根据空间光调制器的核算全息三维显现技能, 现在常选用透射式LCD 和反射式LCo S 作为空间光调制器, 以改动光经过空间光调制器( SLM) 后的空间相位和振幅散布, 到达对光信息的调制。传统的根据透射式LCD 空间光调制器的核算全息三维显现体系, 其成像光路杂乱, 并且有必要依靠核算机进行数据发生、收集以及处理, 这就束缚了体系使用的灵敏性, 不便于推行。
相较于透射式LCD, LCo S 具有光使用率高、体积小、开口率高、器材尺度小等特色, 可以很简单地完结高分辨率和微显现投影。选用五颜六色LCoS 屏显现根据RGB 的五颜六色图画, 经过光学成像体系投影到接纳屏上,完结核算全息图画的三维显现。
根据FPGA 的显现体系有以下优势: 榜首, LCoS尺度小, 便于完结微投影, 使用可灵敏编程的FPGA 器材作为驱动操控器, 这样就可以将其做成像一般投影仪相同的微型投影设备, 使核算全息三维显现摆脱了核算机和杂乱光路的捆绑, 具有了更高的灵敏性, 为其走出试验室供给了条件。第二, 因为在传统空间光调制器上得到的图画里含有物波和参阅光的复共轭像, 形成了噪声, 在FPGA 上可以完结图画滤波去噪, 使得到的图画更明晰。第三, FPGA 是根据可编程逻辑单元的器材,当经过归纳、布局布线、时钟束缚的代码烧录到FPGA器材后, FPGA 就将算法代码硬件化了, 可以作为专用芯片作业, 其内部信号延时完全是硬件级传输延时。在处理数据搬移和杂乱的数学运算以及一些循环操作时,例如图画的FFT 改换, FPGA 硬件运算要比软件运算快得多, 即使用FPGA 器材完结对软件算法的硬件加速。
根据以上原因, 本文规划了根据FPGA 的LCoS 驱动代码及图画的FFT 改换体系, 为核算全息三维显现图画处理和显现供给了硬件渠道。
1 体系规划
1. 1 体系模块框图
该体系选用cy clone EP3C5E144C8, 该芯片有5 136 个LE, 95 个用户I/ O, 2 个PLL, 以及46 个嵌入式乘法器和423 936 b 的内部逻辑寄存器。以它丰厚的资源, 完全可以作为LCoS 的驱动操控器材。显现屏选用Himax 的反射式LCoS 屏HX7308, 其分辨率为1 024 768, 可以支撑256 级灰度显现, 具有内置的行场驱动电路, 在外部输入时钟的上升沿和下降沿别离接纳8 b 4 dot s图画数据, 这确保了场频可高达360 Hz。
体系的全体框图如图1 所示。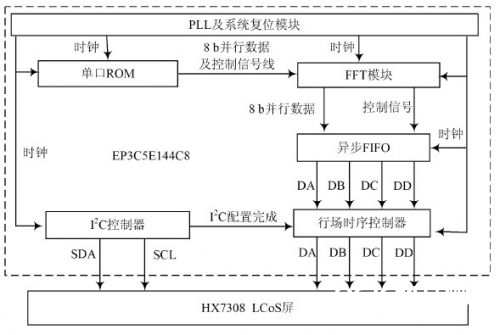
图1 体系框图
1. 2 PLL 及体系复位模块
选用Alter a 的锁相环IP 核, 外部输入时钟为20 MHz, 经倍频后得到其他各模块的驱动时钟, 以及LCo S 的驱动时钟信号。为防止体系异步复位时寄存器呈现亚稳态, 规划了PLL 的前级和后级D 触发器。
因为锁相环的lo cked 引脚在锁相环安稳输出后才会跳变为高电平, 所认为确保其他模块得到安稳的时钟信号, 将locked 引脚和外部输入复位信号rst_n 相与后作为整个体系的复位信号。
1. 3 单口ROM 模块
使用FPGA 内部的M9K 存储器资源完结的单口ROM 作为源图画的数据存储器。将分辨率为176144( QCIF) 的256 阶灰度位图图画初始化到单口ROM里, 所需数据深度为25 344 B。当异步FIFO 没写满时, 单口ROM 将按图画存储地址顺次输出图画数据给FFT 核做快速傅里叶改换。经过处理的图画数据暂存到FIFO 里, 等候行场时序操控器模块取用。
1. 4 异步FIFO 模块
按其数据地址最高2 位分为4 个区间, 读/ 写指针别离对某一区间操作, 当读/ 写指针持平时经过译码器发生FIFO 已读空或许已写满标志信号。为防止地址信号变化时呈现冒险竞赛现象, 写地址和读地址指针都选用格雷码编码。在读空比较子模块和写满比较子模块里加入了FIFO “将空”和“ 将满”查验机制, 有用地确保了FIFO 正确无误的作业。在写时钟w rclk 的上升沿, 异步FIFO 每个地址对应的存储单元里被写入8bit s 数据, 在读时钟rdclk 的上升沿, FIFO 四块接连地址上的32bit s 数据输出, 即读FIFO 的速率相当于写FIFO 速率的4 倍速。
1. 5 I2 C 状况机模块
没有满意I2C 装备条件时, 状况机处于闲暇状况,当满意I2C 装备条件时, 状况机在状况标志位的操控下顺次输出装备地址和装备数据。当数据装备完毕时, 状况机发生中止信号, 并拉高输出引脚iic_co nf ig, 通知行场时序操控器模块开端作业, 这样确保了LCo S 屏能在正确装备下作业。状况机作业原理如图2 所示。
图2 I2 C 状况机原理图
1. 6 行场时序操控器模块
内设水平计数器hcnt 和笔直计数器vcnt。因为显现屏每个时钟周期锁存8 个像素值, 所以显现1 024 个像素值所需行周期为128 个Tclk( 行时钟周期) 。当hcnt 计数器值为HBP 时表明行有用显现区域开端,hcnt 计数器值为HBP+ 128 时表明行有用显现区域完毕, hcnt 计数器值为HSYNC cy cle 时, 完结一行显现,vcnt 计数器加1。当v cnt 计数器值为VBP 时, 笔直有用显现区域开端, 当vcnt 计数器值为VBP+ 768 时, 笔直有用显现区域完毕, 当vcnt 计数器值为VSYN C cycle 时, 完结一帧图画显现。行场时序联系如图3 所示。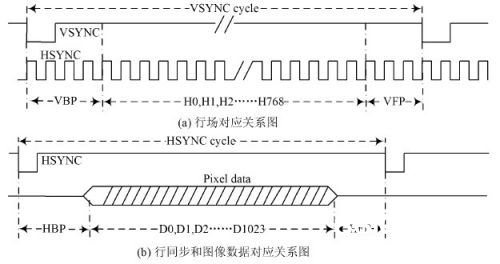
图3 行场时序联系图
1. 7 FFT 模块
FFTV 9. 1 IP 核选用Coo leyT ukey 基??2 DIF 算法, 其FFT 改换原始公式为: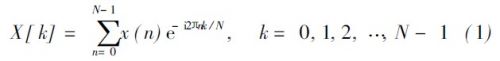
因为选用了数据流形式, 经过改换的数据可以接连输出, 即输出数据不会因为图画数据的输入而中止数据输出, 一起输入数据也不会因为处理后的数据正在输出而中止持续输入, 确保了数据转化和传输的接连性, 提高了数据处理的速度和功率。因为FFT 经过异步FIFO 向屏幕输出数据, 而FIFO 的读数据是写数据的4 倍速, 假设读时钟和写时钟都为100 MHz, 那么有或许会在某一行里呈现FIFO 被取空, 而无法向屏幕输出有用数据的状况。为确保FIFO 向屏幕输出图画数据的接连性, 就要充分使用VBP, VFP, HBP 和HFP 的时刻, 在每一行的开端, 假如FIFO 没满, 那么发动FFT进行数据转化。若图画的分辨率为M N 并且在VBP期间FIFO 已被写满, 则FIFO, FFT 核、行场周期以及图画分辨率间联系的核算公式如下: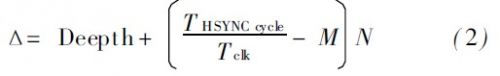
式中: Deepth 是异步FIFO 的数据深度, 单位为B;THSYN C cycle是行周期; Tclk 是异步FIFO, FFT 核、行场时序操控器模块的驱动时钟周期。当△> 0 时, 体系会接连实时地处理图画; 当△ 0 时, 会导致在屏幕某些行的有用显现区域没有有用图画数据可供显现, 这样就破坏了图画显现的接连性。可根据以上公式合理规划FIFO 深度以及选取适宜分辨率的图画。该规划中, 异步FIFO, FFT 核、行场时序操控器模块的驱动时钟为100 MHz, FIFO 深度为256 B, 行周期为336 个Tclk ,M 为174, N 为144, 经核算△> 0。
2 试验仿真成果和丈量成果剖析
图4 是选用Modelsim 6. 5b 进行功用仿真的成果。
使用QuartusV9. 1 自带的TimeQuest Timing Analyzer进行时序束缚后, 在试验板上的场信号丈量成果如图5所示, 场扫描频率已到达368 Hz, 经丈量其他引脚输出信号也均满意时序要求。因为FPGA 器材资源束缚, 对图画做了256 点FFT 改换, 经试验验证, 该规划可以完结图画的实时处理, 代码到达了预期规划作用。
图4 体系功用仿真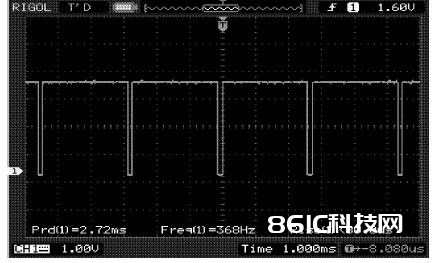
图5 场信号实测图
3 结语
选用Himax 的LCoS 屏HX7308BTJFA 作为显现器材, 其尺度为14. 43 mm 10. 69 mm, 大小可跟1 枚1 元硬币相比较, 很简单完结三维投影微显现。因Verilog HDL 有很强的可移植性, 便于今后对代码的晋级和保护。FPGA 内部资源究竟有限, 文中叙说可知, 若显现分辨率较大的图画, 光靠内部资源完结异步FIFO是不或许的, 所以在此提出两种计划: 榜首, 换一片功用较高的芯片, 满意写FIFO 速率等于读FIFO 速率的要求, 这样就能到达读/ 写数据的动态平衡, 确保了图画的接连显现; 第二, 选用外部存储器SDRAM 存储源图画和FFT 处理后的数据, 选用DDRII 技能读取数据, 使读/ 写FIFO 的速率匹配。受FPGA 芯片资源束缚, 该规划选用分辨率为176 144 的图画进行了体系功用验证, 没有完结图画滤波以及FFT 逆改换, 未来可将代码移植在高端的FPGA 芯片上持续开发数据处理功用。