1.导言
信息时代的一日千里,敦促着各式各样的数据信息快马加鞭,人们在要求信息传输得越来越快的一起,还要求信息要来得愈加及时,所以高速实时的数据传输就成为了电子信息范畴里一个永久不会过期的主题。可是,能够清楚地看到,当今动辄成百上千兆的数据流一股脑的涌入,任何一个高速数据传输体系的稳定性和安全性等方方面面的问题都面临着极大的应战,稍有考虑不周之处就会引起各式各样的问题,因而如何能安全高效的对高速数据进行实时接纳、存储、处理和发送正是此次规划计划的意图。
2.规划计划的硬件选定
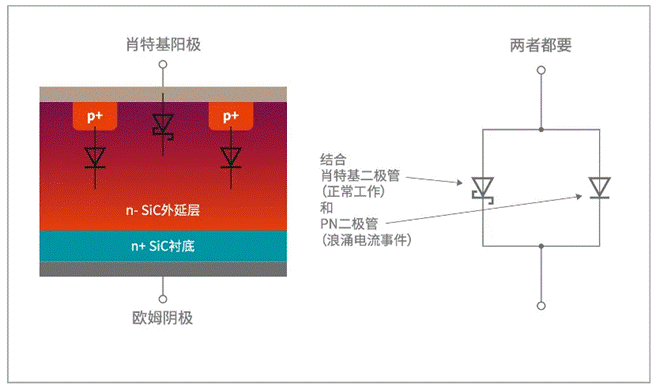
鉴于当时高速数据传输体系的规划计划大多是现场可编程门阵列(FPGA)加片外存储介质( SDRAM、SRAM、DDR等)的组合,所以本次规划计划相同选用这种组合方法,详细为一片 FPGA、三片静态存储器( SRAM)和一片高速数据传输芯片。 FPGA具有管脚多、内部逻辑资源丰富、满意的可用 IP核等长处,用作整个高速数据传输体系的操控模块极为适宜,此次计划中选用 Altera公司的高性价比 Cyclone系列 FPGA;静态存储器具有昀大的长处便是数据读取速度快,且操控信号简略易操作,昀适用于高速数据存储介质,计划选用 ISSI公司的 IS61LV51216类型的静态存储器 ,其处理速度和存储容量满意体系规划的需求;TI公司的 TLK1501是此次规划选用的高速数据传输芯片,其传输才干非常强壮,不仅能满意当时规划的传输速度需求,还留有充沛的带宽余量,为今后的体系改善供给了条件。上述三种芯片是此次高速数据传输体系所要用到的首要组成部件,其详细衔接方法等问题不作评论。
3.详细规划计划
完结整个数据流从接纳、存储、转化直到发送的进程由图一能够看出,在接纳端经由 DVI解码芯片传输的解码数据包含 24bit并行像素数据和三个同步信号——像素时钟 Pclk、数据使能信号 DE以及场同步信号 Vsy,fpga内部的写缓冲区操控器则会依据以上三个数据同步信号生成写缓冲区的写入地址,操控 24bit的像素数据信号存入写缓冲区中,并会在一段时间后向内存操控器发送读恳求( wcache_rreq)以读出写缓冲区内的已写入数据,写缓冲区是由 fpga自带的 M4K块装备生成的双端口 RAM结构,选用乒乓操作,这样整个内存读取和缓冲区写入进程是各自独立进行的,确保所写入数据的完好性,内存操控器在接纳写缓冲区操控器发送的读恳求后,依照相应的写缓冲区地址读取数据,并将其写入片外静态存储器中,以上为像素数据的接纳和存储进程;在发送端,帧同步发生及高速数据传输操控器经过 fpga自带的锁相环发生数据时钟 Dclk、帧同步 Fsy等信号,使读缓冲区操控器发生对读缓冲区的读取地址,读缓冲区操控器在发生读地址的一起,还会在一段时间距离后向内存操控器发送写恳求( rcache_wreq)以向被读过的读缓冲区部分写入新数据,相同读缓冲区也是双端口 RAM结构,选用乒乓操作,确保被发送数据的接连完好,被读出的 24bit数据经过一个 24bit/16bit数据转化器转化为 16bit并行数据之后才干输出给高速数据传输芯片,而内存操控器在接纳读缓冲区操控器的写恳求后在片外静态存储器中读出相应地址的数据写入读缓冲区中,这样整个数据的接纳、存储、转化到发送的进程得以完结。
3.1 写缓冲区操控器的规划
由 DVI解码芯片输入给 fpga的像素时钟信号 Pclk、数据使能信号 DE以及场同步信号 Vsy表明 24bit并行像素数据的同步信息。例如: 1024×512显现分辨率的图画,则在每两个场同步信号 Vsy脉冲之间有 512个“DE=1”的数据有用信号,而在每个“ DE=1”的数据有用信号中有 1024个 Pclk像素时钟信号,如此可将运送的像素数据同步。
写缓冲区操控器直接接纳输入的 DVI数据同步信号,在每个 Vsy脉冲来时将写缓冲区写入地址清零,然后在“DE=1”时写缓冲区操控器内的地址计数器计数有用,在每个 Pclk上升沿进行计数加 1操作,这样在每个 DE有用时会发生一行的像素数据地址,再到下一个DE有用时地址计数器又会从头计数,如此循环,而写缓冲区会依照对应的地址将输入的 24bit并行像素数据同步写入缓冲区内。写缓冲区操控器会在地址计数器计数到半行数据地址的时分,向内存操控器发送写缓冲区读恳求信号( wcache_rreq)和相应缓冲区地址,要求内存操控器对已写入的半行像素数据以 48bit并行数据格式进行读取,因为内存操控器的等效操作时钟远远高于写缓冲区的写入时钟,因而内存操控器会敏捷的将已写入的半行数据读出并中止读数,等候下一个 wcache_rreq的到来,如此便形成了对写缓冲区的乒乓操作,确保了输入像素数据的正确和接连接纳,防止发生像素数据漏接和不同步的现象。读缓冲区操控器的规划思路同上,不再赘述。
3.2 内存操控器的规划
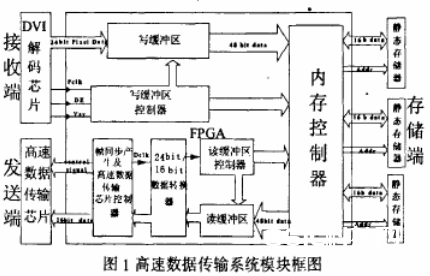
内存操控器里包含主状况机和内存操控模块,如图二所示,主状况机担任对两个缓冲区和片外静态存储器的读写状况操控,共有四个状况——闲暇状况、写缓冲区读取状况、读缓冲区写入状况和读写替换状况,用于操控状况机状况搬运的信号包含:写缓冲区读恳求信号(wcache_rreq)、写缓冲区读取完结信号( r_over)、读缓冲区写恳求信号( rcache_wreq)以及读缓冲区写入完结信号 (w_req)。状况机在没有任何操作恳求下处于闲暇状况,而当其接纳到“wcache_rreq”信号时,状况就会随之变为写缓冲区读取状况并进行相应操作,而当读取操作完结后会有“ r_over”信号传入状况机,状况机又会转入闲暇状况等候下一信号进入,而当状况机处于写缓冲区读取状况时接纳到了“ rcache_wreq”信号,则状况机转入读写替换状况,此刻会对写缓冲区和读缓冲区进行替换操作,一旦有一个缓冲区操作完结时会输入相应的操作完结信号,此刻状况机即转入对另一缓冲区的独自操作直至操作完结再次进入闲暇状况。整个状况搬运进程确保了对读写缓冲区操作恳求的及时呼应,杜绝了因为状况抵触导致的漏操作现象。
体系选用的片外静态存储器的地址总线为 19位,数据总线为 16位,经公式( 1)核算可知选用三片内存的总容量正好能够存储两场 1024×512显现分辨率的图画,这样能够对存储器进行乒乓操作,在存储器内写入一场数据,读取另一场数据,两者替换独立进行。
![]() (1)
(1)
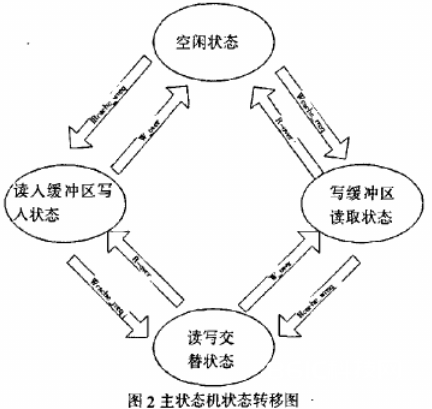
内存操控模块担任对片外存储器进行操控,其操控信号是两个低电平有用信号:nWE和 nCS。nCS为片选信号,当为高电平时存储器处于非作业状况,此刻不能对存储器进行任何操作,低电平时为正常作业状况,能够进行读写操作;nWE为存储器写入信号,当置为低电平时能够对存储器履行写入操作,置为高电平时则能够对存储器履行读取操作。内存操控模块依照主状况机的当时状况来设定两个操控信号的凹凸电平对片外存储器进行操控。图三为在 QuartusII硬件开发平台上经过逻辑分析仪实践采样出来的片外静态存储器作业时序波形图,以中图为例,存储器由写入状况转为读取状况,存储器的地址总线信号和数据总线信号的改变就可看出存储器状况的改变,在写入状况时地址总线按时钟周期发生改变,一起会有 48bit并行数据写入相应内存地址中,而在存储器进入读取状况后,地址总线则变为读取地址,存储器则会在推迟地址总线一个时钟周期后将 48bit数据经由数据总线读出。
3.3 24bit/16bit数据转化器的规划
片外高速数据传输芯片为 16位输入数据总线 ,而由 fpga内部读缓冲区读出的是 24位并行数据,因而需求将 24bit数据转化成 16bit数据再输出。考虑到传送 12个 16bit数据能够等效为 8个 24bit数据,故将数据输出时钟 Dclk用一个 0~11的计数器进行计数,然后取其间的 8个接连时钟读取 24bit数据,这样就处理了 16bit数据和 24bit数据在传输上时钟不匹配的问题。读取的 24bit数据随后被分红两个 12bit数据顺次装入 16个 12bit移位寄存器中,再由 Dclk一位一位打出并拼装成 16bit数据,发送给帧同步发生及高速传输芯片操控器进行码头加载,将自己编写的 16bit数据头校验码以及其他一组信息码刺进数据流中输出给高速数据传输芯片,完结整个数据转化和发送进程。
4.实践测验成果
用 TLK1501[4]高速数据传输芯片集成的数据接纳端口接纳其发送端传输的高速串行数据流,在芯片内部自解码之后再康复成 16bit数据传给 fpga,经过比对发送数据和接纳数据的一致性就能够对逻辑规划、时序等方面进行验证,以确保规划正确。在实践测验时,用一组规划好的 24bitDVI数据替代实践传输的像素信号,而其他同步信号则仍为实践 DVI同步信号,这样做的意图便是能够对发送数据进行操控,便利与接纳数据进行比对,规划的发送数据为一串顺次加“1”的规则 24bit数,因而假如接纳回的数据信号仍为顺次加 “1”的 24bit数,则阐明逻辑规划和时序方面没有问题,规划计划能够用于实践操作中。

图四上为发送数据波形图,图六下为接纳数据波形图。由图中比照能够看出,接纳数据同发送数据均为顺次加“1”的 24bit数据,实践测验成果证明整个高速实时数据传输体系规划满意规划要求,能够用于实践操作中。
5.结语
本体系在实践测验中,发送端数据时钟为 40MHz,因为高速数据传输芯片——TLK1501[4]能够传输 20倍频的串行数据流,因而实践在信道中传输的数据速度能够到达 800MHz,如此高的传输速度能够满意一般情况下的工程要求,并且本体系因为所选片外存储器的容量和操作速度上约束,没能将 TLK1501高速传输的特色充沛发挥出来,信任在体系改善之后,传输速度到达 1G乃至更高的实时数据应该能够完结!
本文作者立异点:提出了一种片外 sram地址空间转化形式,将一维的存储空间笼统为二维存储,能够使视频象素点与存储空间一一对应;提出了一种 24bit/16bit转化模块规划方法。
责任编辑:gt