


众所周知,现在的分时操作体系能够在一个CPU上运转多个程序,让这些程序表面上看起来是在一起运转的。linux便是这样的一个操作体系。
在linux体系中,每个被运转的程序实例对应一个或多个进程。linux内核需求对这些进程进行办理,以使它们在体系中“一起”运转。linux内核对进程的这种办理分两个方面:进程状况办理,和进程调度。
进程状况
在linux下,经过ps指令咱们能够查看到体系中存在的进程,以及它们的状况:
R (TASK_RUNNING),可履行状况。
只需在该状况的进程才或许在CPU上运转。而同一时间或许有多个进程处于可履行状况,这些进程的task_struct结构(进程操控块)被放入对应CPU的可履行行列中(一个进程最多只能呈现在一个CPU的可履行行列中)。进程调度器的任务便是从各个CPU的可履行行列中别离挑选一个进程在该CPU上运转。
只需可履行行列不为空,其对应的CPU就不能偷闲,就要履行其间某个进程。一般称此刻的CPU“繁忙”。对应的,CPU“闲暇”便是指其对应的可履行行列为空,以致于CPU无事可做。
有人问,为什么死循环程序会导致CPU占用高呢?因为死循环程序基本上总是处于TASK_RUNNING状况(进程处于可履行行列中)。除非一些十分极点状况(比方体系内存严峻紧缺,导致进程的某些需求运用的页面被换出,并且在页面需求换入时又无法分配到内存……),不然这个进程不会睡觉。所以CPU的可履行行列总是不为空(至少有这么个进程存在),CPU也就不会“闲暇”。
许多操作体系教科书将正在CPU上履行的进程界说为RUNNING状况、而将可履行可是尚未被调度履行的进程界说为READY状况,这两种状况在linux下一致为 TASK_RUNNING状况。
S (TASK_INTERRUPTIBLE),可中止的睡觉状况。
处于这个状况的进程因为等候某某事情的产生(比方等候socket衔接、等候信号量),而被挂起。这些进程的task_struct结构被放入对应事情的等候行列中。当这些事情产生时(由外部中止触发、或由其他进程触发),对应的等候行列中的一个或多个进程将被唤醒。
经过ps指令咱们会看到,一般状况下,进程列表中的绝大多数进程都处于TASK_INTERRUPTIBLE状况(除非机器的负载很高)。究竟CPU就这么一两个,进程动辄几十上百个,假如不是绝大多数进程都在睡觉,CPU又怎样呼应得过来。
D (TASK_UNINTERRUPTIBLE),不行中止的睡觉状况。
与TASK_INTERRUPTIBLE状况相似,进程处于睡觉状况,可是此刻进程是不行中止的。不行中止,指的并不是CPU不呼应外部硬件的中止,而是指进程不呼应异步信号。
绝大多数状况下,进程处在睡觉状况时,总是应该能够呼应异步信号的。不然你将惊讶的发现,kill -9居然杀不死一个正在睡觉的进程了!所以咱们也很好了解,为什么ps指令看到的进程简直不会呈现TASK_UNINTERRUPTIBLE状况,而总是TASK_INTERRUPTIBLE状况。
而TASK_UNINTERRUPTIBLE状况存在的含义就在于,内核的某些处理流程是不能被打断的。假如呼应异步信号,程序的履行流程中就会被刺进一段用于处理异步信号的流程(这个刺进的流程或许只存在于内核态,也或许延伸到用户态),所以原有的流程就被中止了。
在进程对某些硬件进行操作时(比方进程调用read体系调用对某个设备文件进行读操作,而read体系调用终究履行到对应设备驱动的代码,并与对应的物理设备进行交互),或许需求运用TASK_UNINTERRUPTIBLE状况对进程进行维护,以避免进程与设备交互的进程被打断,形成设备堕入不行控的状况。(比方read体系调用触发了一次磁盘到用户空间的内存的DMA,假如DMA进行进程中,进程因为呼应信号而退出了,那么DMA正在拜访的内存或许就要被开释了。)这种状况下的TASK_UNINTERRUPTIBLE状况总是十分时间短的,经过ps指令基本上不行能捕捉到。
linux体系中也存在简单捕捉的TASK_UNINTERRUPTIBLE状况。履行vfork体系调用后,父进程将进入TASK_UNINTERRUPTIBLE状况,直到子进程调用exit或exec。
经过下面的代码就能得到处于TASK_UNINTERRUPTIBLE状况的进程:
#include
void main() {
if (!vfork()) sleep(100);
}
编译运转,然后ps一下:
kouu@kouu-one:~/test$ ps -ax | grep a\.out
4371 pts/0 D+ 0:00 。/a.out
4372 pts/0 S+ 0:00 。/a.out
4374 pts/1 S+ 0:00 grep a.out
然后咱们能够实验一下TASK_UNINTERRUPTIBLE状况的威力。不论kill仍是kill -9,这个TASK_UNINTERRUPTIBLE状况的父进程仍然耸峙不倒。
T (TASK_STOPPED or TASK_TRACED),暂停状况或盯梢状况。
向进程发送一个SIGSTOP信号,它就会因呼应该信号而进入TASK_STOPPED状况(除非该进程自身处于TASK_UNINTERRUPTIBLE状况而不呼应信号)。(SIGSTOP与SIGKILL信号相同,是十分强制的。不允许用户进程经过signal系列的体系调用从头设置对应的信号处理函数。)
向进程发送一个SIGCONT信号,能够让其从TASK_STOPPED状况康复到TASK_RUNNING状况。
当进程正在被盯梢时,它处于TASK_TRACED这个特其他状况。“正在被盯梢”指的是进程暂停下来,等候盯梢它的进程对它进行操作。比方在gdb中对被盯梢的进程下一个断点,进程在断点处停下来的时分就处于TASK_TRACED状况。而在其他时分,被盯梢的进程仍是处于前面说到的那些状况。
关于进程自身来说,TASK_STOPPED和TASK_TRACED状况很相似,都是表明进程暂停下来。
而TASK_TRACED状况相当于在TASK_STOPPED之上多了一层维护,处于TASK_TRACED状况的进程不能呼应SIGCONT信号而被唤醒。只能比及调试进程经过ptrace体系调用履行PTRACE_CONT、PTRACE_DETACH等操作(经过ptrace体系调用的参数指定操作),或调试进程退出,被调试的进程才干康复TASK_RUNNING状况。
Z (TASK_DEAD – EXIT_ZOMBIE),退出状况,进程成为僵尸进程。
进程在退出的进程中,处于TASK_DEAD状况。
在这个退出进程中,进程占有的一切资源将被收回,除了task_struct结构(以及少量资源)以外。所以进程就只剩余task_struct这么个空壳,故称为僵尸。
之所以保存task_struct,是因为task_struct里边保存了进程的退出码、以及一些计算信息。而其父进程很或许会关怀这些信息。比方在shell中,$?变量就保存了最终一个退出的前台进程的退出码,而这个退出码往往被作为if句子的判别条件。
当然,内核也能够将这些信息保存在其他当地,而将task_struct结构开释掉,以节约一些空间。可是运用task_struct结构更为便利,因为在内核中现已树立了从pid到task_struct查找联系,还有进程间的父子联系。开释掉task_struct,则需求树立一些新的数据结构,以便让父进程找到它的子进程的退出信息。
父进程能够经过wait系列的体系调用(如wait4、waitid)来等候某个或某些子进程的退出,并获取它的退出信息。然后wait系列的体系调用会趁便将子进程的尸身(task_struct)也开释掉。
子进程在退出的进程中,内核会给其父进程发送一个信号,告诉父进程来“收尸”。这个信号默许是SIGCHLD,可是在经过clone体系调用创立子进程时,能够设置这个信号。
经过下面的代码能够制作一个EXIT_ZOMBIE状况的进程:
#include
void main() {
if (fork())
while(1) sleep(100);
}
编译运转,然后ps一下:
kouu@kouu-one:~/test$ ps -ax | grep a\.out
10410 pts/0 S+ 0:00 。/a.out
10411 pts/0 Z+ 0:00 [a.out]
10413 pts/1 S+ 0:00 grep a.out
只需父进程不退出,这个僵尸状况的子进程就一向存在。那么假如父进程退出了呢,谁又来给子进程“收尸”?
当进程退出的时分,会将它的一切子进程都保管给其他进程(使之成为其他进程的子进程)。保管给谁呢?或许是退出进程地点进程组的下一个进程(假如存在的话),或许是1号进程。所以每个进程、每时每刻都有父进程存在。除非它是1号进程。
1号进程,pid为1的进程,又称init进程。
linux体系启动后,第一个被创立的用户态进程便是init进程。它有两项任务:
1、履行体系初始化脚本,创立一系列的进程(它们都是init进程的后代);
2、在一个死循环中等候其子进程的退出事情,并调用waitid体系调用来完结“收尸”作业;
init进程不会被暂停、也不会被杀死(这是由内核来确保的)。它在等候子进程退出的进程中处于TASK_INTERRUPTIBLE状况,“收尸”进程中则处于TASK_RUNNING状况。
X (TASK_DEAD – EXIT_DEAD),退出状况,进程即将被毁掉。
而进程在退出进程中也或许不会保存它的task_struct。比方这个进程是多线程程序中被detach过的进程。或许父进程经过设置SIGCHLD信号的handler为SIG_IGN,显式的疏忽了SIGCHLD信号。(这是posix的规则,虽然子进程的退出信号能够被设置为SIGCHLD以外的其他信号。)
此刻,进程将被置于EXIT_DEAD退出状况,这意味着接下来的代码当即就会将该进程完全开释。所以EXIT_DEAD状况是十分时间短的,简直不行能经过ps指令捕捉到。
进程的初始状况
进程是经过fork系列的体系调用(fork、clone、vfork)来创立的,内核(或内核模块)也能够经过kernel_thread函数创立内核进程。这些创立子进程的函数本质上都完结了相同的功用——将调用进程仿制一份,得到子进程。(能够经过选项参数来决议各种资源是同享、仍是私有。)
那么已然调用进程处于TASK_RUNNING状况(不然,它若不是正在运转,又怎样进行调用?),则子进程默许也处于TASK_RUNNING状况。
其他,在体系调用调用clone和内核函数kernel_thread也承受CLONE_STOPPED选项,从而将子进程的初始状况置为 TASK_STOPPED。
进程状况变迁
进程自创立今后,状况或许产生一系列的改变,直到进程退出。而虽然进程状况有好几种,可是进程状况的变迁却只需两个方向——从TASK_RUNNING状况变为非TASK_RUNNING状况、或许从非TASK_RUNNING状况变为TASK_RUNNING状况。
也便是说,假如给一个TASK_INTERRUPTIBLE状况的进程发送SIGKILL信号,这个进程将先被唤醒(进入TASK_RUNNING状况),然后再呼应SIGKILL信号而退出(变为TASK_DEAD状况)。并不会从TASK_INTERRUPTIBLE状况直接退出。
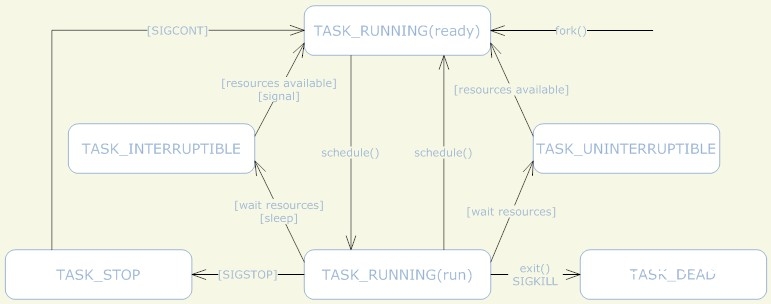
进程从非TASK_RUNNING状况变为TASK_RUNNING状况,是由其他进程(也或许是中止处理程序)履行唤醒操作来完成的。履行唤醒的进程设置被唤醒进程的状况为TASK_RUNNING,然后将其task_struct结构加入到某个CPU的可履行行列中。所以被唤醒的进程将有机会被调度履行。
而进程从TASK_RUNNING状况变为非TASK_RUNNING状况,则有两种途径:
1、呼应信号而进入TASK_STOPED状况、或TASK_DEAD状况;
2、履行体系调用自动进入TASK_INTERRUPTIBLE状况(如nanosleep体系调用)、或TASK_DEAD状况(如exit体系调用);或因为履行体系调用需求的资源得不到满意,而进入TASK_INTERRUPTIBLE状况或TASK_UNINTERRUPTIBLE状况(如select体系调用)。
明显,这两种状况都只能产生在进程正在CPU上履行的状况下。






