


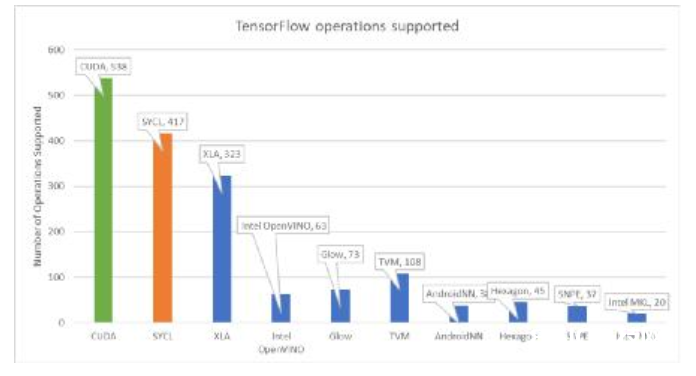
TensorFlow通过优化的开源SYCL™库获得对PowerVR GPU的原生支持-Imagination Technologies宣布:得益于全新优化的开源SYCL神经网络库,使用TensorFlow的开发人员将可以直接面向PowerVR图形处理器(GPU)进行开发。其首个版本将在2019年提供商用。

想要实现FPGA的CNN加速 需要考虑以下内容-网上对于FPGACNN加速的研究已经很多了,神经网络的硬件加速似乎已经满大街都是了,这里我们暂且不讨论谁做的好谁做的不好,我们只是根据许许多多的经验来总结一下实现硬件加速,需要哪些知识,考虑哪些因素。

一种基于FPGA的神经网络硬件实现方案详解-人工神经网络在智能控制、模式识别、图像处理等领域中应用广泛。在进行神经网络的应用研究时,人们可以将神经网络模型或算法在通用的计算机上软件编程实现,但很多时间浪费在分析指令、读出写入数据等,其实现效率并不高。软件实现的缺点是并行程度较低,因此利用软件实现神经网络的方法无法满足某些对数据实时处理要求较高的场合(如工业控制等领域)。
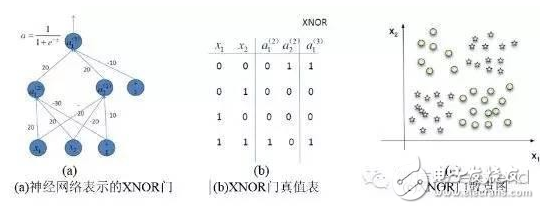
一种递归神经网络在FPGA平台上的实现方案详解-近十年来,人工智能又到了一个快速发展的阶段。深度学习在其发展中起到了中流砥柱的作用,尽管拥有强大的模拟预测能力,深度学习还面临着超大计算量的问题。在硬件层面上,GPU,ASIC,FPGA都是解决庞大计算量的方案。本文将阐释深度学习和FPGA各自的结构特点以及为什么用FPGA加速深度学习是有效的,并且将介绍一种递归神经网络(RNN)在FPGA平台上的实现方案。
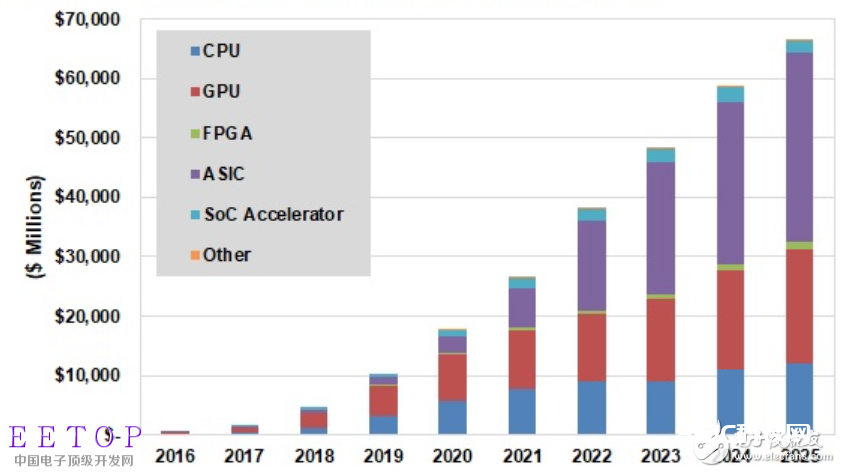
关于机器学习中的FPGA与SoC应用浅析- 这些新设备有两个主要市场。机器学习中的神经网络将数据分为两个主要阶段:训练和推理,并且在每个阶段中使用不同的芯片。虽然神经网络本身通常驻留在训练阶段的数据中心中,但它可能具有用于推理阶段的边缘组件。现在的问题是什么类型的芯片以及哪种配置能够产生最快、最高效的深度学习。

一款Xilinx FPGA的CNN加速器IP—AIScale-随着人工智能(AI)的不断发展,它已经从早期的人工特征工程进化到现在可以从海量数据中学习,机器视觉、语音识别以及自然语言处理等领域都取得了重大突破。CNN(Convolutional Neural Network,卷积神经网络)在人工智能领域受到越来越多的青睐,它是深度学习技术中极具代表性的网络结构之一,尤其在图像处理领域取得了很大的成功。
标签:射频电路 模糊逻辑随着通信技术的发展,射频电路在通信系统中得到了广泛的应用。功率放大器的研究和设计一直是通信发展中的重要课题。近年来,基于模糊神经网络的射频器件和电路建模的研究取得了巨大的成果

神经网络基础1、神经元(Neuron)——就像形成我们大脑基本元素的神经元一样,神经元形成神经网络的基本结构。想象一下,当我们得到新信息时我们该怎么做。当我们获取信息时,我们一般会处理它,然后
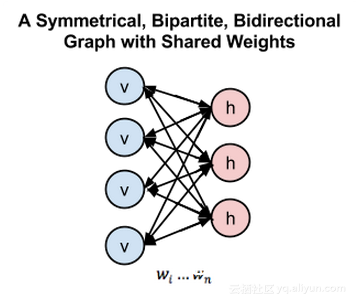
深度学习概述o 受限玻尔兹曼机和深度信念网络o Dropouto 处理不平衡的技巧o SMOTE :合成少数过采样技术o 神经网络中对成本敏感的学习深度学习概述在 20
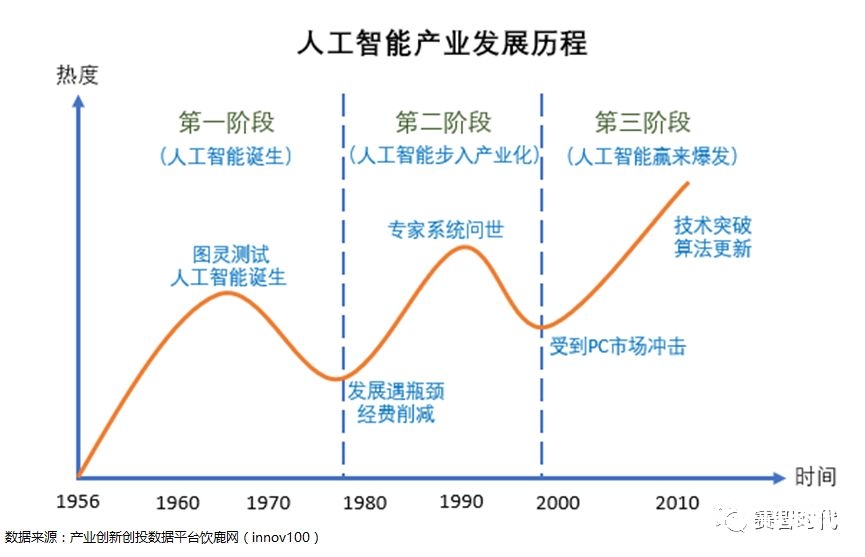
最近很长的一段时间,人工智能的热度都维持在一定的高度。但是大家在关注或研究人工智能领域的时候,总是会遇到这样的几个关键词:深度学习、机器学习、神经网络。那他们之间到底是什么样的关系呢?先说人工
