作为一种人机交互的手法,语音的端点检测在解放人类双手方面意义严峻。一同,工作环境存在着各式各样的布景噪声,这些噪声会严峻下降语音的质量然后影响语音运用的作用,比方会下降辨认率。未经紧缩的语音数据,网络交互运用中的网络流量偏大,然后下降语音运用的成功率。因而,音频的端点检测、降噪和音频紧缩始终是终端语音处理重视的要点,现在仍是活泼的研讨主题。
为了能和您一同了解端点检测和降噪的根本原理,带您一同一窥音频紧缩的奥妙,科大讯飞资深研制工程师李洪亮将为咱们详解语音处理检测技能中的热门——端点检测、降噪和紧缩 。
▎端点检测
首要来看端点检测(Voice Activity Detection, VAD)。音频端点检测便是从接连的语音流中检测出有用的语音段。它包括两个方面,检测出有用语音的开端点即前端点,检测出有用语音的完毕点即后端点。
在语音运用中进行语音的端点检测是很必要的,首要很简略的一点,便是在存储或传输语音的场景下,从接连的语音流中别离出有用语音,能够下降存储或传输的数据量。其次是在有些运用场景中,运用端点检测能够简化人机交互,比方在录音的场景中,语音后端点检测能够省掉完毕录音的操作。

为了能更清楚阐明端点检测的原理,先来剖析一段音频。上图是一段只需两个字的简略音频,从图上能够很直观的看出,首尾的静音部分声波的振幅很小,而有用语音部分的振幅比较大,一个信号的振幅从直观上表明了信号能量的巨细:静音部分能量值较小,有用语音部分的能量值较大。语音信号是一个以时刻为自变量的一维接连函数,核算机处理的语音数据是语音信号按时刻排序的采样值序列,这些采样值的巨细相同表明了语音信号在采样点处的能量。

采样值中有正值和负值,核算能量值时不需求考虑正负号,从这个意义上看,运用采样值的肯定值来表明能量值是自然而然的主意,由于肯定值符号在数学处理上不方便,所以采样点的能量值一般运用采样值的平方,一段包括N个采样点的语音的能量值能够界说为其间各采样值的平方和。
这样,一段语音的能量值既与其间的采样值巨细有关,又与其间包括的采样点数量有关。为了调查语音能量值的改动,需求先将语音信号依照固定时长比方20毫秒进行切割,每个切割单元称为帧,每帧中包括数量相同的采样点,然后核算每帧语音的能量值。
假如音频前面部分接连M0帧的能量值低于一个事前指定的能量值阈值E0,接下来的接连M0帧能量值大于E0,则在语音能量值增大的当地便是语音的前端点。相同的,假如接连的若干帧语音能量值较大,随后的帧能量值变小,并且继续必定的时长,能够认为在能量值减小的当地便是语音的后端点。
现在的问题是,能量值阈值E0怎样取?M0又是多少?抱负的静音能量值为0,故上面算法中的E0抱负状态下取0。不幸的是,收集音频的场景中往往有必定强度的布景音,这种单纯的布景音当然算静音,但其能量值显着不为0,因而,实践收集到的音频其布景音一般有必定的根底能量值。
咱们总是假定收集到的音频在开端处有一小段静音,长度一般为几百毫秒,这一小段静音是咱们估量阈值E0的根底。对,总是假定音频开端处的一小段语音是静音,这一点假定十分重要!!!!在随后的降噪介绍中也要用到这一假定。在估量E0时,选取必定数量的帧比方前100帧语音数据(这些是“静音”),核算其均匀能量值,然后加上一个经验值或乘以一个大于1的系数,由此得到E0。这个E0便是咱们判别一帧语音是否是静音的基准,大于这个值便是有用语音,小于这个值便是静音。
至于M0,比较简略了解,其巨细决议了端点检测的灵敏度,M0越小,端点检测的灵敏度越高,反之越低。语音运用的场景不同,端点检测的灵敏度也应该被设置为不同的值。例如,在声控遥控器的运用中,由于语音指令一般都是简略的控制指令,中心呈现逗号或句号等较长中止的或许性很小,所以进步端点检测的灵敏度是合理的,M0设置为较小值,对应的音频时长一般为200-400毫秒左右。在大段的语音听写运用中,由于中心会呈现逗号或句号等较长时刻的中止,宜将端点检测的灵敏度下降,此刻M0值设置为较大值,对应的音频时长一般为1500-3000毫秒。所以M0的值,也便是端点检测的灵敏度,在实践中应该做成可调整的,它的取值要依据语音运用的场景来挑选。
以上仅仅语音端点检测的很简略的一般原理,实践运用中的算法远比上面讲的要杂乱。作为一个运用较广的语音处理技能,音频端点检测依然是一个较为活泼的研讨方向。科大讯飞现已运用循环神经网络(Recurrent Neural Networks, RNN)技能来进行语音的端点检测,实践的作用能够重视讯飞的产品。
▎降噪
降噪又称噪声按捺(Noise Reduction),前文说到,实践收集到的音频一般会有必定强度的布景音,这些布景音一般是布景噪音,当布景噪音强度较大时,会对语音运用的作用发生显着的影响,比方语音辨认率下降,端点检测灵敏度下降等,因而,在语音的前端处理中,进行噪声按捺是很有必要的。
噪声有许多种,既有频谱安稳的白噪声,又有不安稳的脉冲噪声和崎岖噪声,在语音运用中,安稳的布景噪音最为常见,技能也最老练,作用也最好。本课程只评论安稳的白噪声,即总是假定布景噪声的频谱是安稳或许是准安稳的。
前面讲的语音端点检测是在时域上进行的,降噪的进程则是在频域上进行的,为此,咱们先来简略介绍或许说温习一下用于时域-频域彼此转化的重要东西——傅里叶改换。
为了更简略了解,先看高等数学中学过的傅里叶级数,高等数学理论指出,一个满意Dirichlet条件的周期为2T的函数f(t),能够打开成傅里叶级数:
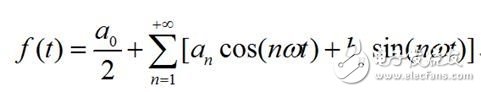
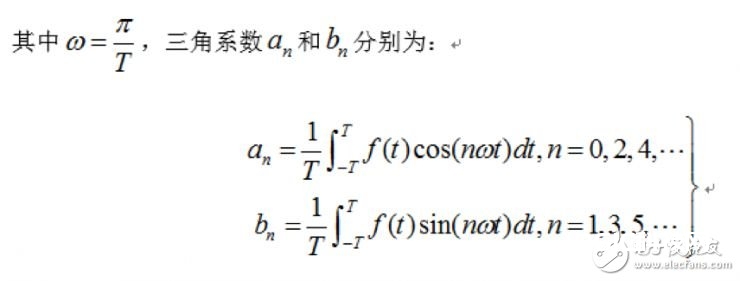
关于一般的接连时域信号f(t),设其界说域为[0,T],对其进行奇延拓后,其傅里叶级数如下式:
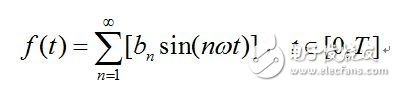
bn的核算同上,由上式可知,任何一个接连的时域信号f(t),都能够由一组三角函数线性叠加而成。或许说, f(t)都能够由一个三角函数线性组合组成的序列来无限的迫临。信号的傅里叶级数展现的是构成信号的频率以及各个频率处的振幅,因而,式子的右端又能够看做是信号f(t)的频谱,说的更直白一点,信号的频谱便是指这个信号有哪些频率成分,各个频率的振幅怎么。上式从左到右的进程是一个求已知信号的频谱的进程,从右到左的进程是一个由信号的频谱重构该信号的进程。
虽然由信号的傅里叶级数很简略了解频谱的概念,但在实践中求取信号的频谱时,运用的是傅里叶级数的一种推行方式——傅里叶改换。
傅里叶改换是一个大的宗族,在不同的运用范畴,有不同的方式,在这里咱们只给出两种方式——接连方式的傅里叶改换和离散傅里叶改换:
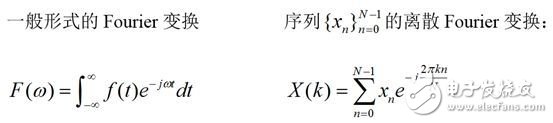
其间的j是虚数单位,也便是j*j=-1,其对应的傅里叶逆改换分别为:
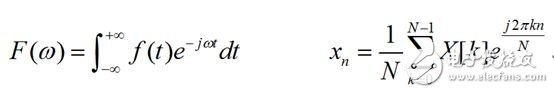
在实践运用中,将数字采样信号进行傅里叶改换后,能够得到信号的频谱。频域上的处理完结后,能够运用傅里叶逆改换将信号由频域转化届时域中。对,傅里叶改换是一个能够完结由时域向频域转化的重要东西,一个信号经傅里叶改换后,能够得到信号的频谱。
以上是傅里叶改换的简略介绍,数学功底不太好的朋友看不大懂也不要紧,只需了解,一个时域信号进行傅里叶改换后,能够得到这个信号的频谱,即完结如下转化:
左边的是时域信号,右面的是对应的频谱,时域信号一般重视的是什么时刻取什么值,频域信号关怀的是频率散布和振幅。
有了以上的理论作为根底,了解降噪的原理就简略多了,噪音按捺的要害是提取出噪声的频谱,然后将含噪语音依据噪声的频谱做一个反向的补偿运算,然后得到降噪后的语音。这句话很重要,后边的内容都是环绕这句话打开的。
噪声按捺的一般流程如下图所示:
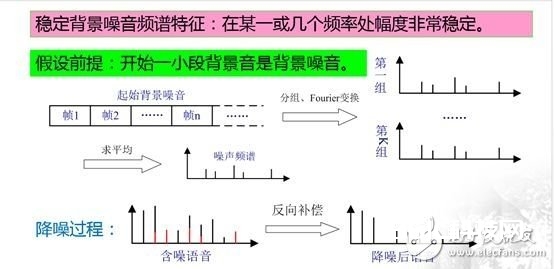
同端点检测相似,假定音频开端处的一小段语音是布景音,这一假定十分重要,由于这一小段布景音也是布景噪声,是提取噪声频谱的根底。
降噪进程:首要将这一小段布景音进行分帧,并依照帧的先后顺序进行分组,每组的帧数能够为10或其他值,组的数量一般不少于5,随后对每组布景噪声数据帧运用傅里叶改换得到其频谱,再将各频谱求均匀后得到布景噪声的频谱。
得到噪声的频谱后,降噪的进程就十分简略了,上图下面左边的图中赤色部分即为噪声的频谱,黑色的线为有用语音信号的频谱,两者一同构成含噪语音的频谱,用含噪语音的频谱减去噪音频谱后得到降噪后语音的频谱,再运用傅里叶逆改换转回届时域中,然后得到降噪后的语音数据。
下图展现了降噪的作用

左右两幅图是降噪前后时域中的比照,左边的是含噪语音信号,从图中能够看到噪声仍是很显着的。右侧的是降噪后的语音信号,能够看出,布景噪声被大大的按捺了。
下面两幅图是频域中的比照
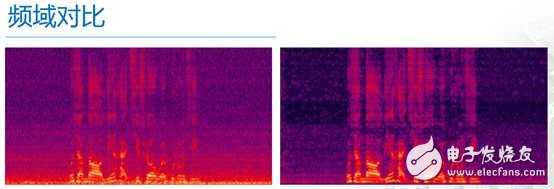
其间横轴表明时刻轴,纵轴表明频率,左边的是含噪语音,其间的亮赤色部分是有用语音,而那些像沙子相同的紫色的部分则是噪声。从图中能够看出,噪声不仅是“无时不在”,并且仍是“无处不在”,也便是在各种频率处都有散布,右侧的是降噪后的语音,能够很显着的看出,降噪前那些像沙子相同的紫色的部分淡了许多,便是噪声被有用的按捺了。
在实践运用中,降噪运用的噪声频谱一般不是原封不动的,而是跟着降噪进程的进行被继续批改的,即降噪的进程是自适应的。这样做的原因一方面是语音数据前部的静音长度有时不行长,布景噪声数据缺乏导致得到的噪声频谱往往不行精确,另一方面,布景噪声往往不是肯定安稳的,而是突变的乃至会突变到另一种安稳的布景噪声。
这些原因都要求在降噪的进程中对运用的噪声频谱做及时批改,以得到较好的降噪作用。批改噪声频谱的办法是运用后继音频中的静音,重复噪声频谱提取算法,得到新的噪声频谱,并将之用于批改降噪所用的噪声频谱,所以降噪的进程中依然要运用端点检测中用到的怎么判别静音。噪声频谱批改的办法或许是新旧频谱进行加权均匀,或许运用新的噪声频谱彻底替换运用中的噪声频谱。
以上介绍的是降噪的十分简略的原理。实践运用中的降噪算法远比上面介绍的要杂乱,实践中的噪声源多种多样,其发生的机理和特性也较为杂乱,所以噪声按捺在如今依然是一个较为活泼的研讨范畴,各种新技能也层出不穷,比方在实践运用中现已运用了多麦克风阵列来进行噪声按捺。
▎音频紧缩
音频紧缩的必要性众所周知,不再赘述。一切的音频紧缩系统都要求有两种对应的算法,一种是运转于源端上的编码算法(encoding),另一种是运转于接纳端或用户终端的解码算法(decoding)。
编码算法和解码算法体现出必定的不对称性。这种不对称性一是体现在编码算法和解码算法的功率能够不同。音频或视频数据在存储时,一般只被编码一次,但将被解码不计其数次,所以编码算法较杂乱、功率下降、费用贵重是能够被承受的,但解码算法必定要快速、简略并且廉价。编码算法和解码算法的不对称性还体现在编码和解码的进程一般是不行逆的,也便是说,解码后得到的数据和编码之前的原始数据能够是不同的,只需它们听起来或看起来是相同的即可,这种编解码算法一般称为有损的,与此对应的是,假如解码后得到和原始数据共同的数据,这种编码和解码称为无损的。
音视频编解码算法大多是有损的,由于忍耐一些少数信息的丢掉,往往能够换来紧缩率的大幅提高,音频信号的紧缩编码采用了数据编码中的一些技能,如熵编码、波形编码、参数编码、混合编码、感知编码等。
本次课要点介绍感知编码,相关于其他的编码算法,感知编码依据人耳听觉的一些特性(心理声学),去除音频信号中的冗余,然后到达音频紧缩的意图。相关于其他的音频编码算法(无损的),在人耳没有感觉到显着失真的条件下,能够到达10倍以上的较大紧缩率。
首要来介绍感知编码的心理声学根底。音频紧缩的中心是去除冗余。所谓冗余便是语音信号中包括的不能为人耳所感知的信息,它对人类确认音色、腔调等信息没有任何协助,比方,人耳能听到的声响频率规模为20-20KHz,无法感知频率低于20Hz的次声波和频率高于20KHz的超声波。再比方,人耳也无法听到一段“不行响”的声响。感知编码便是利用了人类听觉系统的这类特性,到达去除音频冗余信息的意图。
感知编码中的心理声学主要有:频率屏蔽、时域屏蔽、可听度阈值等。

频率屏蔽 频率屏蔽在生活中处处可见,比方你在家中坐在沙发上安静的看电视,忽然,正在装饰的邻居家一阵很尖锐的电钻钻墙的声响传来,这时你所能听到的只需手提电钻宣布的很强的噪声,虽然此刻电视所宣布的声响依然在影响着你的耳膜,但你却不闻不问,也便是说,一段强度很高的声响能够彻底屏蔽一段强度较低的声响,这种现象称为频率屏蔽。

时域屏蔽 接受前一个比方,不仅在电钻宣布声响的时刻内人耳听不到电视机的声响,便是在电钻的声响刚停下来的一小段时刻内,人耳也听不到电视机的声响,这种现象称为时域屏蔽。发生时域屏蔽的原因是人类的听觉系统是一个增益可调的系统,听强度较大的声响时,增益较低,听强度较小的声响时,增益较高。有时人类乃至凭借外部手法来改动听觉系统的增益,比方,捂耳朵以避免强度很大的声响损害耳膜,而屏住呼吸、侧耳、以手放耳廓后更是听较弱声响时的常见行为。在上例中,强度很大的声响刚消失时,听觉系统需求一小段时刻来调高增益,正是在这一小段时刻内发生了时域屏蔽。
下面来说可听度阈值,它关于音频紧缩灰常重要。
设想在一个安静的房间中,一台由核算机控制的扬声器能够宣布某一频率的声响,刚开端时扬声器功率较小,处于必定间隔上的听觉正常的人听不到扬声器宣布的声响。然后开端逐步增大扬声器的功率,当功率增大到刚好能够被听见的时分,记录下此刻扬声器的功率(声强级,单位分贝),这个功率便是这个频率下的可听度阈值。
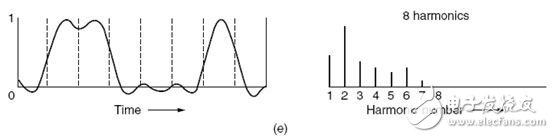
然后改动扬声器所发音频的频率,重复以上试验,终究取得的可听度阈值随频率改动的曲线如下图所示:
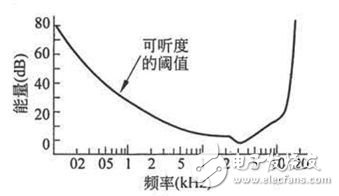
由图中能够很显着的看出,人类的听觉系统对频率在1000-5000Hz规模的声响最灵敏,频率越挨近两边,人类听觉反响越愚钝。
回过头来再看频率屏蔽的景象,这次试验在房间中添加一个频率为150Hz,强度为60dB的信号,然后重复试验,试验得出的可听度阈值曲线如下图所示:

从图中很显着的看出,可听度阈值曲线在150Hz邻近被激烈的歪曲了,被向上进步了许多。这意味着,原本坐落可听度阈值之上的150Hz邻近的某个频率的声响,有或许由于150Hz的更强的信号的存在而变得不行闻了,也便是被屏蔽了。
音频紧缩1#e#
感知编码的根本规矩便是,永久不需求对人耳听不到的信号进行编码,简略来说便是,听不到的信号不需求编码,这句废话恰恰是语音紧缩研讨的要点之一。废话的别的一种意义便是十分简略了解的正确的话。言归正传,哪些东西听不见呢?功率低于可听度阈值的信号或许说重量,被屏蔽的信号或许说重量,这些人耳都听不见,都是上文说到的“冗余”。
以上是心里声学的一些东西。要想很好的了解音频紧缩,还需求了解一个更重要的概念:子带。子带(subband)是指这样的一种频率规模,当两个腔调的频率坐落一个子带内时,人就会把两个腔调听成一个。更一般的情况是,假如一个杂乱信号的频率散布坐落一个子带内时,人耳的感觉是该信号等价于一个频率坐落该子带中心频率处的简略信号,这是子带的中心内在。简略说,子带是指一个频率规模,频谱坐落这个规模内的信号能够用一个单一频率的重量来替代。
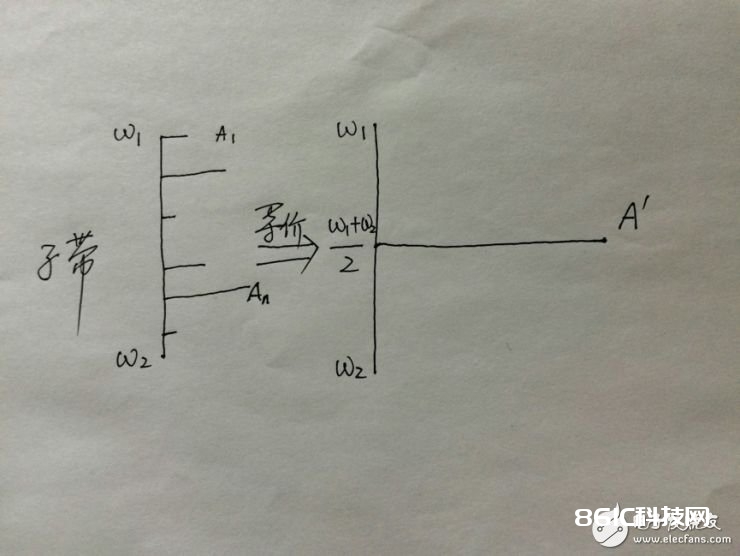
一般等价的频率取子带的中心频率,振幅取子带内个频率重量振幅的加权和,更简略的办法则是将各频率重量的振幅直接相加,作为等价信号的振幅,这样一个规模内的频率重量用一个重量就能够替代了。
设一个信号的频谱频率最低值为w0,最大值为w1。子带编码便是将w0-w1之间的频率规模区分红若干子带,然后每个子带规模内的重量用一个等价的频率重量来替换。这样,一个具有杂乱频谱的信号能够等价为一个频谱构成灰常简略的信号——频谱被大大简化了,需求存储的东西就十分少了。
从以上进程不难知道,子带怎么区分对紧缩后音频的质量影响很大(毕竟是近似等价)。子带的区分办法是子带编码的一个很重要的研讨主题,大致能够分为等宽子带编码和变宽子带编码,见名知意,不解说。
子带区分后子带数量的不同导致了紧缩算法的不同等级。简略知道,码率越低紧缩率越高时,子带数量少,一同音质较差。相反的情况也简略了解。
了解了子带编码,音频紧缩就很简略了解了,一个信号通过一组三角滤波器(等同于一组子带)后,被精简为数量很少的频率重量。然后调查这些频率重量,能量或许说振幅坐落可听度阈值曲线之下的直接无视(删去该重量,由于听不到)。再调查余下的两两相邻的频率重量,假如其间一个被周围的频率屏蔽,也删去掉。通过以上的处理,一个杂乱信号的频谱所含有的频率重量就很简略了,运用很少的数据就能够存储或许传输这些信息。
解码的时分运用傅里叶逆改换将上面得到的简略频谱重构届时域上,得到解码后的语音。
以上便是音频紧缩的简略原理,下面谈谈音频编解码库。
能够揭露获取的音频编解码开源库许多,其特色和才能也有所不同,如下图:
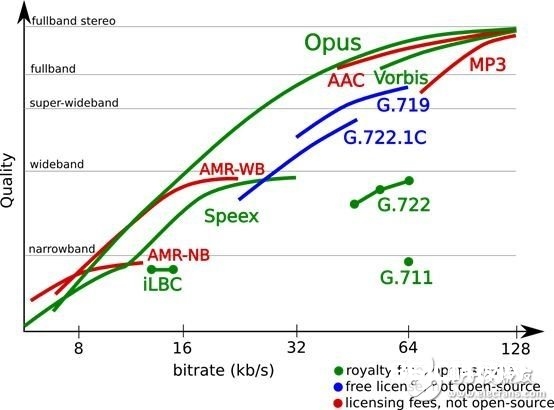
由图中能够看到,AAC和MP3等走的是“高端道路”,用来对高采样率的音乐进行编码,而AMR和SPEEX等走的是中低端道路,能够处理16K采样率以下的语音信号,这关于语音组成、语音辨认、声纹辨认等语音运用足够了。
科大讯飞语音云运用的是SPEEX系列,算法相关信息如下图所示:

Speex编解码库紧缩率改换规模较广,紧缩等级可供挑选的规模较宽,所以运用在网络情况较为杂乱的移动终端运用中甚为适宜。
好了,以上便是本次课共享的全部内容。
小结:
音频端点检测、降噪和语音紧缩,许多人觉得奥秘、难于了解和难以掌握。但经李老师娓娓道来,平常感觉巨大上的语音处理技能也被讲的浅显易懂。本来,不需求很深邃的理论功底也能够了解这些技能的要害:音频端点检测的要害是依据前面的静音确认用来分辩静音和有用语音的标尺,降噪的要害是运用前面的一小段布景噪音提取出噪声的频谱,音频紧缩办法之一是充分利用人类的心里声学,区分子带,去除冗余等。
让咱们一同重视语音处理技能在以上几个方面的最新开展吧。
讲演嘉宾介绍
李洪亮,结业于中国科学技能大学。科大讯飞资深研制工程师,长时间从事语音引擎和语音类云核算相关开发,科大讯飞语音云的缔造者之一,主导研制的用于讯飞语音云平台上的语音编解码库,日运用量超越二十亿。主导语音类国家标准系统的建造,主导、参加多个语音类国家标准的拟定。 他今日的共享将分为两大部分,榜首部分是端点检测和降噪,第二部分是音频紧缩。