最近几年,FPGA这个概念越来越多地呈现。
例如,比特币挖矿,就有运用依据FPGA的矿机。还有,之前微软表明,将在数据中心里,运用FPGA“替代”CPU,等等。
其实,关于专业人士来说,FPGA并不生疏,它一向都被广泛运用。可是,大部分人还不是太了解它,对它有许多疑问——FPGA究竟是什么?为什么要运用它?比较 CPU、GPU、ASIC(专用芯片),FPGA有什么特色?……
今日,带着这一系列的问题,咱们一起来——揭秘FPGA。
为什么运用FPGA?
众所周知,通用处理器(CPU)的摩尔定律已入老年,而机器学习和 Web 服务的规划却在指数级增加。
人们运用定制硬件来加快常见的核算使命,但是一日千里的职业又要求这些定制的硬件可被从头编程来履行新类型的核算使命。
FPGA 正是一种硬件可重构的体系结构。它的英文全称是Field Programmable Gate Array,中文名是现场可编程门阵列。
FPGA常年来被用作专用芯片(ASIC)的小批量替代品,但是近年来在微软、百度等公司的数据中心大规划布置,以一起供给强壮的核算才能和满足的灵活性。
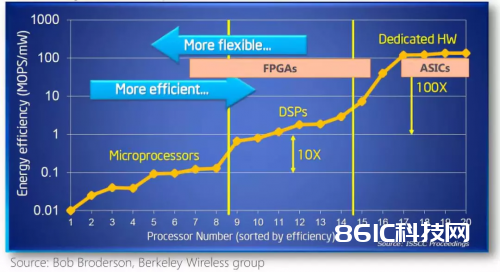
▲不同体系结构功能和灵活性的比较
FPGA 为什么快?「都是同行烘托得好」。
CPU、GPU 都归于冯·诺依曼结构,指令译码履行、同享内存。FPGA 之所以比 CPU 乃至 GPU 能效高,本质上是无指令、无需同享内存的体系结构带来的福利。
冯氏结构中,因为履行单元(如 CPU 核)或许履行恣意指令,就需要有指令存储器、译码器、各种指令的运算器、分支跳转处理逻辑。因为指令流的操控逻辑杂乱,不或许有太多条独立的指令流,因而 GPU 运用 SIMD(单指令流多数据流)来让多个履行单元以相同的步骤处理不同的数据,CPU 也支撑 SIMD 指令。
而 FPGA 每个逻辑单元的功能在重编程(烧写)时就现已确认,不需要指令。
冯氏结构中运用内存有两种效果。一是保存状况,二是在履行单元间通讯。
因为内存是同享的,就需要做拜访裁定;为了运用拜访局部性,每个履行单元有一个私有的缓存,这就要保持履行部件间缓存的一致性。
关于保存状况的需求,FPGA 中的寄存器和片上内存(BRAM)是归于各自的操控逻辑的,无需不必要的裁定和缓存。
关于通讯的需求,FPGA 每个逻辑单元与周围逻辑单元的衔接在重编程(烧写)时就现已确认,并不需要经过同享内存来通讯。
说了这么多三千英尺高度的话,FPGA 实践的体现怎么呢?咱们别离来看核算密集型使命和通讯密集型使命。
核算密集型使命的比如包含矩阵运算、图画处理、机器学习、紧缩、非对称加密、Bing 查找的排序等。这类使命一般是 CPU 把使命卸载(offload)给 FPGA 去履行。对这类使命,现在咱们正在用的 Altera(好像应该叫 Intel 了,我仍是习气叫 Altera……)Stratix V FPGA 的整数乘法运算功能与 20 核的 CPU 根本适当,浮点乘法运算功能与 8 核的 CPU 根本适当,而比 GPU 低一个数量级。咱们行将用上的下一代 FPGA,Stratix 10,将装备更多的乘法器和硬件浮点运算部件,然后理论上可到达与现在的尖端 GPU 核算卡旗鼓适当的核算才能。

▲FPGA 的整数乘法运算才能(估量值,不运用 DSP,依据逻辑资源占用量估量)
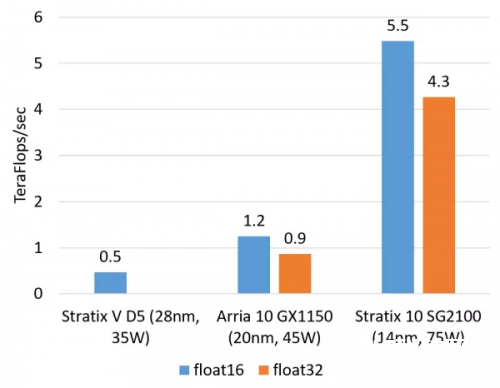
▲FPGA 的浮点乘法运算才能(估量值,float16 用软核,float 32 用硬核)
在数据中心,FPGA 比较 GPU 的中心优势在于推迟。
像 Bing 查找排序这样的使命,要尽或许快地回来查找成果,就需要尽或许下降每一步的推迟。
假如运用 GPU 来加快,要想充分运用 GPU 的核算才能,batch size 就不能太小,推迟将高达毫秒量级。
运用 FPGA 来加快的话,只需要微秒级的 PCIe 推迟(咱们现在的 FPGA 是作为一块 PCIe 加快卡)。
未来 Intel 推出经过 QPI 衔接的 Xeon + FPGA 之后,CPU 和 FPGA 之间的推迟更可以降到 100 纳秒以下,跟拜访主存没什么区别了。