本文介绍了根据ARMv7架构的Cortex-A8芯片(FreeScale i.MX51 / i.MX53/QualComm msm8x50 / msm7x30/Samsung s5pc100 / s5pc110/TI omap 3430 / omap 3730芯片)上选用C言语、ARM汇编和NEON汇编完成的memcpy的功能比照,并输入剖析了NEON指令(不同处理器的NEON内存位宽从64-bit到128-bit不等)和cache的预取preload(preload engine指令)对功能的影响。终究定论标明1.在复制块巨细block size = 512B ~ 32K之间,有一个功能高台,block size = 256K也有一个功能的转机。这个特性体现了芯片32KB L1 / 256KB L2 cache的影响;2. NEON指令的功能总是要高于ARM指令的功能。跟着开展ARM/NEON指令之间功能差在缩小。替换运用ARM/NEON指令,功能往往要差于NEON版别;3.假如没有很好的模型规划,软件去干涉cache的运用,很简略会形成功能的恶化; 4.在fit in cache条件下,Snapdragon渠道有最好的功能; 5.在out of cache条件下,s5pc110有最好的功能; 6.在同一个硬件渠道下,超频对memory功能影响很小; 7.同一种的完成,在不同的硬件渠道上都有不同的体现。没有一种完成在一切渠道上是最好的。
-
前语
在C run time library中,memcpy是重要的函数,对运用软件的功能有着重要的影响。ARM芯片开展到Cortex-A8[1][2]架构,不光频率有了很大进步,并且架构规划有了很大地改善。其间添加的NEON指令,是类似于原先X86渠道下的MMX指令,是为多媒体而规划。但由于这类指令一次能够处理64-bit数据,对memcpy函数功能进步也很有协助。本文首要是测验选用NEON[2]指令的多种memcpy完成,讨论NEON指令和预取(preload)指令对功能的影响,以及在芯片优化和工艺前进后,这些影响的改变趋势。一起希望芯片规划人员在了解软件完成的基础上,给予一个知其然,也知其所以然的解说,从而辅导进一步进步功能的方向。
-
渠道介绍
本次的测验渠道来源于笔者作业项目中接触到的Cortex-A8渠道。见下面列表:
- FreeScale i.MX51 / i.MX53
- QualComm msm8x50 / msm7x30
- Samsung s5pc100 / s5pc110
- TI omap 3430 / omap 3730
-
i.MX5 family
i.MX5 family的介绍见[6][7]。其间i.MX535能够运转在800MHZ / 1000MHZ两种频率上。
-
i.MX515
- freq: 800MHZ
- cache size: 32KB/32KB I/D Cache and 256KB L2 Cache
- cache line: 64-bit wide(NEON), 64-byte / line
- i.MX535
- freq: 800MHZ / 1000MHZ
- cache size: 32KB/32KB I/D Cache and 256KB L2 Cache
- cache line: 64-bit wide(NEON), 64-byte / line
-
Snapdragon family
Snapdragon的介绍见[8][9][10]。其间msm7x30能够运转在800MHZ / 1000MHZ两种频率上。此外Snapdragon cache特别之处是128-bit wide(NEON), 128-byte / line。规范Cortex-A8中,该数值为64-bit wide(NEON), 64-byte / line。这对功能有较大影响。
-
msm8x50
- freq: 1000MHZ
- cache size: 32KB/32KB I/D Cache and 256KB L2 Cache
- cache line: 128-bit wide(NEON), 128-byte / line
-
msm7x30
- freq: 800MHZ / 1000MHZ
- cache size: 32KB/32KB I/D Cache and 256KB L2 Cache
- cache line: 128-bit wide(NEON), 128-byte / line
-
s5pc family
s5pc family参阅渠道见[11]。
-
s5pc100
- freq: 665MHZ
- cache size: 32KB/32KB I/D Cache and 256KB L2 Cache
- cache line: 64-bit wide(NEON), 64-byte / line
-
s5pc110
- freq: 1000MHZ
- cache size: 32KB/32KB I/D Cache and 512KB L2 Cache
- cache line: 64-bit wide(NEON), 64-byte / line
-
omap3 family
omap3 family参阅渠道见[12][13][14]。
-
omap3430
- freq: 550MHZ
- cache size: 16KB/16KB I/D Cache and 256KB L2 Cache
- cache line: 64-bit wide(NEON), 64-byte / line
-
omap3730
- freq: 1000MHZ
- cache size: 32KB/32KB I/D Cache and 256KB L2 Cache
- cache line: 64-bit wide(NEON), 64-byte / line
-
memcpy完成介绍
memcpy的完成在ARM渠道上的开展有3类版别:
- C言语版别
- ARM汇编版别
-
NEON汇编版别
ARM公司的文档[4]对memcpy的完成有很好描绘。有人[5][19][20]还进一步论述了完成原理和技巧。简述如下:
- NEON指令一次能够处理64-bit数据,功率更高。
- NEON架构与L1/L2 cache都有直连,在OS层级enable后,能够取得更好的功能。
- ARM / NEON的pipeline有或许异步处理,替换运用ARM / NEON指令有或许取得更好的功能。
- 在一次循环中,竭尽或许多的寄存器copy更多的数据,确保pipeline有更好的功率。现在一次最大处理块为128-byte。
-
对cache的操作有考究。
- memcpy归于一次扫瞄无回溯的操作,关于cache选用预取(preload)战略能够进步hit rate。所以汇编版别中一定会运用pld指令提示ARM预先把cache line填充好。
- pld指令中的offset很有考究。一般为64-byte的倍数。在ARMv5TE渠道是一个循环用一个pld指令。在Cortex-A8渠道上速度更快,需求一个循环用2~3个pld指令填充cache line。这样一个循环消费2~3个时钟周期换得cache hit rate进步,作用是值得的。
- 进一步的,Cortex-A8架构供给了preload engine指令,能够让软件更深地影响cache,以便让cache hit rate得到进步。不过要在用户空间运用ple指令,需求在OS中打补丁敞开权限。
-
C言语版别
C言语版别首要是做比照。选用两个完成:
- 32-bit wide copy。后边标记为in32_cpy。
-
16-byte wide copy。后边标记为vec_cpy。这个完成的技巧是选用gcc的向量扩展”__attribute__ ((vector_size(16)))”,在C言语层级完成16-byte wide copy,将详细完成交给编译器。
值得注意的工作是,编译器不会自动刺进pld指令。由于编译器无法判别运用对内存的拜访形式。
-
ARM汇编版别
ARM汇编版别也首要是做比照。选用两个完成:
- Siarhei Siamashka完成[15]。后边标记为arm9_memcpy。他是为Nokia N770做的优化。
- Nicolas Pitre完成[16]。后边标记为armv5te_memcpy。这是现在glibc里边缺省的arm memcpy完成。
-
NEON汇编版别
NEON汇编版别选用四个完成:
- M?ns Rullg?rd完成[19]。这是一个128-byte-align block的最简略的完成。没有判别不是128-byte align的状况。因而不是有用的版别。但经过这类完成,能够调查memcpy功能的极限。他一共供给4种完成。
- 全ARM汇编的完成。后边标记为memcpy_arm。此外,笔者还将其间的pld指令去掉,做为比照实验,调查pld指令的影响。后边标记为memcpy_arm_nopld。
- 全NEON汇编的完成。后边标记为memcpy_neon。此外,笔者还将其间的pld指令去掉,做为比照实验,调查pld指令的影响。后边标记为memcpy_neon_nopld。
- ARM / NEON指令替换运用的完成。后边标记为memcpy_armneon。此外,笔者还将其间的pld指令去掉,做为比照实验,调查pld指令的影响。后边标记为memcpy_armneon_nopld。
- ple + NEON的完成。后边标记为memcpy_ple_neon。此外,笔者还将其间的NEON指令换成ARM指令,做为比照实验,调查ple指令对ARM/NEON指令的影响。后边标记为memcpy_ple_arm。由于这个完成需求对linux kernel打补丁,在omap3430渠道上没有成功。在Snapdragon渠道上替换kernel有些费事,所以也没有测验。
- CodeSourcery完成[17]。这是CodeSourcery toolchain中的glibc里边的完成。也分两种完成。
- ARM完成。后边标记为memcpy_arm_codesourcery。笔者还将其间的pld指令去掉,做为比照实验,调查pld指令的影响。后边标记为memcpy_arm_codesourcery_nopld。
- NEON完成。后边标记为memcpy_neon_codesourcery。这也是Android bionic里边选用的NEON完成。笔者还将其间的pld指令去掉,做为比照实验,调查pld指令的影响。后边标记为memcpy_neon_codesourcery_nopld。
- QualComm完成[18]。后边标记为memcpy_neon_qualcomm。这是QualComm在Code Aurora Forum中为Snapdragon渠道开发的优化版别。首要是对8660/8650A渠道的优化。这个版别的特点是针对L2 cache line size=128bytes而规划,pld offset设置得特别大。成果在其它Cortex-A8渠道上没有作用。所以笔者将pld offset改为M?ns Rullg?rd完成的数值。笔者还将其间的pld指令去掉,做为比照实验,调查pld指令的影响。后边标记为memcpy_neon_qualcomm_nopld。
- Siarhei Siamashka完成[20]。后边标记为memcpy_neon_siarhei。这是Siarhei Siamashka向glibc提交的NEON版别,没有被glibc选用。但是在MAEMO项目中得到选用。这个版别的特点是pld offset是从小到大添加的,以希望习惯block size的改变。
-
测验计划介绍
测验计划非常简略。参阅了movial memory tester的完成[21]。履行过程如下:
- 先对每个完成进行正确性的验证。首要办法是以随机的block size & offset,填充随机的内容,然后履行memcpy操作,然后再用体系的memcmp函数对两块内存做校验。
- 然后对每个完成以不同的block size调用400次。假如total copy size < 1MB,则添加count直到满足要求。对总操作计时。
-
以total copy size / total copy time公式核算memcpy bandwidth。
上述说到的block size = 2^n ( 7 <= n <= 23 )。
此外,这个测验程序运转在openembedded-gpe软件体系中。QualComm / Samsung硬件渠道只供给Android软件体系,要替换到GPE体系有些费事,则选用chroot方法进行测验。不论是哪种软件渠道,都是进入到图形体系后,静置,等候黑屏,然后再进行测验。
下表是运转环境的计算。
硬件渠道
软件环境
imx51 800MHZ
openembedded-gpe
imx53 1000MHZ
openembedded-gpe
imx53 800MHZ
openembedded-gpe
msm7230 1000MHZ
Android + chroot
msm7230 800MHZ
Android + chroot
msm8250 1000MHZ
Android + chroot
omap3430 550MHZ
openembedded-gpe
omap3730 1000MHZ
openembedded-gpe
s5pc100 665MHZ
Android + chroot
s5pc110 1000MHZ
Android + chroot
下表是测验项目的计算。
完成计划
i.MX51
i.MX53
Snapdragon
s5pc1xx
omap3430
omap3730
int32_cpy
YES
YES
YES
YES
YES
YES
vec_cpy
YES
YES
YES
YES
YES
YES
arm9_memcpy
YES
YES
YES
YES
YES
YES
armv5te_memcpy
YES
YES
YES
YES
YES
YES
memcpy_arm
YES
YES
YES
YES
YES
YES
memcpy_arm_nopld
YES
NO
YES
YES
YES
YES
memcpy_neon
YES
YES
YES
YES
YES
YES
memcpy_neon_nopld
YES
NO
YES
YES
YES
YES
memcpy_armneon
YES
YES
YES
YES
YES
YES
memcpy_ple_arm
YES
YES
N/A
YES
N/A
YES
memcpy_ple_neon
YES
YES
N/A
YES
N/A
YES
memcpy_arm_codesourcery
YES
YES
YES
YES
YES
YES
memcpy_arm_codesourcery_nopld
YES
NO
YES
YES
YES
YES
memcpy_neon_codesourcery
YES
YES
YES
YES
YES
YES
memcpy_neon_codesourcery_nopld
YES
NO
YES
YES
YES
YES
memcpy_neon_qualcomm
YES
YES
YES
YES
YES
YES
memcpy_neon_qualcomm_nopld
YES
NO
YES
YES
YES
YES
memcpy_neon_siarhei
YES
YES
YES
YES
YES
YES
注1:由于i.MX53 EVK板子发生毛病,未能测验一切no pld的测验项。
注2:在给omap3430翻开preload engine后,测验发生不合法指令错,未能测验ple的测验项。
注3:要替换Snapdragon kernel有些费事,未能测验ple的测验项。
-
测验成果与剖析
下面的图表限于页面巨细不能很好地显现细节。详细的数据和大图可到数据表文档中检查。
-
各个硬件渠道上各种完成的体现
-
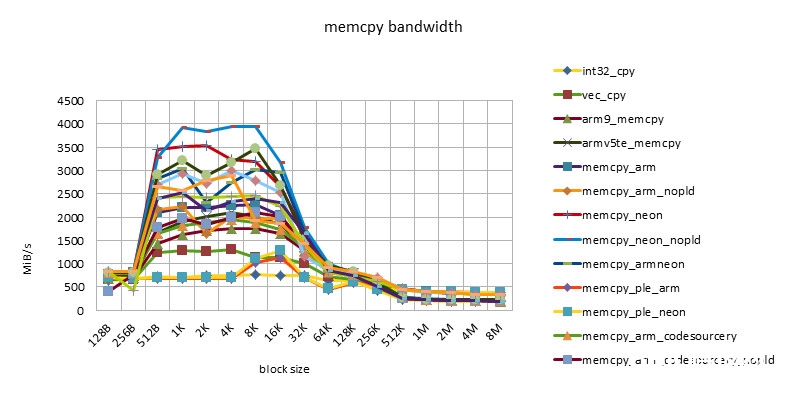
imx51 800MHZ
-
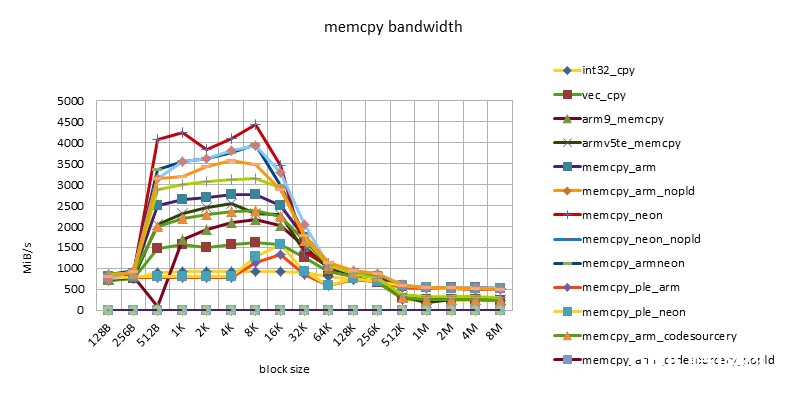
imx53 1000MHZ
-
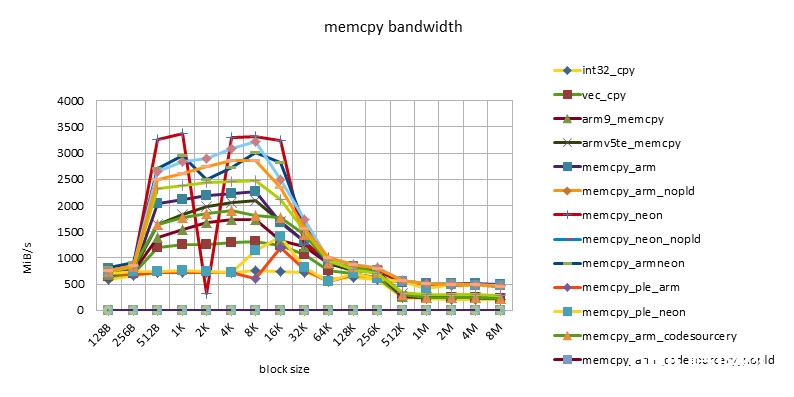
imx53 800MHZ
-
msm7230 1000MHZ

-
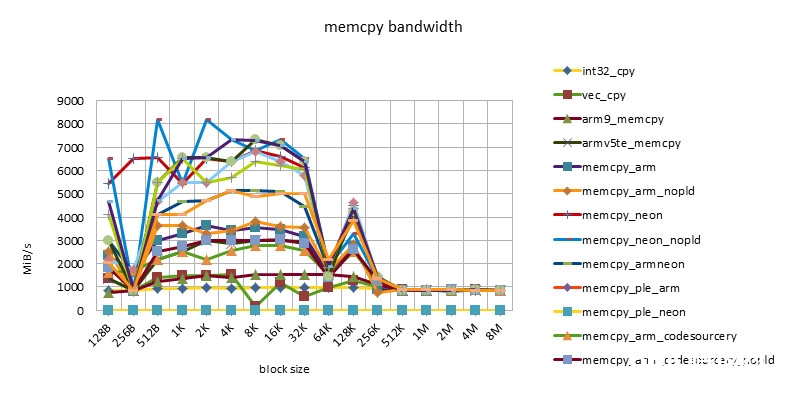
msm7230 800MHZ
-
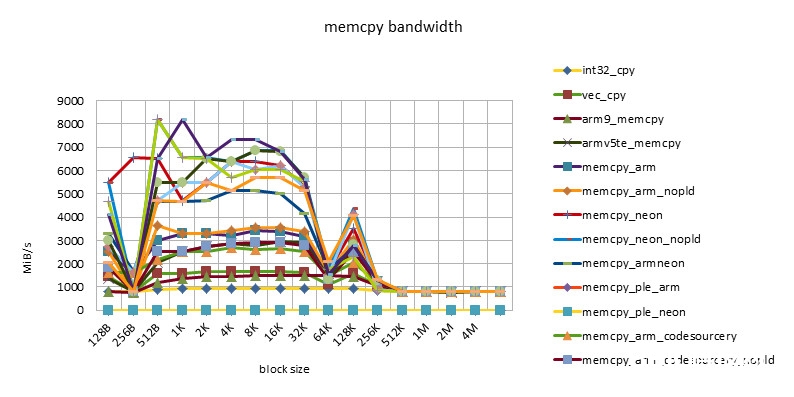
msm8250 1000MHZ
-
omap3430 550MHZ

-
omap3730 1000MHZ

-
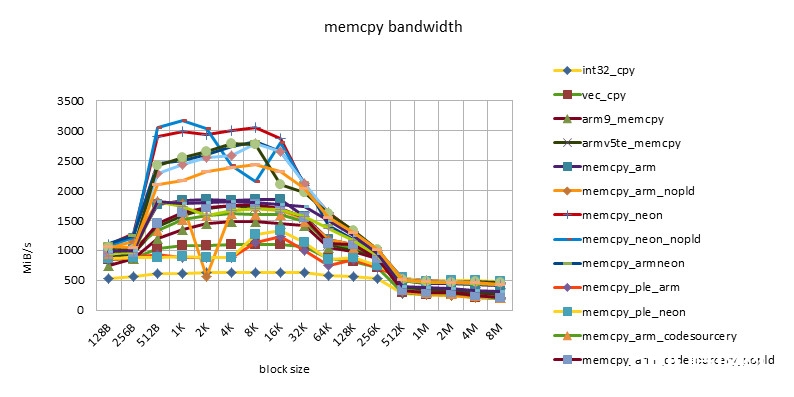
s5pc100 665MHZ
-
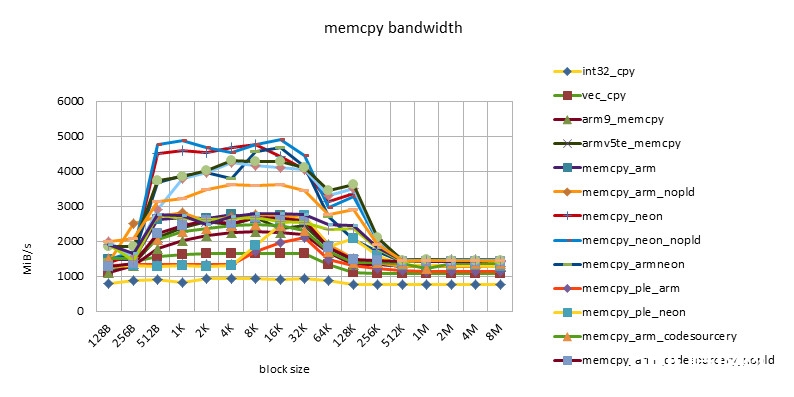
s5pc110 1000MHZ
-
小结
-
- 在block size = 512B ~ 32K之间,有一个功能高台,block size = 256K也有一个功能的转机。
- 这个特性体现了32KB L1 / 256KB L2 cache的影响。
- 小于512B的功能欠安,或许与函数调用,函数开端的块对齐技巧形成的损耗有关,也或许与block size太小,cache没有准备好函数就完毕了有关。
- 文档[]对memcpy的完成仍是有辅导意义的。但跟着芯片内部的优化和工艺的进步,有些规矩发生了改变。
- NEON指令的功能总是要高于ARM指令的功能。但替换运用ARM/NEON指令并不总是带来功能的进步。跟着开展ARM/NEON指令之间功能差在缩小。
- pld指令的作用越来越小。在较老的芯片上,如omap3430,选用pld指令后,同一个完成能够有50%的功能进步。在较新的芯片上,如msm7230/s5pc110上,功能根本没有差异,乃至同一个完成没有pld指令后,功能稍稍有些进步。这也许是由于pld指令没有作用,倒反在每个循环中浪费了时钟周期形成的。
- 选用ple指令的完成的功能令人大失人望。这也阐明假如没有很好的模型规划,软件去干涉cache的运用,很简略会形成功能的恶化。
- Snapdragon渠道有最好的cache功能。超出cache后,各种完成(包含C言语完成)的功能根本共同,也很高效。这也许是Snapdragon渠道13-stage load/store pipeline[][]的规划形成的。这个特性对高档言语是有优点的。由于编程不或许在许多当地选用汇编言语。这样开发人员就不用过多地考虑汇编优化,依靠编译器就能够了。
- s5pc110渠道有最好的均匀功能。超出cache后,NEON完成的功能最好,根本坚持一条水平线。
-
在small/big block size下各个硬件渠道的体现
功能由于block size分为fit in cache / out of cache两种体现,所以做两个剖面做比照剖析。
- 8K block size。体现fit in cache时的功能。
- 8M block size。体现out of cache时的功能。
-
M?ns Rullg?rd的完成
由于M?ns Rullg?rd的完成最简略,除了一个循环体外,没有其它判别代码,能够认为是体现渠道速度极限的完成。


-
ARM的完成
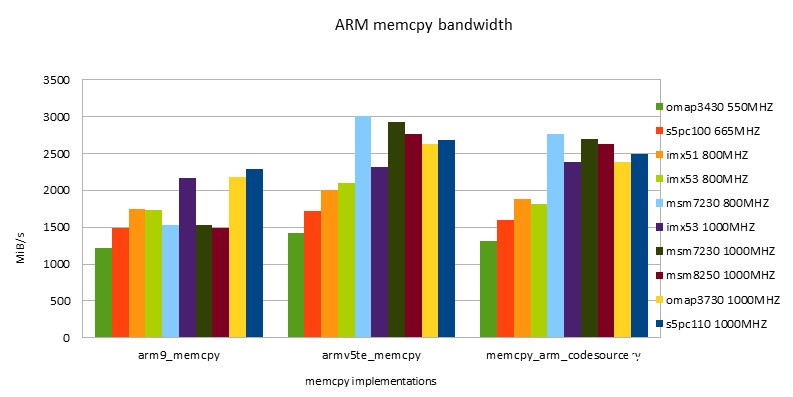
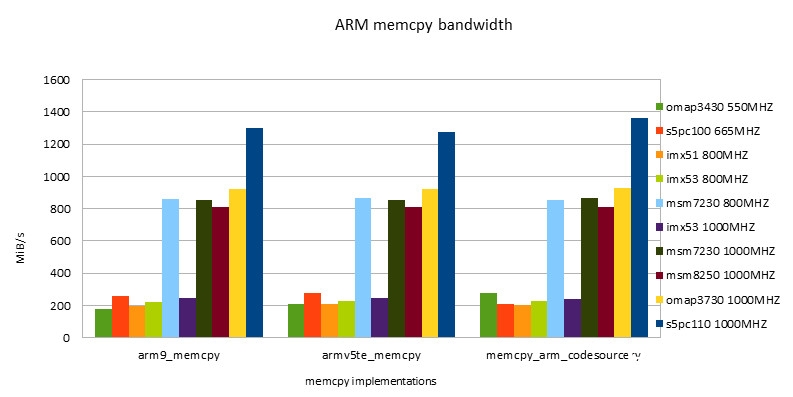
-
NEON的完成
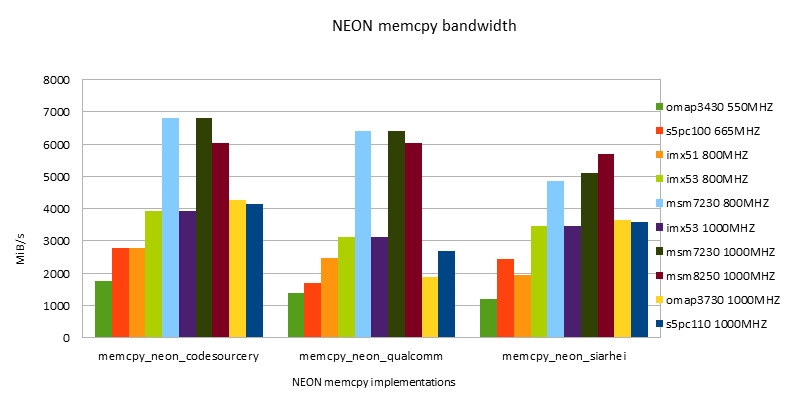
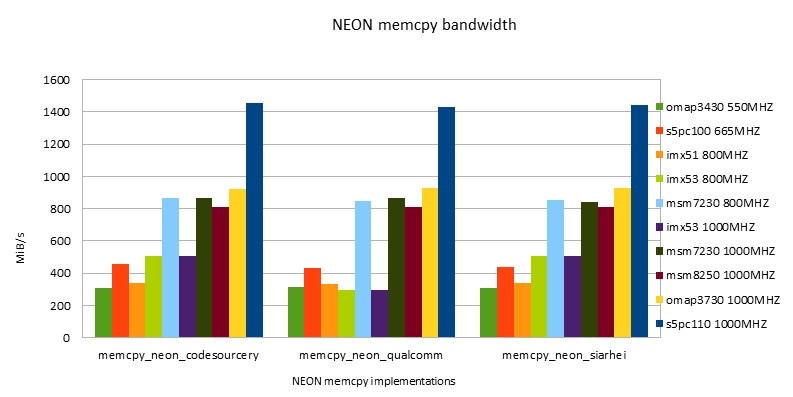
-
小结
- NEON指令的功能总是要高于ARM指令的功能。跟着开展ARM/NEON指令之间功能差在缩小。
- 替换运用ARM/NEON指令,在fit in cache条件下功能要差于NEON版别。在out of cache条件下,两个版别功能根本相同。
- 在fit in cache条件下,Snapdragon渠道有最好的功能。超越第二名s5pc110大约为43%。
- 在out of cache条件下,s5pc110有最好的功能。超越第二名omap3730大约为57%。
- 在同一个硬件渠道下,超频(如i.MX53 800/1000MHZ & msm7x30 800/1000MHZ)对memory功能影响很小。
-
有用ARM/NEON完成在各个硬件渠道的体现
经过同一种完成在不同硬件渠道上功能的比照,结合上一节的图表,能够点评一种完成的均匀功能,也便是习惯性。
-
ARM的完成
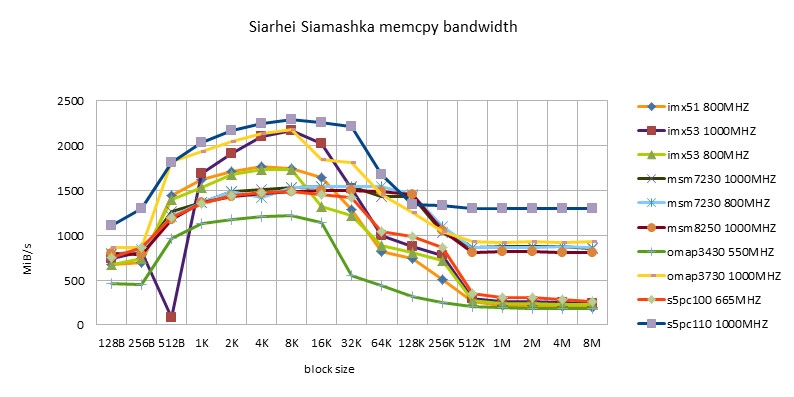

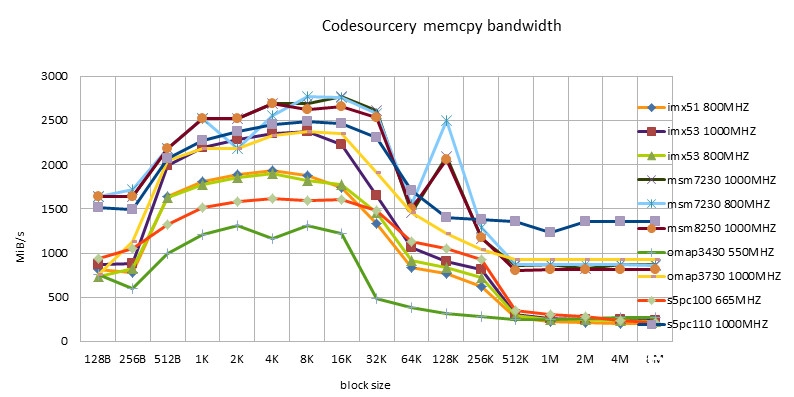
-
NEON的完成
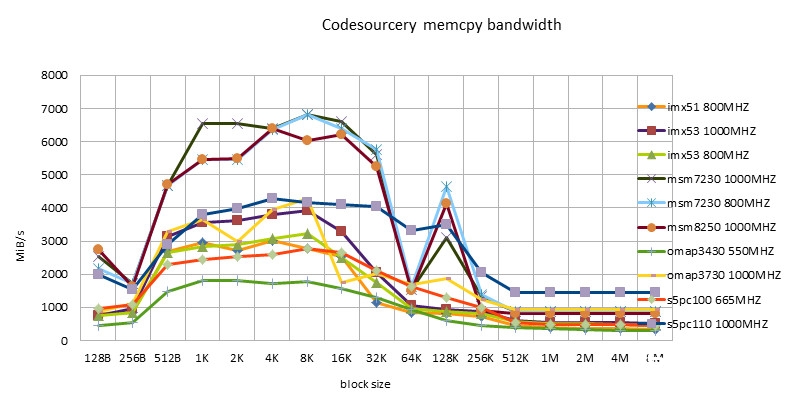


-
小结
- 同一种的完成,在不同的硬件渠道上都有不同的体现。没有一种完成在一切渠道上是最好的。
- Codesourcery版别,包含ARM/NEON版别,有很好的习惯性。不愧是做toolchain的公司。
- Siarhei Siamashka的NEON版别也有很好的习惯性。NOKIA的技能实力也很强。这哥们如同也是pixman项目里边做NEON优化的主力。
- Qualcomm版别只合适Snapdragon渠道。等待今后能在msm8660以及后续的芯片上进行测验。
-
总结
- 在block size = 512B ~ 32K之间,有一个功能高台,block size = 256K也有一个功能的转机。这个特性体现了32KB L1 / 256KB L2 cache的影响。
- NEON指令的功能总是要高于ARM指令的功能。跟着开展ARM/NEON指令之间功能差在缩小。替换运用ARM/NEON指令,功能往往要差于NEON版别。
- 假如没有很好的模型规划,软件去干涉cache的运用,很简略会形成功能的恶化。
- 在fit in cache条件下,Snapdragon渠道有最好的功能。
- 在out of cache条件下,s5pc110有最好的功能。
- 在同一个硬件渠道下,超频对memory功能影响很小。
- 同一种的完成,在不同的硬件渠道上都有不同的体现。没有一种完成在一切渠道上是最好的。
-
进一步的测验
由于在Cortex-A8系列芯片里,NEON模块是必有的。而在Cortex-A9系列芯片里,NEON模块是可选的。由于NEON模块会影响到die size,因而影响功耗和本钱。因而有些Cortex-A9芯片,如Nvidia Tegra250,没带有NEON模块。那么有无NEON模块会对软件功能形成什么样的影响呢?