选用通用微处理器完结暗码算法尽管灵敏性好,但功用欠安,完结速度也较慢。而选用专用ASIC针对特定暗码算法进行加快,灵敏性不高。RISC结构暗码专用微处理器规划是面向通用微处理器与高效暗码处理器的结合,在RISC结构中整合了一个暗码运算单元,而且这些运算单元是根据可重构的,对它装备不同的信息能够完结不同的算法,该运算单元与算术运算单元ALU并行作业,并拜访同一个寄存器文件[1]。RISC体系结构作为计算机规划战略的一品种型己愈来愈多地运用于计算机的体系规划中。RISC结构的指令体系中,选用许多的寄存器——寄存器操作指令,但只要load/store指令能够拜访内存。从内存中取出的数据要送到寄存器,在寄存器之间对数据进行快速处理,然后避免了因为频频拜访内存而下降履行速度[2]。RISC指令寻址形式和指令操作都相对简略,这尽管有利于简化微结构完结,但是在进行许多数据流处理特别是暗码运算时,因为它需求存储较多的数据,所以有必要频频地运用load/store指令操控数据的进出,这需求占用较多的指令和较多的时钟周期。因而,针对上述问题,本文在32位RISC暗码专用微处理器中规划了一个专用存储单元用来寄存暗码运算的相关数据,在暗码运算时能够对其直接拜访,大大削减了指令条数,进步了暗码运算功率。
1 运用剖析
经过对DES、RIJNDAEL、SERPENT、RC6、IDEA等分组暗码算法的剖析,许多不同分组暗码算法具有相同或类似的根本操作运算,或者说,同一根本操作运算在不同的算法中呈现的频率也不相同,如表1所示。
在表1所示常见操作中:S盒改换需求用到查找表LUT数据,算法不同,S盒查找表的巨细也不相同,例如,DES是8个6~4的查找表,AES是1个8~8的查找表;位置换操作需求用到相关的操控信息,不同的置换其操控信息也不相同,例如,DES算法就用到了六种置换的操控信息;有限域乘法运算中需求对不行约多项式和乘数多项式进行装备;暗码运算中还有密钥及运算生成的子密钥数据。由此可见,暗码运算中需求存储许多的不同类型的数据,每种数据的存储量巨细也各不相同。这就决议了根据RISC结构的暗码专用微处理器需求具有较灵敏的存储结构。
因而,为了进步暗码运算的履行功率,在暗码微处理器中能够规划一个内部的专用存储单元,用来存储密钥和一些特定的装备数据。对专用存储单元的拜访要结合暗码运算单元的特色才干具有较好的灵敏性。因而在本规划中,微处理器完结暗码运算时运用专用存储单元,而完结其他运算时则运用数据存储器。这样,既具有了其专用性又保留了其通用性,能够高效地完结暗码算法[3]。
2 专用存储单元的规划
2.1 全体结构
暗码专用微处理器在支撑原load指令和store指令拜访数据存储单元的基础上,硬件上又参加了专用存储单元的拜访逻辑。专用存储单元与数据存储单元别离独登时存储相应的数据,这样就削减了许多RISC结构中难以避免的寄存器与存储单元交流数据的指令[4]。暗码专用微处理器的全体结构如图1所示。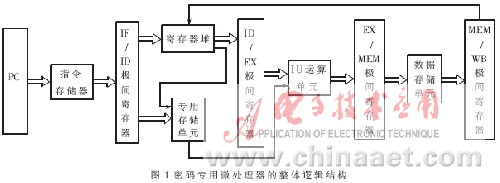
专用存储单元放置于IF/ID极间寄存器之后,在进行暗码运算时,操作数从寄存器堆中取出,关于暗码运算的装备信息,则从专用存储单元中取出直接进入IU运算单元完结装备。
专用存储单元共分为三个模块:S盒模块、密钥模块、bit置换和有限域模块,每一个模块又由一些地址位宽和数据位宽各不相同的RAM组成,如图2所示。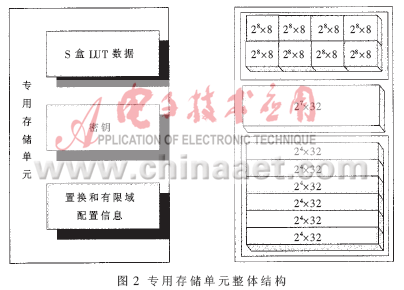
图2中,寄存S盒LUT数据部分由8个28×8的RAM构成,寄存密钥部分由1个27×32的RAM构成,寄存置换和有限域装备信息部分由6个24×32的RAM构成。三个存储模块一致编址,关于S盒存储模块前2bit进行译码,后8bit进行寻址;关于密钥存储模块前3bit进行译码,后7bit进行寻址;关于存储置换和有限域模块,前6bit进行译码,后4bit进行寻址。拜访专用存储单元时由Opcode及指令字中其他字段参加译码来操控对不同数据的拜访。
2.2 S盒存储模块
经过对DES、AES、IDEA等41种分组暗码算法剖析可知,有30种算法运用了S盒替代操作,合计十种不同类型的S盒,十种S盒中为二种以上不同算法所运用的仅有4×4、6×4、8×8、8×32 四种S盒,其他六种不同类型的S盒查表操作能够选用以上四种S盒查表操作或逻辑运算完结[5]。本规划的S盒完结办法是根据查找表LUT(Look Up Table)的完结办法,将S盒查找表存储在RAM中,操作数作为读地址。这种办法占用较多存储单元,但运算速度快,最主要的是它具有可装备性,能满意当时多种暗码运算的需求,而且不进行装备时它自身不带有任何算法信息,使得自身更具有安全性。S盒电路结构如图3所示。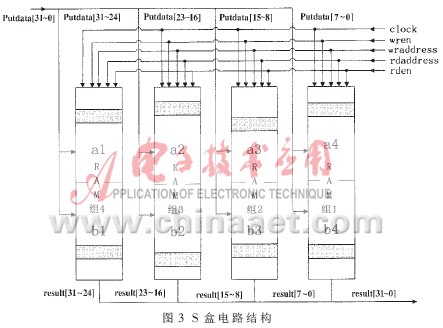
S盒替代电路在规划上考虑支撑8×8、8×32、4×4、6×4四种查表形式,选用RAM组的规划办法,为支撑32bit的数据途径,选用了4个双端口28×8的RAM组并联电路,即2个28×8的RAM构成一个RAM组。
2.3 密钥存储模块
密钥存储模块是由一个27×32的RAM组成,经过对如表2所示的多种分组暗码算法密钥容量的计算和剖析可知,深度为128的存储容量能够满意暗码运算中密钥的存储要求。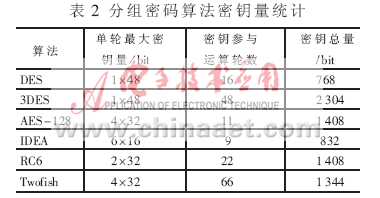
在AES算法中每轮要进行轮密钥加,即“异或”运算;在DES算法中,密钥要进行64位减至56位的置换,然后每一轮都要进行移位和紧缩置换;在IDEA算法中,在每一轮运算中其子密钥要进行屡次的“异或”、模加、模乘。可见密钥或子密钥在暗码运算中参加了多种运算。为了削减硬件规划的复杂度,本规划将取出的密钥放入寄存器堆中,以便能灵敏地和其他数据进行各种运算。
2.4 置换及有限域存储模块
置换作为分散的首要手法,在暗码算法中得到了广泛运用。例如:在DES中有六种不同品种的置换;Twofish和Serpent中有两种不同品种的置换。本规划的bit置换单元是根据64×64的omega-flip网络,该网络共有11级,在进行数据置换之前,要先对每一级的开关逻辑进行装备。一级omega-flip网络需求N/2bit(即32bit)操控信息决议该级开关的状况(穿插或直通),所以该置换网络进行一次置换需求11个操控信息。假如用通用指令完结这些操控信息,则至少需求6条指令才干完结装备。
分组暗码运用中,有限域乘法运算主要在GF(28)、GF(27)及GF(29)域上。其间,在GF(28)域上的乘法运算最为常见,占到了悉数有限域乘法的54.14%。有限域乘法电路运算前需求对乘数多项式和不行约多项式进行静态装备,每组136bit,其间128bit为乘法矩阵装备数据,8bit作为不行约多项式装备数据。
由以上剖析可知,本规划的bit置换和有限域模块由6个24×32的RAM组成,它一次能够寄存六种置换所需求的操控信息,四种有限域运算所需的128bit乘法矩阵装备数据和8bit不行约多项式装备数据。6个RAM都是双端口(即2个读端口),所以给出2个相同的读地址,6个RAM就能够一起读出12个装备数据。64位的bit置换一次需求的11个操控信息只用一条指令就能够完结装备,大大进步了暗码运算速度。
2.5指令规划
暗码专用微处理器扩展了指令集,增加了暗码指令。参加专用存储单元后,因为专用存储单元寄存的主要是装备数据,结合运算单元的特色,在扩展的专用暗码指令中对原指令格局进行了改善,使之更适合于暗码算法。改善后该指令字中的低11位被作为5位的shift域和6位的func域,其指令格局如表3所示。三个模块的数据都由CONFIGURE指令存储到专用存储单元中,密钥和S盒能够直接参加运算,关于置换和有限域乘法,在其暗码运算指令的shift域中增加专用存储单元的地址,运算时再将装备信息动态装备到IU运算单元中,这样装备和运算用一条指令就能够完结。
表3中:Op为操作码,Rd为意图寄存器地址,Rs1和Rs2为源寄存器地址。type(1)作为区别bit置换和有限域。addr(4)为置换和有限域模块4bit地址,该4bit地址与该地址加1为bit置换和有限域模块6个RAM的2个读地址,读出的数据直接送入运算单元内部对相应模块进行装备。sboxtype(2)2bit为S盒类型挑选,用来区别8×8、8×32、4×4及6×4四种S盒。Sboxa/b(1)这1bit是拜访S盒时用来挑选RAM组a或RAM组b。
3 功用剖析
指令条数是影响功用的关键因素,规划专用暗码处理指令的意图便是削减完结过程中的指令条数。因为本规划所根据指令的CPI都为1,故能够经过算法所需的指令数来反映体系处理明文的功率。表4给出了与其他两种处理器所需指令条数的比照状况,表中的I386为32位指令编码的通用处理器,PVCP[6]为国防科技大学研发的一款向量结构的暗码处理器。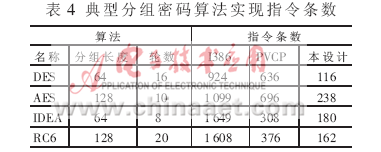
从表4能够看出,本规划的指令条数与通用处理器指令条数比较削减了78%~90%,与功用类似的向量处理器比较,指令条数也削减了许多。
经过对RISC结构进行研究能够发现,寄存器—寄存器的指令特性极大地下降了微处理器对许多存储器中数据的处理功率。因而,结合暗码运算的特色及体系需求,本规划将要点放在RISC结构暗码专用微处理器在完结暗码算法过程中怎么削减指令条数上。本文在RISC暗码专用微处理器中参加了专用存储单元,用来存储和暗码处理相关的数据,如密钥、S盒运算中的LUT数据、有限域乘法中的装备数据及bit置换所用到的操控信息,并扩展和改善了其相应的指令集,削减了指令条数,进步了运算功率。