的编号。info out 中的 high 实践上编号是 2,第三个元素。
为了防止 cluster 顶用或许呈现的过错,以及让 cluster 运用起来更便利,运用 cluster 最好遵从以下准则:
1. 但凡用到 cluster 的当地,就为它造一个类型界说(《在程序中运用类型界说》),在程序一切要用到这个 cluster 的当地,都运用类型界说的实例。这样一是能够确保一切的 cluster 都完全一致,防止图4 这种过错;二是一旦需求变化 cluster 中的元素,只需在类型界说中更新就能够了,不用挨个 VI 修正。
2. 但凡在需求解开(unbundle)或打包(bundle)的当地通通运用 unbundle by name 和 bundle by name 来完成。运用带姓名的 bundle,unbundle 能够直观的显示出 bundle 种元素的姓名,这样不会由于次第的不同而导致过错的连线。
6. 并行运转
LabVIEW 是主动多线程的编程言语,这一点在便运用户的一起,也会带来一些费事。比方最常见的状况,多线程会引起数据或资源的竞赛过错(race condition)。
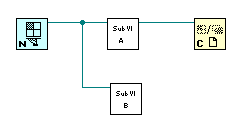
图5:两个并行运转的子 VI
图5是一个简略的两个子 VI 并行运转的比方,在这个比方中就隐藏着一个潜在的问题。并行履行的两部分程序,先后次第是不定的。有或许封闭程序中的引证数据(绿色的线上的数据)的节点在子 VI B 完毕前运转。而子 VI B 是要用到这个参阅数据的,这是子 VI B 就会由于它所需求的数据失效而发生过错