摘要
OpenEM 的全称是 Open Event Machine。是 TI 针对嵌入式运用开发的 multicore runtime system library。OpenEM 能够在多核上有用的调度,分发使命。它把使命调度给负载轻的核,从而完成动态的负载平衡。OpenEM 是根据 TI Keystone 系列芯片的 multicore Navigator 构建的,具有开支小,功率高的特色。本文首要对 OpenEM 的原理做了简略的介绍。然后结合一个大矩阵乘的演示用例具体介绍了 OpenEM 的运用。最终经过量化剖析这个演示用例的履行cycle 数,总结了 OpenEM 的功率和限制。期望本文能成为学习 OpenEM 的读者的一个有用的参阅。
1、OpenEM 简介
OpenEM 的全称是 Open Event Machine。它是 TI 开发的可运用于 Keystone 多核 DSP 的multicore runtime system library。OpenEM 的意图是在多核上有用的调度,分发使命,完成动态的负载平衡。根据 OpenEM,用户能够很简单的把本来的单核运用移植到 Keystone 多核芯片。需求留意的是 OpenEM 现在只能把使命调度分发到同一个 DSP 的多个核上,不能跨 DSP 调度分发。 OpenEM不依赖于 BIOS。它能够在芯片上裸跑,代码精简,功率高。并且,OpenEM不同于业界现已有 OpenMP 和 OpenCL 等开放式的 multi-core runtime systems。它是针对嵌入式体系的规划,更能满意嵌入式规划的实时性要求。TI 的 keystone 架构多核芯片中有 Multicore Navigator。它由 Queue Manager(简称为 QMSS)和一系列 Packet DMA engine 构成。OpenEM便是根据这套硬件体系构建的。例如,OpenEM 的 scheduler 是运转在 QMSS 的 PDSP(QMSS内部的 RISC 处理器)上的。OpenEM的 preload 功用是经过 QMSS 的 packet DMA 完成的。了解QMSS 的编程对学习 OpenEM 很有协助。OpenEM 是 MCSDK 的一个组件。它还在不断的开展改善中。本文对 OpenEM 的介绍以及演示用例都是根据 BIOS MCSDK 2.01.02 的 OpenEM 1.0.0.2。
1.1 OpenEM 的软件目标
下面经过列表和图示介绍了 OpenEM的首要软件目标。表 1 是 OpenEM 的首要软件目标的列表。
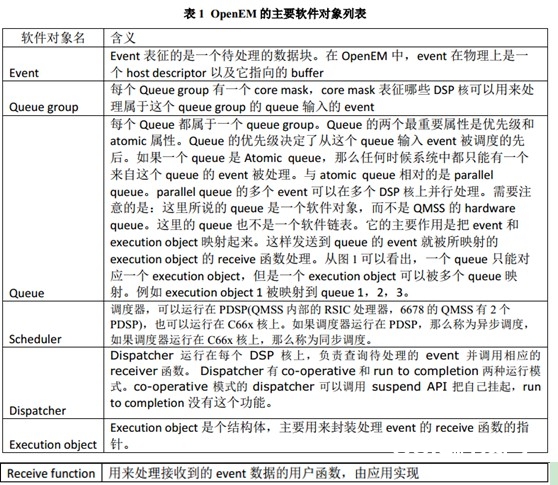
需求留意的是,本文介绍的 OpenEM 的运转形式是:Scheduler 运转在 PDSP,Dispatcher 是“run to completion ”形式。
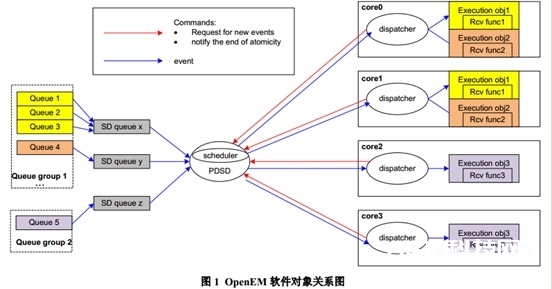
图 1 是一个软件目标联系图,显现出了表 1 中罗列的软件目标。界说了 2 个 queue group,5 个queue 和 3 个 execution object。Queue group1 的 core mask 对应核 0 和 1。所以来自 queue1,2,3,4 的 event 只能在核 0 和核 1 上履行,因为这些 queue 归于 queue group1。Queue group2 的 core mask 对应核 2 和 3。所以来自 queue5 的 event 只能在核 2 和核 3 上履行,因为queue5 归于 queue group2。execution object 1 和 queue 1,2,3 映射相关。execution object 2 和queue 4 映射相关。execution object 3 和 queue 5 映射相关。图中的蓝线表明了 event 的行径,红线表明 command 的行径。图中的 SD queue 是 hardware queue,它不是一个软件目标而是OpenEM内部的组件。
1.2 OpenEM 的两个重要概念
OpenEM中有两个简单混杂的重要概念:prefetch 和 preload。
• Prefetch 是指每个 DSP 核向 scheduler 发指令,告知 scheduler“本核现已闲暇了,能够分配新的作业给本核了”。只要收到一个核的 prefetch 指令,scheduler 才会调度新的 event 给这个核。假如 DSP 核不宣布 prefetch 指令,它就不会被分派使命。这是 OpenEM 的 scheduler的根本调度准则。
• Preload 和 event 的特点有关。一般,event 的数据是坐落 DDR 的。假如 DSP 核直接拜访DDR 功率会比较低。所以,OpenEM 能够把 event 的数据经过 QMSS 的 packet DMA 搬到DSP 核的 local L2。这个搬移的进程便是 preload。每个 event 的数据是否做 preload 是可配的。每个 event 在创立的时分都能够指定一个 preload 特点。Event 的 preload 特点能够是:
– Preload disable, 即不做预搬移
– Preload up to sizeA,即做预搬移,可是最多只搬 sizeA bytes
– Preload up to sizeB,即做预搬移,可是最多只搬 sizeB bytes
– Preload up to sizeC,即做预搬移,可是最多只搬 sizeC bytes
– 其间 SizeA,SizeB 和 SizeC 是常数,在 OpenEM 初始化的时分能够装备。
1. 3 OpenEM 的常用 API cycle 数
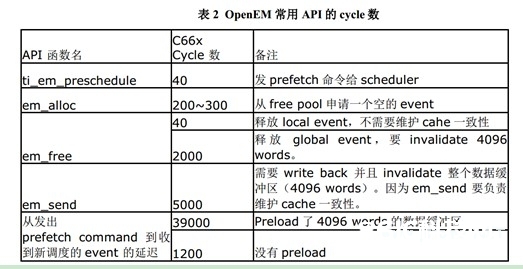
OpenEM的顺便开支是运用最重视特性之一。所以咱们实测了 OpenEM 常用 API 的 cycle 数如表2。需求留意的是:因为 OpenEM会担任 cache 一致性的保护,而有些 API 的处理进程中含有cache 一致性的保护操作。所以这些 API 的调用 cycle 数很大程度上取决于它对多大的数据缓冲区做了 cache 一致性的保护。本文测验这些 cycle 的场景运用的数据缓冲区的巨细是是 4096 words(32bit)。
2、根据 OpenEM 的大矩阵乘完成
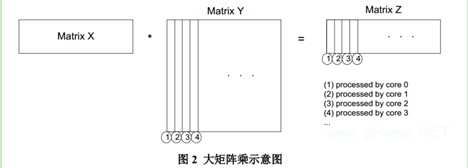
大矩阵相乘的意图是核算 X*Y = Z
矩阵 X 是(100 × 2048 )的浮点实数矩阵。
矩阵 Y 是(2048 × 2048 )的浮点实数矩阵。
矩阵 Z 是(100 × 2048 )的浮点实数矩阵。
因为矩阵 Y 的数据量很大,所以在多核 DSP 上能够把它拆分红多个子块,交给多个 DSP 核并行核算。如图 2 所示。
2.1 根据 OpenEM 的大矩阵乘方案规划
2.1.1 Memory 运用