在Linux体系上,一个进程有两种不同的栈,一种是用户栈,另一种是内核栈。
用户栈
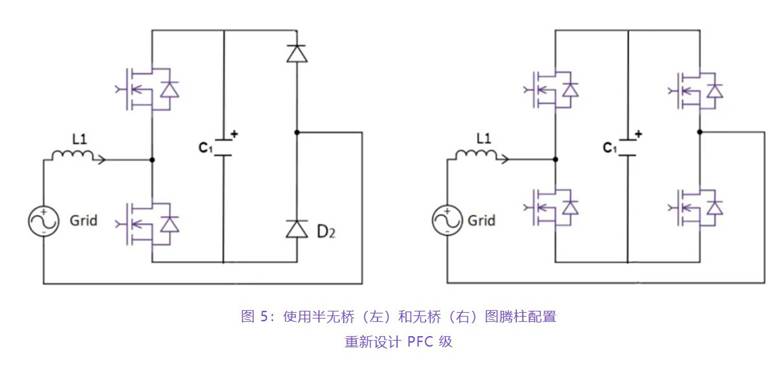
用户栈便是应用程序直接运用的栈。如下图所示,它坐落应用程序的用户进程空间的最顶端。
当用户程序逐级调用函数时,用户栈从高地址向低地址方向扩展,每次添加一个栈帧,一个栈帧中寄存的是函数的参数、回来地址和局部变量等,所以栈帧的长度是不定的。
用户栈的栈底接近进程空间的上边际,但一般不会刚好对齐到边际,出于安全考虑,会在栈底与进程上边际之间刺进一段随机巨细的阻隔区。这样,程序在每次运行时,栈的方位都不同,这样黑客就不大简略运用根据栈的安全漏洞来施行进犯。
用户栈的弹性关于应用程序来说是通明的,应用程序不需求自己去办理栈,这是操作体系供给的功用。应用程序在刚刚发动的时分(由fork()体系调用仿制出新的进程),新的进程其实并不占有任何栈的空间。当应用程序中调用了函数需求压栈时,会触发一个page fault,内核在处理这个反常里会发现进程需求新的栈空间,所以建立新的VMA并映射内存给用户栈。
内核栈
内核栈关于应用程序是不行见的,由于它坐落内核空间中。在应用程序履行过程中,假如产生反常、中止或体系调用的话,应用程序会被暂停,体系进入内核态,转去履行反常呼应等代码,这个时分所运用的栈便是内核栈。
与用户栈比较,内核栈的尺度要小得多。在32位Linux体系上,用户栈最多能够扩展到64M,但内核栈最多也只需8K字节,并且有时为了进步内存运用率还常常把内核栈装备成4K。其实即使是只需4K,在绝大多数状况下也仍然是够用的,由于这儿仅仅给内核代码运用的,栈不会很大。
每个进程在内核空间中都具有一个对应的内核栈,并且这个栈是在进程fork的时分就预留出来的。以下是创立内核栈的代码(Kernel 2.6.35 版别):
[c]static struct task_struct *dup_task_struct(struct task_struct *orig){struct task_struct *tsk;struct thread_info *ti;......ti = alloc_thread_info(tsk);......tsk->stack = ti;......}[/c]
内核栈的结构比较精巧,内核运用一个联合体来界说内核栈:
[c]union thread_union {struct thread_info thread_info;unsigned long stack[THREAD_SIZE/sizeof(long)];};[/c]
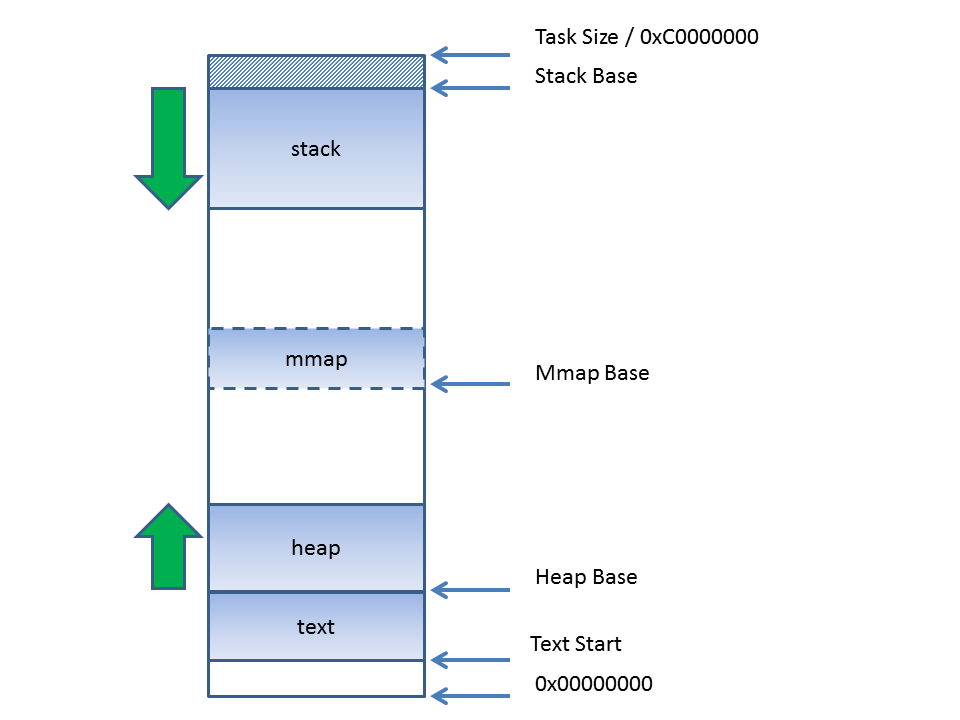
其间thread_info中寄存了进程/线程(内核不大区别进程与线程)的一些数据,其间包含指向task_struct结构的指针。数组stack即内核栈,stack占有8K/4K(依装备不同)空间,是这个联合体的首要部分。
这样,一个实践的内核栈的结构将如下图所示。由于栈总是由高地址向低地址延伸的,所以栈底坐落thread_union联合体的最末端,而thread_info结构则坐落thread_union联合体的开端处,并且所占用的空间比较少。只需不呈现内核栈特别大的极点状况,栈与thread_info能够互不搅扰。
为什么要规划成这样的结构呢?原因就在于,运用这种结构能够在体系进入内核态时很方便地获得其时进程的信息。假如不必这种方法的话,获得task_struct将是一个比较费事的作业。
不论体系由于什么原因进入内核态,最终都要切换到SVC形式做首要的反常处理。在进入SVC形式时,SP/R13寄存器所指向的方位就正好是其时进程的内核栈。经过简略的对齐操作,就能够拿到thread_union即thread_info结构的指针,从中又能够得到最重要的task_struct的指针,这个进程的一切信息就都有了。
以下两个函数即别离用于从SP寄存器获得其时进程的thread_info,以及进一步获得task_struct结构的内容。
[c]static inline struct thread_info *current_thread_info(void){register unsigned long sp asm ("sp");return (struct thread_info *)(sp & ~(THREAD_SIZE - 1));}static inline struct task_struct *get_current(void){return current_thread_info()->task;}[/c]
关于SP寄存器,这儿有一个问题值得弄清一下,前面说到“在进入SVC形式时,SP/R13寄存器所指向的方位就正好是其时进程的内核栈”,原因是什么呢?
在其时进程即其时被反常或中止所暂停的这个进程,是在上一次产生进程调度(schedule())的时分被调入的,其时在“上下文切换”(context_switch())完结的时分,其时这个进程能够说现已被调入了CPU,体系其时所在的形式也是SVC形式。当进程高度完结,CPU从SVC形式切换到USR形式时分,SVC形式下的SP寄存器现已指向了其时进程的内核栈。所以当再次切换到SVC形式时,进程仍是这个进程,SP也仍是指向这个内核栈。
其实ARM处理器的每一种形式下都有自己独立的SP/R13寄存器。当CPU在不同的形式间切换的时分所看到的寄存器内容都是不同的。Linux关于各种形式的运用战略是:SVC和USR两种形式是能够安稳作业的形式;在其它的形式下都是不安稳的,会赶快切换到安稳的形式去作业。在SVC形式下,SP寄存器总是指向内核栈;在USR形式下,SP寄存器总是指向用户栈;那么,其它形式下,SP又指向哪里呢?
其它形式下,Linux关于SP寄存器的保护很简略。在体系发动阶段,cpu_init()函数会被调用,其间有对其它形式下SP寄存器的初始化操作:
[c]struct stack {u32 irq[3];u32 abt[3];u32 und[3];} ____cacheline_aligned;static struct stack stacks[NR_CPUS];void cpu_init(void){unsigned int cpu = smp_processor_id();struct stack *stk = &stacks[cpu];__asm__ ("msr cpsr_c, %1\n\t""add r14, %0, %2\n\t""mov sp, r14\n\t""msr cpsr_c, %3\n\t""add r14, %0, %4\n\t""mov sp, r14\n\t""msr cpsr_c, %5\n\t""add r14, %0, %6\n\t""mov sp, r14\n\t""msr cpsr_c, %7":: "r" (stk),PLC (PSR_F_BIT | PSR_I_BIT | IRQ_MODE),"I" (offsetof(struct stack, irq[0])),PLC (PSR_F_BIT | PSR_I_BIT | ABT_MODE),"I" (offsetof(struct stack, abt[0])),PLC (PSR_F_BIT | PSR_I_BIT | UND_MODE),"I" (offsetof(struct stack, und[0])),PLC (PSR_F_BIT | PSR_I_BIT | SVC_MODE): "r14");}[/c]
能够看到,Linux为IRQ\ABT\UND3种形式的SP寄存器指定了相应的栈,可是这个栈很小很小,只需12个字节。但这现已足够了,在中止处理开始那部分相应形式的代码vector_XXX中,linux只保存r0, lr和spsr三个32位的数据,这正好需求12个字节。