深度学习模型和数据集的规划增长速度现已让 GPU 算力也开端绰绰有余,假如你的 GPU 连一个样本都容不下,你要怎么练习大批量模型?经过本文介绍的办法,咱们能够在练习批量乃至单个练习样本大于 GPU 内存时,在单个或多个 GPU 服务器上练习模型。
分布式核算
2018 年的大部分时刻我都在企图练习神经网络时战胜 GPU 极限。无论是在含有 1.5 亿个参数的言语模型(如 OpenAI 的大型生成预练习 Transformer 或最近相似的 BERT 模型)仍是馈入 3000 万个元素输入的元学习神经网络(如咱们在一篇 ICLR 论文《Meta-Learning a Dynamical Language Model》中说到的模型),我都只能在 GPU 上处理很少的练习样本。
但在大都情况下,随机梯度下降算法需求很大批量才干得出不错的成果。
假如你的 GPU 只能处理很少的样本,你要怎么练习大批量模型?
有几个东西、技巧能够协助你处理上述问题。在本文中,我将自己用过、学过的东西整理出来供咱们参阅。
在这篇文章中,我将首要评论 PyTorch 结构。有部分东西没有包含在 PyTorch(1.0 版别)中,因而我也写了自定义代码。
咱们将侧重讨论以下问题:
在练习批量乃至单个练习样本大于 GPU 内存,要怎么在单个或多个 GPU 服务器上练习模型;
怎么尽或许高效地运用多 GPU 机器;
在分布式设备上运用多个机器的最简略练习办法。
在一个或多个 GPU 上练习大批量模型
你建的模型不错,在这个简练的使命中或许成为新的 SOTA,但每次测验在一个批量处理更多样本时,你都会得到一个 CUDA RuntimeError:内存不足。
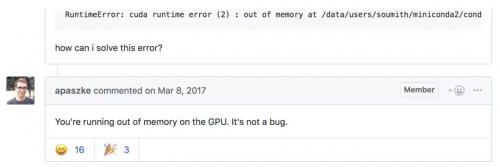
这位网友指出了你的问题!
但你很确定将批量加倍能够优化成果。
你要怎么做呢?
这个问题有一个简略的处理办法:梯度累积。

梯度下降优化算法的五个过程。
与之对等的 PyTorch 代码也能够写成以下五行:
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss.backward() # Backward pass
optimizer.step() # Optimizer step
predictions = model(inputs) # Forward pass with new parameters
在 loss.backward() 运算期间,为每个参数核算梯度,并将其存储在与每个参数相关联的张量——parameter.grad 中。
累积梯度意味着,在调用 optimizer.step() 施行一步梯度下降之前,咱们会对 parameter.grad 张量中的几个反向运算的梯度求和。在 PyTorch 中这一点很简单完成,由于梯度张量在不调用 model.zero_grad() 或 optimizer.zero_grad() 的情况下不会重置。假如丢失在练习样本上要取均匀,咱们还需求除以累积过程的数量。
以下是运用梯度累积练习模型的关键。在这个比如中,咱们能够用一个大于 GPU 最大容量的 accumulation_steps 批量进行练习:
model.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
model.zero_grad() # Reset gradients tensors
if (i+1) % evaluation_steps == 0: # Evaluate the model when we…
evaluate_model() # …have no gradients accumulated