无论是体系结构仍是指令集,咱们或多或少都应该对X86汇编有些了解,而关于嵌入式范畴已被广泛选用的ARM 处理器,了解的或许并不多。假如你有爱好从事嵌入式方面的开发,那么了解一些RISC 体系结构和ARM汇编的常识仍是有必要的。这儿,咱们找出了这两种体系结构最显着的不同之处,并对此进行介绍,让咱们关于RISC体系结构的汇编有一个根本的了解。首要,咱们就来看一看根据RISC的ARM的体系结构。
根据RISC 的ARM CPU
ARM是一种RISC体系结构的处理器芯片。和传统的CISC体系结构不同,RISC 有以下的几个特征:
◆ 简练的指令集——为了确保CPU可以在高时钟频率下单周期履行指令,RISC指令集只供给很有限的操作(例如add,sub,mul等),而杂乱的操作都需要由这些简略的指令来组合进行模仿。而且,每一条指令不只履行时间固定,其指令长度也是固定的,这样,在译码阶段就可以对下一条指令进行预取。
◆ Load-Store 结构——这个应该是RISC 规划中比较有特征的一部分。在RISC 中,CPU并不会对内存中的数据进行操作,一切的核算都要求在寄存器中完结。而寄存器和内存的通讯则由独自的指令来完结。而在CSIC中,CPU是可以直接对内存进行操作的,这也是一个比较特别的当地。
◆ 更多的寄存器——和CISC 比较,根据RISC的处理器有更多的通用寄存器可以运用,且每个寄存器都可以进行数据存储或许寻址。
当然,作为RISC 范畴最成功的处理器,ARM也遵照上面的特征。这儿,咱们无妨来看一看在user 方法下,ARM处理器的体系结构,这关于咱们了解其汇编语言是有优点的。而其它方法下仅仅有一些寄存器分组略有不同,咱们可以在ARM的手册上查到。这儿要阐明的是,虽然ARM处理器也支撑16位指令,不过鄙人文中,咱们都假定ARM处理器在32 位方法下作业。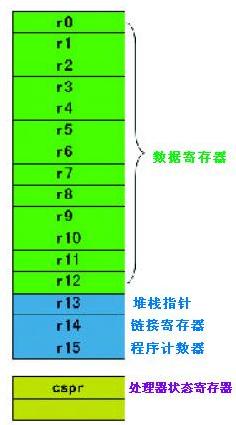
图1:user方法下ARM处理器体系结构
从图1中咱们看到,在user 方法下,ARM CPU 有16个数据寄存器,被命名为r0~r15(这个要比x86的多一些)。r13~r15有特别用处,其间:
◆ r13 – 指向当时栈顶,相当于x86的esp,这个东西在汇编指令中要用sp 表明
◆ r14 – 称作链接寄存器,指向函数的回来地址。用lr表明,这和x86将回来地址保存在栈中是不同的
◆ r15 – 相似于x86的eip,其值等于当时正在履行的指令的地址+8(因为在取址和履行之间多了一个译码的阶段),这个用pc表明
别的,ARM处理器还有一个名为cspr的寄存器,用来监督和操控内部操作,这点和x86 的状况寄存器是相似的。详细的内容就用到再说了。
ARM 指令集
ARM处理器可以支撑3种指令集——ARM,Thumb和Jazelle。
选用那种指令集,由cspr中的标志位来决议。大体说来:
◆ ARM——这是ARM本身的32 位指令集
◆ Thumb ——这是一个全16 位的指令集,在16 位外部数据总线宽度下,这个指令集的功率要比32 位的ARM指令高一些。
◆ Jazelle ——这是一个8位指令集,用来加快Java字节码的履行
整个ARM指令集由数据处理指令、分支指令、Load-Store指令、程序中止指令和一些体系操控指令构成,除了Load-Store指令外,其他部分和x86指令集是比较相似的。但和x86比较,ARM指令最明显的特征它们都是32-bit 定长的。别的,因为arm是根据RISC指令集的,所以CPU只处理在寄存器中的数据并经过独立的load-store指令在内存和寄存器之间进行数据的传递。
在运用方面,ARM指令的格局也要比Intel的杂乱些。一般说来,一条ARM指令有如下的方法:
{S} [Rd], [Rn], [Rm]
其间:
* {S} —— 加上这个后缀的指令会更新cpsr 寄存器
* [Rd] —— 意图寄存器
* [Rn]/[Rm] —— 源寄存器
一般来说,arm 指令有3个操作数,其间Rm寄存器在履行指令前可以进入桶形移位器进行移位操作,而Rn则会直接进入ALU 单元。假如一条arm 指令只要2 个操作数,那么源寄存器依照Rm 来处理。例如,一条加法指令:
add r0, r1, #1
就会把r1+1的成果存放到r0中。
在了解了根本的汇编格局后,读者就可以自行去查询根本的ARM汇编指令了,下面,咱们找出ARM中比较有特征部分——Load-Store指令结构,它是CPU 和内存进行通讯的一个重要前言。
Load-Store 指令体系
因为ARM CPU并不直接处理内存中的数据,这个指令体系就担起了在寄存器和内存之间交流数据的重要前言。它要比x86 的内存拜访机制杂乱一些。该指令体系分红3 类:
◆ 单寄存器传输(这是与x86 最为相像的)
◆ 多寄存器传输
◆ 交流指令
单寄存器传输
先看第一个,很简略:把单一的数据传入(LDR) 或传出(STR)寄存器,对内存的拜访可以是DWORD(32-bit), WORD(16-bit)和BYTE(8-bit)。指令的格局如下:
DWORD:
Rd, addressing1
WORD:
H Rd, addressing2 无符号版
SH Rd, addressing2 有符号版
BYTE:
B Rd, addressing1 无符号版
SB Rd, addressing2 有符号版
addressing1 和addressing2 的分类下面再说,现在了解成某种寻址方法就可以了。
在单寄存器传输方面,还有以下三种变址方法,他们是:
◆ preindex
这种变址方法和x86的寻址机制是很相似的,先对寄存器进行运算,然后寻址,但是在寻之后,基址寄存器的内容并不产生改动,例如:
ldr r0, [r1, #4]
的意义便是把r1+4 这个地址处的DOWRD 加载到r0,而寻址后,r1 的内容并不改动。
◆ preindex with writeback
这种变址方法有点相似于++i的意义,寻址前先对基地址寄存器进行运算,然后寻址. 其根本的语法是在寻址符[]后边加上一个”!” 来表明.例如:
ldr r0, [r1, #4]!
就可以分解成:
add r1, r1, #4
ldr r0, [r1, #0]
◆ postindex
天然这种变址方法和i++的方法就很相似了,先运用基址寄存器进行寻址,然后对基址寄存器进行运算,其根本语法是把offset 部分放到[]外面,例如:
ldr r0, [r1], #4
就可以分解成:
ldr r0, [r1, #0]
add r1, r1, #4
假如你还记得x86 的SIB 操作的话,那么你必定想ARM是否也有,答案是有也没有。在ss上面提到的addressing1 和addressing2的差异便是份额寄存器的运用,addressing1可以运用[base, scale, 桶形移位器]来完结SB 的作用,或许经过[base,offset](这儿的offset 可以是当即数或许寄存器)来完结SI 的作用,而addressing2则只能用后者了。所以每一种变址方法最多可以有3 种寻址方法,这样一来,最多可以有9种用来寻址的指令方法。例如:
ldr r0, [r1, r2, LSR #0x04]!
ldr r0, [r1, -#0x04]
ldr r0, [r1], LSR #0x04
每样找了一种,大约便是这个意思。到此,单寄存器传输就完毕了,把握这些满足敷衍差事了。下面来看看多寄存器传输吧。
多寄存器传输
说得很理解,意思便是经过一条指令一起把多个寄存器的内容写到内存或许从内存把数据写到寄存器中,功率高的价值是会添加体系的推迟,所以armcc 供给了一个编译器选项来操控寄存器的个数。指令的格局有些杂乱:
<寻址方法> Rn{!}, {r^}
咱们先来搞理解寻址方法,多寄存器传输方法有4 种:
也便是说以A最初的都是在Rn的原地开端操作,而B最初的都是以Rn的下一个方位开端操作。假如你依然感到困惑,咱们无妨看个比如。
一切的示例指令履行前:
mem32[0x1000C] = 0x04
mem32[0x10008] = 0x03
mem32[0x10004] = 0x02
mem32[0x10000] = 0x01
r0 = 0x00010010
r1 = 0x00000000
r3 = 0x00000000
r4 = 0x00000000
1) ldmia r0!, {r1-r3} 2) ldmib r0!, {r1-r3}
履行后: 履行后:
r0 = 0x0010001C r0 = 0x0010001C
r1 = 0x01 r1 = 0x02
r2 = 0x02 r2 = 0x03
r3 = 0x03 r3 = 0x04
至于DA 和DB 的方法,和IA / IB 是相似的,不多说了。
最终要说的是,运用ldm 和stm指令对进行寄存器组的维护是很常见和有用的功用。配对计划:
stmia / ldmdb
stmib / ldmda
stmda / ldmib
stmdb / ldmia
持续来看两个比如:
履行前:
r0 = 0x00001000
r1 = 0x00000003
r2 = 0x00000002
r3 = 0x00000001
履行的指令:
stmib r0!, {r1-r3}
mov r1, #1 ; These regs have been modified
mov r2, #2
mov r3, #3
当时寄存器状况:
r0 = 0x0000100C
r1 = 0x00000001
r2 = 0x00000002
r3 = 0x00000003
ldmia r0!, {r1-r3}
最终的成果:
r0 = 0x00001000
r1 = 0x00000003
r2 = 0x00000002
r3 = 0x00000001
别的,咱们还可以运用这个指令对完结内存块的高效copy:
loop
ldmia r9!, {r0-r7}
stmia r10!, {r0-r7}
cmp r9, r11
bne loop
提到这儿,读者应该对RISC的Load-Store体系结构有一个大约的了解了,可以正确配对运用指令,是很重要的。