0 导言
2008年ARIKAN E提出了信道极化的概念并对信道极化现象进行了具体的描绘[1]。极化码的首要进程是在编码体系中经过对信道进行结合与拆分,然后在其间挑选好的部分信道来进行有用数据的传输。极化码被严厉证明有以下两个特性:一是根据信道极化现象存在;二是在码长为无限长时,其信道容量可达香农极限。比较于经典的Turbo码与LDPC码,极化码具有更低的误码率和复杂度以及更高的吞吐率[2-3]。
极化码的译码算法研讨近年来发展迅速,其间成为研讨热门的接连删去(Successive Cancellation,SC)译码算法的根本思想是经过对信息位的比特似然概率值的判别来进行译码。但因为在译码时前一个译码值会对之后的译码值形成影响,因而导致译码功能较差[4]。在此基础上改善的序列接连删去(Successive CancellaTIon List,SCL)算法能在核算复杂度与空间复杂度之间完成更好的平衡[5],比较于在软件上完成该算法,在FPGA进步行SCL译码能够使译码速度进一步加速[6]。现在极化码各方面都现已取得了硕果,可是在FPGA上的译码完成依然存在着译码功率和吞吐率不行高级问题[6]。因而本文针对极化码的SCL译码算法进行了研讨和优化,削减资源耗费一起进步译码功率;针对FPGA上的译码器规划进行了定点量化的改善;终究在Xilinx的VC707开发板进步行了译码器的完成与功能剖析。试验成果表明译码器在码长为512时译码功率为143.988 MHz,吞吐率到达了28.79 Mb/s,具有较强的工程运用价值。
1 极化码的SCL译码算法
SCL译码算法本质是对SC译码算法的推行,SC译码算法的根本思想是经过对每个传输码字的LLR(对数似然比值)进行判别译出码字,LLR的界说如式(1)所示。

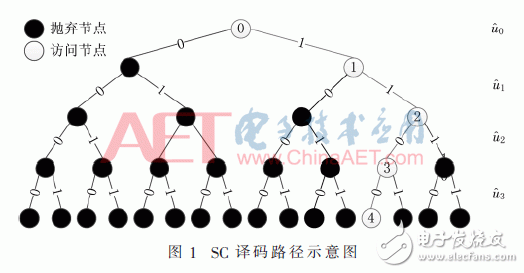
图1所示为SC译码途径示意图,由示意图和LLR核算公式能够看出SC译码在译码进程中前一个译码值与之后的译码值彼此相关,这将对其译码算法的功能形成影响。

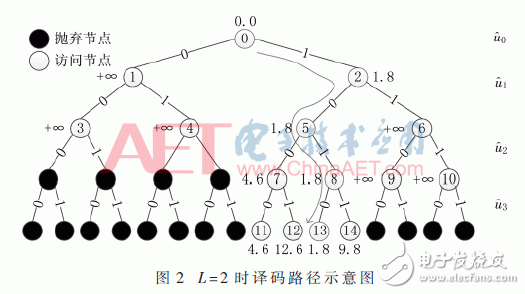
如图2所示的SCL译码进程中,传输的码字为1010,其间前两位为固定比特,后两位为信息比特。传输码字从根节点动身向下扩展,能够得到相应的PM值,一向扩展到4条途径,此刻取出PM值较小的两条途径持续扩展,其他途径删去,因而终究只要4条途径,其间终究算出的PM值最小的相应途径即为译码成果。图2中曲线代表此次PM值最小途径为1010,译码成果正确。
2 SCL译码的优化与规划
SCL译码算法的中心依然是SC译码算法,但其功能优于SC译码算法。在FPGA进步行SCL译码算法的完成会遇到怎么进步译码功率和吞吐率以及怎么合理运用FPGA片上资源等应战。针对SCL译码算法的优化能够在根据其具有的递归结构下对译码核算进程进行简化,针对FPGA上的译码器规划可在运算进程中对浮点数进行量化,更有利于硬件完成。
2.1 SCL译码算法体系规划
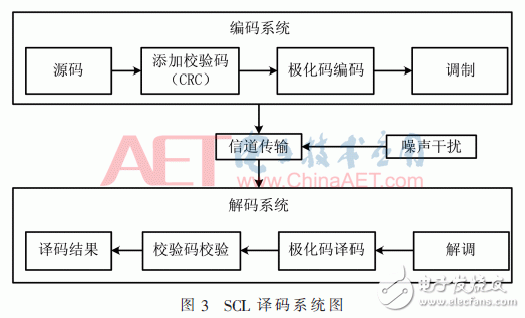
图3所示为本文所规划的SCL译码体系图,针对在SCL译码的进程中有或许呈现最小PM值途径译码不是正确译码的状况,能够经过选用文献[8]中的增加循环冗余校验(Cyclic Redundancy Check,CRC)辅佐的方法来进行处理。在编码体系中先对源码进行校验码的增加,然后进行极化码的编码生成相应的码字进行传输。解码体系在FPGA上运用规划的译码器对传输过来的码字进行极化码译码以及校验码校验,在译码终究阶段的途径挑选时从最小PM值逐条校验,一旦呈现校验经过的途径即为译码成果。
2.2 SCL译码算法优化
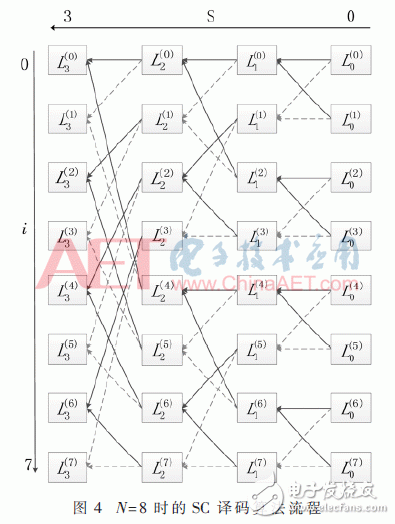
SCL译码进程本质是L个SC译码算法一起进行,图4所示为码长为8时的SC译码算法递归流程图,图中传递的信息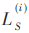 均为LLR,其间S代表核算层数,i代表相应码字标号。
均为LLR,其间S代表核算层数,i代表相应码字标号。
在SC译码算法中,LLR的核算公式如下:

2.3 FPGA中完成算法的改善
在图4所示的SC译码算法流程图中实线部分代表履行的f函数,虚线部分代表履行的g函数。别离界说如下:

在SCL译码进程中的LLR核算值均为浮点数,直接在FPGA中核算会使得译码复杂度较高,因而将浮点数进行定点量化转变成定点数,定点量化的成果经过(O,R,D)来表明,界说如表1所示。

对f函数进行改善之后,译码进程中的核算不再触及乘除法,因而信道输出和LLR的小数位数能够共同。因为选用定点量化用量化值替代了原始值,必定会对译码成果形成必定影响,因而挑选适宜的量化比特数和小数位数尤为重要。经过对信道输出值以及运算进程中的对数似然比值进行具体的剖析以及比照试验,选出了三种如下较好的量化方法。图5所示为量化前后的BER曲线图。

如图5所示的三种量化方法比较,(4,4,0)因为LLR量化的比特数过小,导致作用不是很抱负。(4,5,0)和(5,6,1)的量化挑选根本没有下降SCL的译码功能,而(4,5,0)这种没有小数位的量化挑选更有利于在FPGA进步行核算,因而译码器的规划选用(4,5,0)的量化方法。
3 译码硬件渠道与译码测验成果
3.1 硬件渠道挑选
本文挑选在Xilinx的VC707开发板上对译码器进行完成。该开发板的主芯片为XC7VX485T,包括有485 760个逻辑单元、2 800个DSP Slice、37 080 KB内存以及700个I/O引脚等资源。其最高运转频率能够到达741 MHz,能够用来完成极化码的译码。图6为该评价板实物图。

3.2 译码的仿真与测验
为了对SCL和SC算法进行比照以及挑选一个适宜的途径删减值L,在译码器编写前对各L值下的SCL算法进行了MATLAB仿真,仿真成果如图7所示。
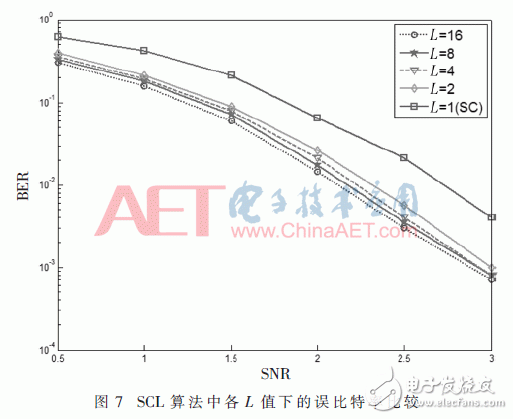
由图7可知当L=1和L=2时误比特率不同较大,再持续加大L值时尽管能够使误比特率进一步下降,可是不同现已没有那么显着,为了在FPGA上能够更简单完成SCL算法,挑选L=2来进行途径删减完成算法。
接着对译码器的正确性进行验证,先经过ModelSim仿真软件对译码器进行硬件仿真。然后运用ISE软件带有的Chipscope在线逻辑剖析仪去抓取在FPGA上的译码成果,经过硬件仿真成果与FPGA上的译码成果比照来验证译码的正确性。
如图8所示上半部分为在ModelSim上码长为64时的仿真成果,data_u_out和data_uhat_out别离为输入源码字和译码仿真成果。下半部分为运用Chipscope抓取的FPGA中运转成果波形图,data_u和data_uhat别离为输入源码字和实践译码成果。输入源码中有一半码字为固定比特,因而有用码字只要32位。由图8能够看出源码字和仿真成果以及FPGA译码成果均为69ab4d68,因而本次译码成果正确。
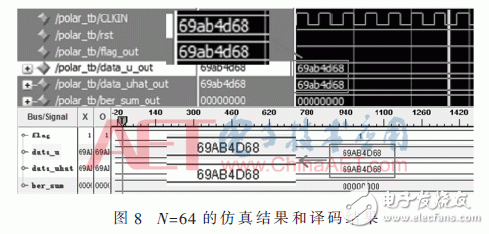
图9和图10所示别离为码长为128和512时的仿真成果和译码成果波形图。在抓取512码长的波形时,因为码长太长,因而在Chipscope平分成了四段进行显现,因为Chipscope与ModelSim显现次序不同,因而用相应数字表明了相应的成果次序,能够看出译码成果均正确。


3.3 译码功能剖析
下面临算法的功能以及工程占用资源等进行归纳剖析,在ISE软件上的归纳陈述中能够检查译码器在FPGA上的资源运用成果,如表2所示。

经过归纳资源成果能够对译码器的吞吐率进行核算,公式如下:

式中N为有用码长,fmax为最大时钟频率,td为译码推迟的时钟周期数。吞吐率核算成果如表3所示。

4 定论
现在极化码正越来越遭到研讨者们的注重,而国内涵极化码译码算法研讨方面有待深化,尤其是在硬件渠道中完成的较少。根据此本文首要针对极化码的SCL译码算法进行了研讨与优化,并在FPGA上规划了译码器,终究在Xilinx的VC707开发板进步行译码器的完成。该译码器的规划下降了译码复杂度以及FPGA上的资源耗费,在码长为512时译码最高频率为143.988 MHz,吞吐率为28.79 Mb/s,有较强的工程实用性。