



MCU市场更加丰富多元,DSP/FPU不同硬件加速单元具互补作用-微控制器(MCU)深入人们应用生活,几乎大小设备都看得到MCU踪影,在MCU导入DSP数位讯号处理器、FPU浮点运算单元功能后,MCU更大幅扩展 元件可适用范围,这几年来,在众多MCU大厂纷纷针对旗下商品推出多样整合方案,不管是产品策略还是市场区隔,也让MCU市场更加丰富多元。
基于LinkedInSTM32F4时钟系统初始化设置-SystemInit函数开始先进行浮点运算单元设置,然后是复位PLLCFGR,CFGR寄存器,同时通过设置 CR 寄存器的 HSI 时钟使能位来打开 HSI 时钟。

STM32F4的FPU性能的设置及要点-浮点运算一直是定点CPU的难题,比如一个简单的1.1+1.1,定点CPU必须要按照IEEE-754标准的算法来完成运算,对于8位单片机来说已经完全是噩梦,对32为单片机来说也不会有多大改善。虽然将浮点数进行Q化处理能充分发挥32位单片机的运算性能,但是精度受到限制而不会太高。对于有FPU(浮点运算单元)的单片机或者CPU来说,浮点加法只是几条指令的事情。
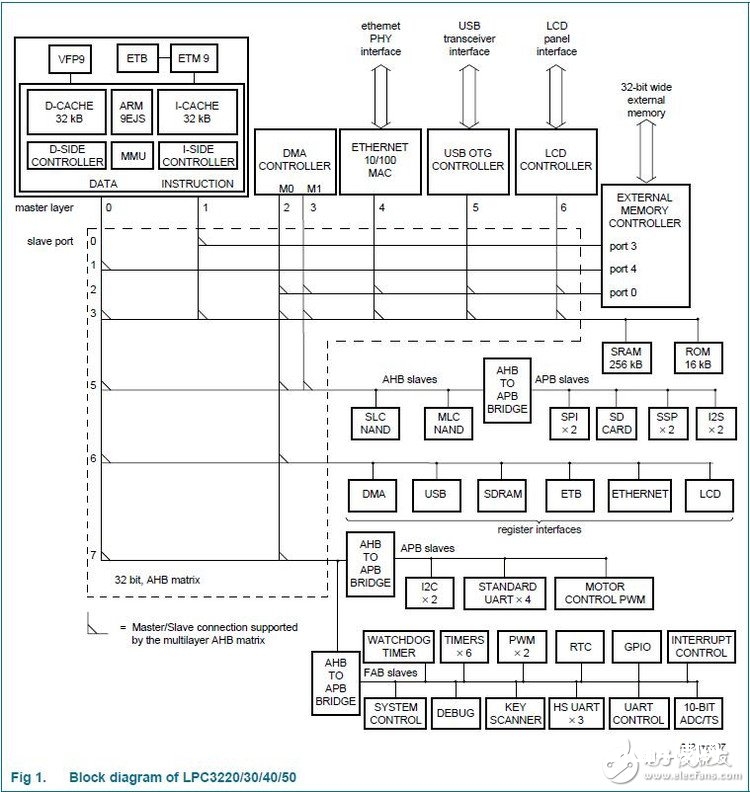
LPC3240的主要特点和功能概述-恩智浦公司的90nm工艺ARM926EJ-S核(包括矢量浮点联合处理器),以及大量的标准片上外围.CPU频率最高达到266Mhz。
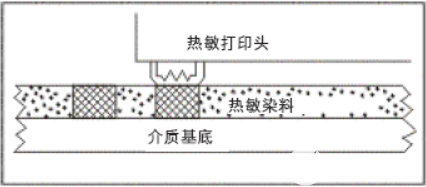
基于上海航芯ACM32F403的热敏打印机设计方案-ACM32F403芯片采用高性能内核,支持Cortex-M33和Cortex-M4F指令集。芯片内核支持一整套DSP指令用于数字信号处理,支持单精度FPU处理浮点数据,同时还支持Memory Protection Unit(MPU)用于提升应用的安全性。
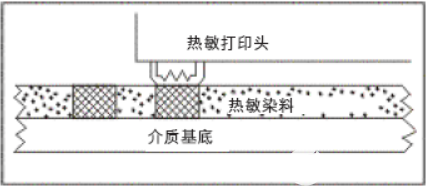
基于上海航芯ACM32F403的热敏打印机设计方案-ACM32F403芯片采用高性能内核,支持Cortex-M33和Cortex-M4F指令集。芯片内核支持一整套DSP指令用于数字信号处理,支持单精度FPU处理浮点数据,同时还支持Memory Protection Unit(MPU)用于提升应用的安全性。
基于EPF10K100EQ 240-132和Booth编码实现位浮点阵列乘法器的设计-随着计算机和信息技术的快速发展, 人们对微处理器的性能要求越来越高。乘法器完成一次乘法操作的周期基本上决定了微处理器的主频, 因此高性能的乘法器是现代微处理器中的重要部件。本文介绍了32 位浮点阵列乘法器的设计, 采用了改进的Booth 编码, 和Wallace树结构, 在减少部分积的同时, 使系统具有高速度, 低功耗的特点, 并且结构规则, 易于VLSI的实现。

Xilinx Vivado HLS中Floating-Point(浮点)设计介绍-尽管通常Fixed-Point(定点)比Floating-Point(浮点)算法的FPGA实现要更快,且面积更高效,但往往有时也需要Floating-Point来实现。这是因为Fixed-Point有限的数据动态范围,需要深入的分析来决定整个设计中间数据位宽变化的pattern,为了达到优化的QoR,并且要引入很多不同类型的Fixed-Point中间变量。而Floating-Point具有更大的数据动态范围,从而在很多算法中只需要一种数据类型的优势。Xilinx Vivado HLS工具支持C/C++ IEEE-54标准单精度及双精度浮点数据类型,可以比较容易,快速地将C/C++ Floating-Point算法转成RTL代码。
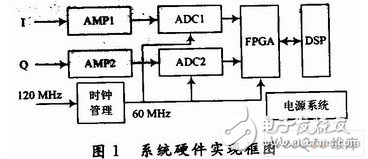
利用ADS5500的FPGA1024点的数字脉冲压缩系统设计-在数字信号处理系统中,数据表示格式可分为定点制、浮点制和块浮点制,它们在实现时对系统资源的要求不同,工作速度也不同,有着不同的适用范围。定点表示法使用最多,简单且速度快,但动态范围有限,需要用合适的溢出控制规则(如定比例法)适当压缩输入信号的动态范围,但这样会降低输出信号的信噪比。浮点表示法的优点是动态范围大,可避免溢出,能在很大的动态范围内达到很高的信噪比,主要缺点是系统实现复杂,硬件需求量大,成本和功耗高,而且速度较慢。

Altera FPGA硬核浮点DSP模块解决方案提高运算性能-以往FPGA在进行浮点运算时,为符合IEEE 754标准,每次运算都需要去归一化和归一化步骤,导致了极大的性能瓶颈。因为这些归一化和去归一化步骤一般通过FPGA中的大规模桶形移位寄存器实现,需要大量的逻辑和布线资源。通常一个单精度浮点加法器需要500个查找表(LUT),单精度浮点要占用30%的LUT,指数和自然对数等更复杂的数学函数需要大约1000个LUT。因此随着DSP算法越来越复杂,FPGA性能会明显劣化,对占用80%~90%逻辑资源的FPGA会造成严重的布线拥塞,阻碍FPGA的快速互联,最终会影响时序收敛。
