



基于C51程序递归的使用方法解析-上面的函数是有错误的,可重入函数不能传递bit类型的变量。在多任务系统中,可重入函数也不要用全局变量,多个函数同时调用时可能会使变量出现多个值,但是在单任务系统中,个人认为某些时候下是可以利用的。只要不出现改变变量值的情况。

80C51单片机的startup.a51程序模块的作用-startup.a51的主要工作是把包含idata、xdata、pdata在内的内存区块清除为0,并且初始化递归指针。接着startup.a51被执行的仍然是一个隐藏在KEIL-C51标准链接库中称为init.a51的程序模块。而init.a51的主要工作则是初始化具有非零初始值设定的变量。
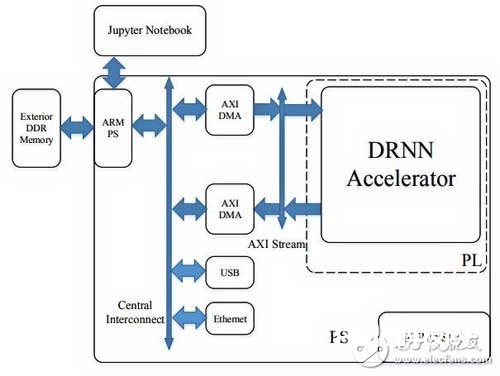
基于Xilinx FPGA上实现深度递归神经网络语言模型-可编程逻辑(PLD)是由一种通用的集成电路产生的,逻辑功能按照用户对器件编程来确定,用户可以自行编程把数字系统集成在PLD中。经过多年的发展,可编程逻辑器件由70年代的可编程逻辑阵列器件 (PLD) 发展到目前的拥有数千万门的现场可编程阵列逻辑 (FPGA),随着人工智能研究的火热发展,FPGA的并行性已经在一些实时性很高的神经网络计算任务中得到应用。由于在FPGA上实现浮点数会耗费很多硬件资源,而定点数虽然精度有限,但是对于不同应用通过选择合适的字长精度仍可以保证收敛,且速度要比浮点数表示更快而且资源耗费更少,已经使其成为嵌入式AI和机器学习应用程序的理想选择。
一种递归神经网络在FPGA平台上的实现方案详解-近十年来,人工智能又到了一个快速发展的阶段。深度学习在其发展中起到了中流砥柱的作用,尽管拥有强大的模拟预测能力,深度学习还面临着超大计算量的问题。在硬件层面上,GPU,ASIC,FPGA都是解决庞大计算量的方案。本文将阐释深度学习和FPGA各自的结构特点以及为什么用FPGA加速深度学习是有效的,并且将介绍一种递归神经网络(RNN)在FPGA平台上的实现方案。



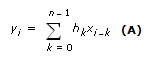
FIR滤波器FIR——Finiteimpulseresponse,有限冲激响应。FIR滤波器,也可称为非递归滤波器,卷积滤波器,滤波器当前输出与当前输入值和

物联网创客指南:MCU设计的最佳实践和除错技巧-在本节中,SiliconLabs将分享在软件开发方面的经验教训。关键词extern,static和volatile都是什么?你应该在你的代码中使用递归还
