近来,在深度学习范畴呈现了一场火热的争辩。这一切都要从Jeff Leek在Simply Stats上宣布了一篇题为 《数据量不够大,别玩深度学习》 (Don't use deep learning your data isn't that big)的博文开端。作者Jeff Leek在这篇博文中指出,当样本数据集很小时(这种状况在生物信息范畴很常见),即便有一些层和躲藏单元,具有较少参数的线性模型的体现是优于深度网络的。为了证明自己的观念,Leek举了一个依据MNIST数据库进行图画识别的比如,分辩0或许1。他还标明,当在一个运用仅仅80个样本的MNIST数据会集进行0和1的分类时,一个简略的线性猜想器(逻辑回归)要比深度神经网络的猜想准确度更高。
这篇博文的宣布引起了范畴内的争辩,哈佛大学药学院的生物医药信息学专业博士后Andrew Beam写了篇文章来辩驳: 《就算数据不够大,也能玩深度学习》 (You can probably use deep learning even if your data isn't that big)。Andrew Beam指出,即便数据集很小,一个恰当练习的深度网络也能打败简略的线性模型。现在,越来越多的生物信息学研讨人员正在运用深度学习来处理各式各样的问题,这样的争辩愈演愈烈。这种炒作是真的吗?仍是说线性模型就满意满意咱们的一切需求呢?定论自始自终——要视状况而定。在这篇文章中,作者探究了一些机器学习的运用实例,在这些实例中运用深度学习并不正确。而且解说了一些对深度学习的误解,作者以为正是这些过错的知道导致深度学习没有得到有用地运用,这种状况关于新手来说特别简略呈现。
打破深度学习成见
首要,咱们来看看许多外行者简略发生的成见,其实是一些半真半假的片面知道。首要有两点,其间的一点更具技术性,我将详细解说。
深度学习在小样本集上也可以取得很好的效果
深度学习是在大数据的布景下火起来的(第一个谷歌大脑项目向深度神经网络供给了许多的Youtube视频),自从那以后,绝大部分的深度学习内容都是依据大数据量中的杂乱算法。
可是,这种大数据+深度学习的配对不知为何被人误解为:深度学习不能运用于小样本。假如只要几个样例,将其输入具有高参数样本份额的神经网络好像一定会走上过拟合的路途。可是,仅仅考虑给定问题的样本容量和维度,不管有监督仍是无监督,简直都是在真空中对数据进行建模,没有任何的上下文。或许的数据状况是:你具有与问题相关的数据源,或许该范畴的专家可以供给的强壮的先验常识,或许数据可以以十分特别的办法进行构建(例如,以图形或图画编码的办法)。一切的这些状况中,深度学习有时机成为一种可供挑选的办法——例如,你可以编码较大的相关数据集的有用标明,并将该标明运用到你的问题中。这种典型的示例常见于自然言语处理,你可以学习大型语料库中的词语嵌入,例如维基百科,然后将他们作为一个较小的、较窄的语料库嵌入到一个有监督使命中。极点状况下,你可以用一套神经网络进行联合学习特征标明,这是在小样本会集重用该标明的一种有用办法。这种办法被称作“一次性学习”(one-shot learning),而且现已成功运用到包含 核算机视觉 和 药物研制 在内的具有高维数据的范畴。
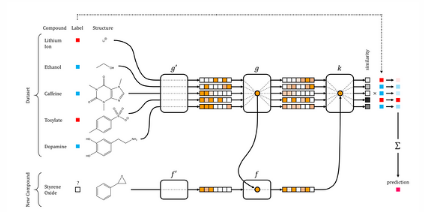
药物研制中的一次性学习网络,摘自 Altae-Tran et al. ACS Cent. Sci. 2017
深度学习不是一切的答案
我听过最多的第二个成见便是过度宣扬。许多没有入门该范畴的人,仅仅因为深度神经网络在其它范畴的超卓体现,就等待它也能为他们带来神话般的体现提高。其他人则从深度学习在图画、音乐和言语(与人类联系密切的三种数据类型)处理范畴的令人形象深入的体现中遭到启示,于是就头脑发热地钻入该范畴,刻不容缓地测验练习最新的GAN结构。当然,这种大举吹捧在许多方面是实在存在的。深度学习在机器学习中的位置不行小觑,也是数据建模办法库的重要东西。它的遍及带动了比如tensorflow和pytorch等许多重要结构的开展,它们即便是在深度学习之外也是十分有用的。失败者兴起成为超级巨星的故事鼓励了许多研讨员从头审视曾经的含糊算法,如进化算法和增强学习。但任何状况下也不能以为深度学习是全能良药。除了“天下没有免费的午饭”这点之外,深度学习模型是十分奇妙的,而且需求细心乃至十分耗时耗力的超参数查找、调整,以及测验(文章后续有更多解说)。除此之外,在许多状况下,从实践的视点来看,运用深度学习是没有意义的,更简略的模型反而能取得更好的效果。
深度学习不仅仅是
深度学习模型从机器学习的其他范畴传来时,我以为还有别的一个方面经常被疏忽。大多数深度学习的教程和介绍资料都将模型描绘为经过层次办法进行衔接的节点层组成,其间第一层是输入,终究一层是输出,而且你可以用某种办法的随机梯度下降(SGD)办法来练习网络。有些资料会简略介绍随机梯度下降是怎么作业的,以及什么是反向传达,但大部分介绍首要重视的是丰厚的神经网络类型(卷积神经网络,循环神经网络等等)。而优化办法自身却很少遭到重视,这是很不幸的,因为深度学习为什么可以起到很大的效果,绝大部分原因便是这些特别的优化办法(详细论说可以参阅Ferenc Huszár的 博客 以及博客中引证的 论文 )。了解怎么优化参数,以及怎么区分数据,然后更有用地运用它们以便在合理时间内使网络取得杰出的收敛,是至关重要的。不过,为什么随机梯度下降如此要害仍是不知道的,可是现在头绪也正零散呈现。我倾向于将该办法看成是贝叶斯推理的一部分。实质上,在你进行某种办法的数值优化时,你都会用特定的假定和先验来履行一些贝叶斯推理。其实有一个被称做 概率数值核算 (probabilistic numerics)的完好研讨范畴,便是从这个观念开端的。随机梯度下降也是如此, 最新的研讨成果 标明,该进程实践上是一个马尔科夫链,在特定假定下,可以看作是后向变分近似的稳态散布。所以当你中止随机梯度下降,并选用终究的参数时,基本上是从这个近似散布中抽样得到的。我以为这个主意很有启示性,因为这样一来,优化器的参数(这里是指学习率)就更有意义了。例如,当你添加随机梯度下降的学习参数时,马尔可夫链就会变得不稳定,直到它找到大面积采样的部分最小值,这样一来,就添加了程序的方差。另一方面,假如削减学习参数,马尔科夫链可以渐渐的近似到狭义极小值,直到它收敛,这样就添加了某个特定区域的偏置。而另一个参数,随机梯度下降的批次巨细,也可以操控算法收敛的区域是什么类型,小的批次收敛到较大区域,大的批次收敛到较小区域。

随机梯度下降依据学习速率或批尺度来挑选较大或狭义最小值
这样的杂乱性意味着深度网络的优化器十分重要:它们是模型的中心部分,与层架构相同重要。这一点在机器学习的许多其他模型中并不常见。线性模型(乃至是正则化的,像LASSO算法)以及支撑向量机(SVM) 都是凸优化问题,没有太多细微差别,而且只要一个最优解。这也便是为什么来自其它范畴的研讨人员在运用比如scikit-learn这样的东西时会感到困惑,因为他们发现找不到简略地供给.fit()函数的API(虽然现在有些东西,例如skflow,企图将简略的网络置入.fit()中,我以为这有点误导,因为深度学习的悉数要点便是其灵敏性)。
什么时候不需求深度学习
在什么状况下深度学习不是最理想的呢?在我看来,以下状况中,深度学习更多是一种阻止,而不是福音。
低预算或低出资问题
深度网络是十分灵敏的模型,有多种多样的结构和节点模型、优化器以及正则化办法。依据运用场景,你的模型或许要有卷积层(层尺度多宽?有没有池化操作?),或许循环结构(有没有门控单元?);网络或许真的很深(hourglass,siamese,或其他结构?)仍是仅仅具有很少的几个躲藏层(有多少单元?);它或许运用整流线性单元或其他激活函数;它或许会或或许不会有随机丢掉(在哪一层中?用什么份额?),而且权重应该是正则化的(L1、L2,或许是某些更古怪的正则化办法?)。这仅仅一部分列表,还有许多其他类型的节点、衔接,乃至丢失函数可以去测验。即便仅仅练习大型网络的一个实例,调整许多超参数以及探究结构的进程也是十分耗时的。谷歌最近声称自己的AutoML办法可以主动找到最好的架构,令人形象深入,但仍然需求逾越800个GPU全天候运行数周,这关于任何人来说简直都是遥不行及的。要害在于练习深度网络时,在核算和调试部分都会花费巨大的价值。这种耗费关于许多日常猜想问题并没有意义,而且调整深度网络的出资回报率太低,即便是调整小型网络。即便有满意的预算和出资,也没有理由不测验代替办法,哪怕作为基准测验。你或许会惊喜地发现,线性SVM就够用了。
解说和传达模型参数或特征对一般受众的重要性
深度网络也是很有名的黑匣子,它具有高猜想才能但可解说性缺乏。虽然最近有许多东西,比如明显图(saliency maps)和 激活差异 (activation difference),它们对某些范畴而言是十分有用的,但它们不会彻底被运用到一切的运用中。首要是,当你想要保证网络不会经过记住数据集或专心于特定的虚伪特征来诈骗你时,这些东西就能很好地作业,但仍然难以从每个特征的重要性解读出深度网络的全体决议计划。在这个范畴,没有什么可以真实地打败线性模型,因为学习得到的系数与呼应有着直接的联系。当将这些解说传达给一般受众,而且他们需求依据此做出决议计划时,这就显得尤为重要。例如,医师需求结合各种不同的数据来承认确诊成果。变量和成果之间的联系越简略、越直接,医师就能更好地运用,而不是轻视或高估实践值。此外,有些状况下,模型(特别是深度网络)的精度并不像可解说性那样重要。例如,方针制定者或许想知道一些人口统计变量关于死亡率的影响,而且相较于猜想的准确性来说,或许对这种联系的直接近似更有爱好。在这两种状况下,与更简略、更易浸透的办法比较,深度学习处于晦气位置。
树立因果机制
模型可解说性的极点状况是当咱们企图树立一个机械模型,即实践捕捉数据背面现象的模型。一个好的比如包含企图猜想两个分子(例如药物、蛋白质、核酸等)是否在特定的细胞环境中彼此发生影响,或许假定特定的营销战略是否对出售发生实践的影响。在这个范畴,依据专家定见,没有什么可以打败旧式的贝叶斯办法,它们是咱们标明并揣度因果联系的最好办法。Vicarious有一些很好的 最新研讨成果 ,阐明为什么这个更有原则性的办法在视频游戏使命中比深度学习体现得更好。
学习“非结构化”特征
这或许是具有争议性的。我发现深度学习拿手的一个范畴是为特定使命找到有用的数据标明。一个很好的比如便是上述的词语嵌入。自然言语具有丰厚而杂乱的结构,与“上下文感知”(context-aware)网络相近似:每个单词都可以经过向量来标明,而这个向量可以编码其经常呈现的文本。在NLP使命中运用在大型语料库中学习的单词嵌入,有时可以在另一个语料库的特定使命中提高效果。可是,假如所评论的语料库是彻底非结构化的,它或许不会起到任何效果。例如,假定你正在经过检查要害字的非结构化列表来对目标进行分类,因为要害字不是在任何特定结构中都会运用的(比如在一个语句中),所以单词嵌入不会对这些状况有太大协助。在这种状况下,数据是一个真实的“词袋”(bag of words),这种标明很有或许足以满意使命所需。与此相反的是,假如你运用预练习的话,单词嵌入并不是那么耗费时力,而且可以更好地捕获要害字的类似度。不过,我仍是甘愿从“词袋”标明开端,看看能否得到很好的猜想成果。究竟,这个“词袋”的每个维度都比对应的词嵌入槽更简略解读。
深度学习是未来
深度学习现在十分火爆,资金足够,而且开展反常敏捷。当你还在阅览会议上宣布的论文时,有或许现已有两、三种新版本可以逾越它了。这给我上述列出的几点提出了很大的应战:深度学习在不久的将来或许在这些情形中是十分有用的。用于解说图画和离散序列的深度学习模型的东西越来越好。最近推出的软件,如 Edward 将贝叶斯建模和深度网络结构结合,可以量化神经网络参数的不确定性,以及经过概率编程和主动变分推理进行简易贝叶斯推理。从长远来看,或许会有一个简化的建模库,可以给出深度网络具有的明显特点,然后削减需求测验的参数空间。所以要不断更新你的arXiv阅览内容,这篇博文的内容或许一两个月内也会过期。

Edward经过将概率规划与tensorflow结合,将深度学习和贝叶斯的模型考虑在内。摘自Tran et al. %&&&&&%LR 2017