


DSP(Digital Signal Processing,数字信号处理)中会运用很多的数学运算。Cortex-M4中,装备了一些强壮的部件,以进步DSP才能。一起CMSIS供给了一个DSP库,供给了许多数学函数的高效完结。
这次就先做一个简略的测验,求两个向量的数量积。
一、 硬件

MAC单元
MAC(Multiply-ACcumulate,乘积累加),是DSP中常用的一种运算。Cortex-M4装备了一个32位的MAC单元,它能在1个周期里完结最高难度为32位乘32位再加64位的运算,或是两个16位乘16位的运算。Cortex-M4支撑的MAC指令如下,这些指令都能在1个周期内完结:

SIMD
SIMD(Single Instruction Multiple Data,单指令多数据),能够进步DSP时的核算功率。这在Cortex-M3中不可用的。运用Cortex-M4的SIMD指令,能够在一个周期内并行地完结4个8位数的加减,或是2个16位数的加减。
FPU
FPU是Cortex-M4添加的可选的部件(SAM4E装备了FPU)。其完结了单精度的浮点数运算,包含一些MAC运算:

二、 运用CMSIS的DSP库
CMSIS中,供给了一个DSP库。这儿对DSP中常用的数学运算做了很高效的完结。而关于Cortex-M4,其完结也针对SIMD进行了优化。
在CMSISInclude文件夹中,头文件ARM_math.h 声明晰这些函数。而在CMSISLibGCC 中,有针对各渠道编译好了的静态库文件。在CMSISDSP_LibSource 中,有DSP的完结源码。
而在运用arm_math.h 文件的过程中,需求依据方针渠道预界说宏ARM_MATH_CM4,ARM_MATH_CM3 或ARM_MATH_CM0 。而若需求运用FPU,则需求在设备头文件(如sam4e16e.h)中将宏__FPU_PRESENT 的值界说为1。
在AS6中,默许现已添加了DSP的支撑。
进入工程特点的toolchain选项卡,能够在ARM/GNU C Complier的Directories中挑选编译时查找头文件的途径。AS6在树立工程时,就会一些需求的头文件复制到工程目录下,一起做好了途径设置。比方AS6现已把arm_math.h 复制到下图中方框指出的途径了:
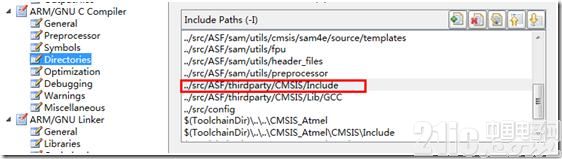
在ARM/GNU Linker的Libraries选项中,能够挑选链接时运用的库以及库的途径。相同,AS6现已把静态库文件复制到了工程目录下,且设置好了文件:

在ARM/GNU C Complier的Symbols选项中,能够设置预界说的宏。能够在这儿声明阐明DSP的方针渠道的宏ARM_MATH_CM4:
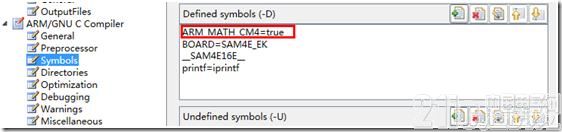
在设备头文件件中声明__FPU_PRESENT 的值。假如有FPU,则将该宏界说为1,不然界说为0。CMSIS现已做好了界说:
//File: …srcASFsamutilscmsissam4eincludesam4e16e.h
//Line: 266
/** SAM4E16E does provide a FPU */
#define __FPU_PRESENT 1
别的,假如不运用AS6供给的startup文件,或许需求在自己的代码中运用FPU的话,还需求做额定的设置。相关内容在FPU的示例中做了阐明。
三、 简略示例
DSP库里有核算向量数量积的函数。DSP库的函数支撑多种类型的定点数,且关于装备了FPU的部件,也支撑浮点数。所以只需求简略地调用下所需函数即可:
// 向量为(0.0, 1.1, 2.2, …, 16.5)
const int VEC_SIZE = 16;
float32_t vec[VEC_SIZE];
for (int i = 0; i VEC_SIZE; ++i)
vec[i] = 1.1f * i;
// 核算向量与本身的数量积
float32_t result = 0;
arm_dot_prod_f32(vec, vec, VEC_SIZE, result);
// result == 1500.4
检查arm_dot_prod_f32() 的完结,发现其现已为了功率进行了循环展开。而检查别的一些有关定点数的运算,能够发现其完结现已运用了SIMD等特别指令;有些乃至针对内存拜访的推迟进行了优化。不难看出,这个库的完结进行了详尽优化的。
别的,除了根本的数学函数,DSP库也完结了快速数学函数(三角函数、开平方等)、实数相关、矩阵运算、计算、滤波、改换(FFT等)、马达操控等功用。arm_math.h 中,现已对各个函数的功用、参数含义等做了具体的阐明。






