——以用户形式发生irq中止为例
以下代码依据内核linux2.6.38.3(trimslice官网下载)
本文首要剖析ARM发生中止时的处理流程,以在usr态发生IRQ为例,即usr—>irq为例评论。
1.内核反常向量表的初始化
1.1初始化大致流程
ARM linux内核发动时,首要运转的是linux/arch/arm/kernel/head.S,进行一些初始化作业,然后调用main.c->start_kernel()函数,从而调用trap_init()(或许调用early_trap_init()函数进行初始化)、init_IRQ()函数进行中止初始化、树立反常向量表.
1.2反常向量表的树立
反常向量表的树立进程便是复制进程,为了将内核代码写成方位无关的,有许多当地需求留意。
1.2.1反常向量表基地址确认
在ARM V4及V4T今后的大部分处理器中,中止向量表的方位能够有两个方位:一个是0x00000000,另一个是0xffff0000。能够通过CP15协处理器c1寄存器中V位(bit[13])操控。V和中止向量表的对应联系如下:
V=0 ~ 0x00000000~0x0000001C
V=1 ~ 0xffff0000~0xffff001C
注:CP15操控寄存器阐明详见ARM ARMB4-1690.
在反常向量表初始化前运转的文件linux/arch/arm/kernel/head.S中设置了CP15寄存器(在~/arch/arm/mm/proc-v7.S文件中的__v7_setup函数中设置),这儿通过设置CP15的c1寄存器现已确认了反常向量表的基地址(0xffff0000)。
1.2.2 反常向量表复制进程
内核代码编译生成后,需求将反常向量表复制到指定方位(0x00000000 or 0xffff0000),这就需求将内核中的反常向量表规划成与方位无关的。
本文所运用内核版别运用了early_trap_init()替代trap_init()来初始化反常。
early_trap_init()在linux/arch/arm/kernel/traps.c中,代码如下:
1、CONFIG_VECTORS_BASE在处理器类型确认后就现已确认,其值在内核装备完结后主动生成,保存在.config文件中。本文运用内核版别在maketrimslice_deconfig后主动生成的.config中界说:CONFIG_VECTORS_BASE=0xffff0000,也便是说,反常向量表的基地址0xffff0000。
|
~/arch/arm/kernel/traps.c line783 void __init early_trap_init(void) { #if defined(CONFIG_CPU_USE_DOMAINS) unsigned longvectors = CONFIG_VECTORS_BASE; //vectors是中止向量基地址 #else unsigned long vectors = (unsigned long)vectors_page; #endif /*以下这些都在arch/arm/kernel/entry-armv.S下界说*/ extern char __stubs_start[], __stubs_end[]; extern char __vectors_start[], __vectors_end[]; extern char __kuser_helper_start[], __kuser_helper_end[]; int kuser_sz = __kuser_helper_end – __kuser_helper_start; /* * Copy the vectors, stubs and kuser helpers (in entry-armv.S) * into the vector page, mapped at 0xffff0000, and ensure these * are visible to the instruction stream. */ /*__vectors_end至__vectors_start之间为反常向量表。__stubs_end至__stubs_start之间是反常处理的方位。这些变量界说都在arch/arm/kernel/entry-armv.S中*/ memcpy((void *)vectors, __vectors_start, __vectors_end – __vectors_start); memcpy((void *)vectors + 0x200, __stubs_start, __stubs_end – __stubs_start); memcpy((void *)vectors + 0x1000 – kuser_sz, __kuser_helper_start, kuser_sz); /* * Do processor specific fixups for the kuser helpers */ kuser_get_tls_init(vectors); /* * Copy signal return handlers into the vector page, and * set sigreturn to be a pointer to these. */ memcpy((void *)(vectors + KERN_SIGRETURN_CODE – CONFIG_VECTORS_BASE), sigreturn_codes, sizeof(sigreturn_codes)); memcpy((void *)(vectors + KERN_RESTART_CODE – CONFIG_VECTORS_BASE), syscall_restart_code, sizeof(syscall_restart_code)); flush_icache_range(vectors, vectors + PAGE_SIZE); modify_domain(DOMAIN_USER, DOMAIN_CLIENT); } |
以下是__vectors_start, __vectors_end,__stubs_end__stubs_start的界说。
|
arch/arm/kernel/entry-armv.S .globl__vectors_start __vectors_start: ARM( swi SYS_ERROR0 ) THUMB( svc #0 ) THUMB( nop ) W(b) vector_und + stubs_offset W(ldr) pc, .LCvswi + stubs_offset W(b) vector_pabt + stubs_offset W(b) vector_dabt + stubs_offset W(b) vector_addrexcptn + stubs_offset W(b) vector_irq + stubs_offset W(b) vector_fiq + stubs_offset .globl__vectors_end .globl__stubs_start __stubs_start: /* * Interrupt dispatcher */ vector stub irq,IRQ_MODE,4 //vector_stub是一个宏,翻开后是一块代码,后边紧跟着跳转表 .long __irq_usr @ 0 (USR_26 / USR_32) .long __irq_invalid @ 1 (FIQ_26 / FIQ_32) .long __irq_invalid @ 2 (IRQ_26 / IRQ_32) .long __irq_svc @ 3 (SVC_26 / SVC_32) .long __irq_invalid @ 4 …… …… …… …… .globl__stubs_end __stubs_end: .equ stubs_offset, __vectors_start + 0x200 – __stubs_start vector_stub irq, IRQ_MODE, 4翻开后如下: // ——————————– begin翻开 .align5//将反常进口强制进行2^5字节对齐,即一个cache line巨细对齐,出于功用考虑 vector_irq: sublr, lr, 4//需求调整pc回来值,关于irq反常,将lr减去4,关于其他反常需求作出不同调整 @ Save r0, lr_ @ (parent CPSR) @ stmiasp, {r0, lr}@ save r0, lr mrslr, spsr strlr, [sp, #8]@ save spsr @ Prepare for SVC32 mode.IRQs remain disabled. @ mrsr0, cpsr eorr0, r0, IRQ_MODE ^ SVC_MODE) msrspsr_cxsf, r0 @ the branch table must immediately follow this code @ andlr, lr, #0x0f movr0, sp ldrlr, [pc, lr, lsl #2] movspc, lr@ branch to handler in SVC mode // ——————————– end翻开 |
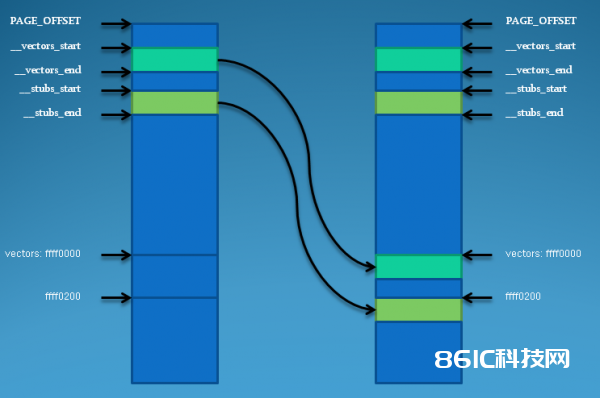
反常向量表的复制进程用图表明比较明晰,如下图所示:
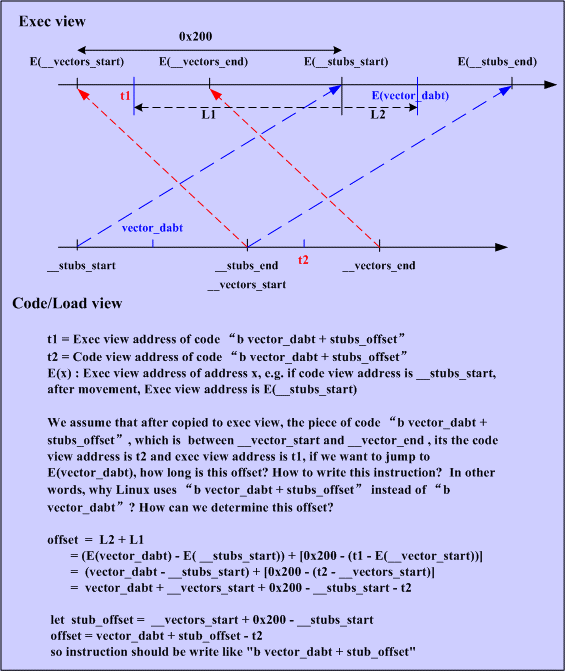
图一 向量表搬移及offset偏移量核算示图
图一阐明:上面两条有方向的横线,横线方向代表地址成长方向,下面那个是Code/Load视图,是搬移前的代码在生成的二进制内核中的安排状况,上面的Exec view是代码在内存中开端履行后的分配状况。
2.linux对ARM反常、中止的处理流程
2.1当IRQ发生时,硬件完结的操作
R14_irq= address of next instruction to be executed + 4/*将寄存器lr_mode设置成回来地址*/
SPSR_irq = CPSR /*保存处理器当时状况、中止屏蔽位以及各条件标志位*/
CPSR[4:0] = 0b10010 /*设置当时程序状况寄存器CPSR中相应的位进入IRQ形式*/
CPSR[5] = 0 /*在ARM状况履行*/
/*CPSR[6] 不变*/
CPSR[7] = 1 /*制止正常中止*/
If high vectors configured then
PC=0xFFFF0018 /*将程序计数器(PC)值设置成该反常中止的中止向量地址,从
*而跳转到相应的反常中止处理程序处履行,关于ARMv7向量表遍及是0xFFFF0018
*/
else
PC=0x00000018
2.2 指令流跳转进程
以上CPU操作完结后,PC跳转到0xFFFF0018,该地址便是指令W(b) vector_irq + stubs_offset地点地址。然后跳转到vector_stub irq,IRQ_MODE, 4,去履行相应的反常、中止处理函数。
接下来详细看代码:
|
.globl __vectors_start //反常向量表开端0xFFFF0000 __vectors_start: ARM( swi SYS_ERROR0 ) THUMB( svc #0 ) THUMB( nop ) W(b) vector_und + stubs_offset W(ldr) pc, .LCvswi + stubs_offset W(b) vector_pabt + stubs_offset W(b) vector_dabt + stubs_offset W(b) vector_addrexcptn + stubs_offset W(b) vector_irq + stubs_offset //中止发生后的跳转地址0xFFFF0018 W(b) vector_fiq + stubs_offset .globl __vectors_end __vectors_end: |
stubs_offset仅仅个偏移量,用来批改跳转地址的,首要的操作是vector_irq履行。vector_irq是由宏vector_stub irq,IRQ_MODE,4(IRQ_MODE在include\asm\ptrace.h中界说:0x12)生成。以下是vector_irq生成后的代码(汇编代码中,@开端的句子、//、//都代表注释):
|
.align 5 vector_irq: sub lr, lr, 4//由于反常发生时,cpu将pc地址+4赋值给lr,这儿做批改。 @ Save r0, lr_ @ (parent CPSR) @ stmia sp, {r0, lr}//保存r0, lr,到irq仓库中(每个反常都有归于自己的仓库) mrs lr, spsr //lr保存spsr_irq的值,即usr状况的cpsr的值(见2.1) str lr, [sp, #8]//保存spsr到[sp+8]处 @ Prepare for SVC32 mode. IRQs remain disabled. @ mrs r0, cpsr eor r0, r0,#( IRQ_MODE ^ SVC_MODE| PSR_ISETSTATE) // PSR_ISETSTATE:挑选ARM/Thumb指令集 msr spsr_cxsf, r0//这儿的cxsf表明从低到高别离占用的4个8bit的数据域 |
异或运算是能够交流方位的,也即A^B^C等价于A^C^B。所以这儿的r0^( IRQ_MODE ^ SVC_MODE| PSR_ISETSTATE)等价于r0^ IRQ_MODE ^SVC_MODE,由于r0的低5位形式位与IRQ_MODE相同,所以r0^ IRQ_MODE的运算成果的低5位全被清零,然后再^SVC_MODE,也即低5位被设置为SVC_MODE,其它位坚持不变。
|
@ the branch table must immediately follow this code and lr, lr, #0x0f//提取发生反常前的处理器形式,这儿也便是usr形式 mov r0, sp ldr lr, [pc, lr, lsl #2] movs pc, lr |
sp是SVC32形式下的仓库指针,这儿将它移到r0中,就能够作为C函数的第一个参数,即C函数中的pt_regs参数。
pc是当时地址+8,也便是本段代码后边紧跟的跳转表的基地址,lr用于在跳转表中索引,lr左移两位等同于*4,由于每个条目是4字节。从usr形式进入irq形式,则lr=pc+4*0,若从svc形式进入irq,则lr=pc+4*3,即__irq_svc的地址,其他地址进入__irq_invalid犯错处理,由于不能从其他形式进入irq反常。
假定这儿是从usr进入irq,则履行跳转表中的第一条指令。跳转的基准地址为当时pc,由于ARMv4是三级流水线结构的,它总是指向当时指令的下两条指令的地址,虽然今后版别的指令流水线扩展为5级和8级,可是这一特性一向被兼容处理,也即pc(excute)=pc(fetch) + 8,其间:pc(fetch)是当时正在履行的指令,便是之前取该指令时分的PC的值;pc(execute):当时指令履行的,核算中假如用到pc,是指此刻pc的值。
当mov指令的方针寄存器是PC,且指令以S完毕,则它会把spsr的值康复给cpsr,上面提到当时的spsr中保存的是r0的值,即svc形式。所以本条指令是跳转到__irq_usr的一起将处理器形式转为svc形式。反常处理一定要进入svc形式的原因是:反常处理一定要进入PL1特权级;另一个原因是使能嵌套中止。详细原因在问题4中解说。关于__irq_svc和__irq_invalid暂时不评论。
|
/* * Interrupt dispatcher以下跳转表有必要紧跟在vector_irq之后 */ vector_stub irq, IRQ_MODE, 4 //生成vector_irq /*从用户态进入中止的处理函数*/ .long __irq_usr @ 0 (USR_26 / USR_32) .long __irq_invalid @ 1 (FIQ_26 / FIQ_32) .long __irq_invalid @ 2 (IRQ_26 / IRQ_32) /*从SVC进入中止的处理函数*/ .long __irq_svc @ 3 (SVC_26 / SVC_32) .long __irq_invalid @ 4 .long __irq_invalid @ 5 .long __irq_invalid @ 6 |
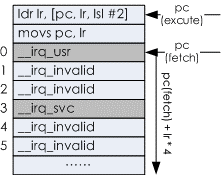
图2IRQ中止处理跳转示意图
留意,以下操作都是在svc形式中,由于要借用SVC形式进行ISP处理,所以需求保存一切SVC形式下的寄存器到SVC仓库中,最终才去调用中止服务例程(ISP)irq_handler。
2.2.1 __irq_usr
|
.align 5 __irq_usr: usr_entry //用于用户形式下发生中止时初始化中止处理仓库,一起保存一切SVC态寄存器到仓库。 kuser_cmpxchg_check //对低版别的ARM核来说,用户态无法完结原子比较交流。假如用户态在处理原 //子比较交流的进程中发生中止,需求特别处理,略过 get_thread_info tsk //依据当时sp指针,将该指针最右边13位清0,取得当时使命的thread_info #ifdef CONFIG_PREEMPT//假如能够抢占,递加使命的抢占计数 ldr r8, [tsk, #TI_PREEMPT]//T被界说为offsetof(struct thread_info, preempt_count),明显通过tsk就 能够很简略得到进程preempt_count成员的地址了 add r7, r8, #1 @ increment it str r7, [tsk, #TI_PREEMPT] #endif irq_handler //中止服务例程,后边剖析 #ifdef CONFIG_PREEMPT ldr r0, [tsk, #TI_PREEMPT]//取得当时的抢占计数 str r8, [tsk, #TI_PREEMPT]//并将r8中的值保存回去。相当于将前一步递加的抢占计数减回去了 teq r0, r7//r0,r7是调用irq_handler前后的抢占计数,这儿进行比较,是防止驱动的ISR //程序没有配对操作抢占计数导致体系过错。 ARM( strne r0, [r0, -r0] )//假如抢占计数被损坏,则强制写入0. THUMB( movne r0, #0 ) THUMB( strne r0, [r0] ) #endif mov why, #0 b ret_to_user //回来到用户态 UNWIND(.fnend ) ENDPROC(__irq_usr) |
接下来别离看各个函数的功用
|
arch/arm/include/asm/ptrace.h struct pt_regs { unsigned long uregs[18]; }; #endif /* __KERNEL__ */ #define ARM_cpsr uregs[16] #define ARM_pc uregs[15] #define ARM_lr uregs[14] #define ARM_sp uregs[13] #define ARM_ip uregs[12] #define ARM_fp uregs[11] #define ARM_r10 uregs[10] #define ARM_r9 uregs[9] …… #define ARM_ORIG_r0 uregs[17] |
pt_regs结构体界说,后边要用到。
|
.macrousr_entry //usr_entry宏界说 UNWIND(.fnstart ) UNWIND(.cantunwind ) @ dont unwind the user space sub sp, sp, #S_FRAME_SIZE @ S_FRAME_SIZE界说在trimslice-kernel\arch\arm\kernel\arm-offsets.c中S_FRAME_SIZE被界说为sizeof(struct pt_regs)的巨细=18*4=72字节,将svc32仓库指针向低地址方向移动一个pt_regs结构巨细,用于保存svc形式下的寄存器现场。 ARM( stmib sp, {r1 – r12} )@向svc32仓库中保存寄存器现场 THUMB( stmia sp, {r0 – r12} ) ldmia r0, {r3 – r5}@前面r0寄存的是irq形式下的栈指针sp的值,从栈中取出r0-r2寄存到r3-r5中 add r0, sp, #S_PC@ here for interlock avoidance;S_PC界说为offsetof(struct pt_regs, ARM_pc),所 以这儿通过add指令将r0指向ARM_pc mov r6, #-1 @r6中保存-1 str r3, [sp] @ save the “real” r0 copied从中止栈中取出实在的r0寄存到pt_regs->r0中。 @ from the exception stack |
2.2.2 usr_entry
|
@ We are now ready to fill in the remaining blanks on the stack: @ @ r4 – lr_ @ r5 – spsr_ @ r6 – orig_r0 (see pt_regs definition in ptrace.h) @ @ Also, separately save sp_usr and lr_usr @ stmia r0, {r4 – r6}//stmia将svc形式下的寄存器r4-r6保存到ARM_pc,ARM_cpsr和 ARM_ORIG_r0,明显ARM_ORIG_r0保存了-1(r6)这个常量 ARM( stmdb r0, {sp, lr}^ )//stmdb指令的^标志表明存储发生中止的形式下的sp,lr寄存器 到ARM_sp和ARM_lr中。 THUMB( store_user_sp_lr r0, r1, S_SP – S_PC ) @ Enable the alignment trap while in kernel mode alignment_trap r0//alignment_trap在装备CONFIG_ALIGNMENT_TRAP时有用,假如敞开了该选 //项,中止处理中将支撑对齐盯梢 @ Clear FP to mark the first stack frame zero_fp//zero_fp用来设置fp栈帧寄存器为0 #ifdef CONFIG_IRQSOFF_TRACER bl trace_hardirqs_off #endif .endm@usr_entry宏界说完毕 |
以上的指令的效果能够总结如下,其间将一般寄存器r1到r12保存到ARM_r1- ARM_r12,这相当于把发生中止时的寄存器r1-r12进行了保存。接下来保存中止发生时的r0,lr_irq和spsr_irq保存到r1-r3,r4赋值为-1,它们接下来将被运用。接下来保存r0到ARM_r0,lr_irq,spsr_irq和-1到ARM_pc ARM_cpsr ARM_ORIG_R0,留意到stmdb指令中的”^”,它保存sp_usr和lr_usr别离到ARM_sp和ARM_lr,明显这儿将一切中止发生时的寄存器都进行了保存。
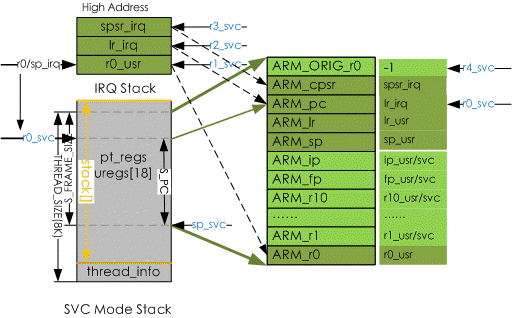
图3 保存中止仓库
2.2.3 get_thread_info
get_thread_info宏用来依据当时的sp值,通过lsr和lsl别离右移左移13位,相当于对sp向下圆整到8K对齐。这儿也便是thread_info地点的地址。
|
arch/arm/kernel/entry-header.S .macroget_thread_info, rd mov \rd, sp, lsr #13 mov \rd, \rd, lsl #13 .endm |
|
linux/arch/arm/kernel/entry-armv.S /* * Interrupt handling. Preserves r7, r8, r9 */ .macroirq_handler #ifdef CONFIG_MULTI_IRQ_HANDLER ldr r5, =handle_arch_irq mov r0, sp ldr r5, [r5] adr lr, BSYM(9997f) teq r5, #0 movne pc, r5 #endif arch_irq_handler_default 9997: .endm |
2.2.4 irq_handler
linux/arch/arm/kernel/entry-armv.S
/*
* Interrupt handling. Preserves r7, r8, r9
*/
.macroirq_handler
#ifdefCONFIG_MULTI_IRQ_HANDLER
ldr r5,=handle_arch_irq
mov r0,sp
ldr r5,[r5]
adr lr,BSYM(9997f)
teq r5,#0
movne pc,r5
#endif
arch_irq_handler_default
9997:
.endm
2.2.5 arch_irq_handler_default
irq_handler是真实的IRQ中止处理进口,在中止处理中需求预留r7,r8和r9寄存器。它们被用来处理内核抢占。在没有装备MULTI_IRQ_HANDLER 的状况下,irq_handler的逻辑很简略,便是简略的调用arch_irq_handler_default。
假如装备了该选项,渠道代码能够修正全局变量:handle_arch_irq,这儿只评论默许完结.
|
arch/arm/include/asm/entry_macro_multi.S /* * Interrupt handling. Preserves r7, r8, r9 */ .macroarch_irq_handler_default //get_irqnr_preamble用来获取中止状况寄存器基地址 get_irqnr_preamble r5, lr//将中止操控器的状况寄存器的地址存储到r5 1: get_irqnr_and_base r0, r6, r5, lr//判别中止号,通过r0回来 movne r1, sp//假如还存在中止,就将sp作为第二个参数,调用asm_do_IRQ。sp现在指向pt_regs @ @ routine called with r0 = irq number, r1 = struct pt_regs * @ adrne lr, BSYM(1b)//这儿将lr设置为get_irqnr_and_base的第二条指令,由于第2次循环时,不用履行其第一条指令(加载寄存器基址) bne asm_do_IRQ //将中止号、pt_regs(中止前的寄存器现场)传递给asm_do_IRQ。asm_do_IRQ回来时, //会回来到get_irqnr_and_base处,直到一切中止都现已处理完毕才退出循环。 #ifdef CONFIG_SMP//针对SMP体系的处理 /* * this macro assumes that irqstat (r6) and base (r5) are * preserved from get_irqnr_and_base above */ ALT_SMP(test_for_ipi r0, r6, r5, lr)//这儿是从寄存器中读取ipi标志 ALT_UP_B(9997f) movne r1, sp adrne lr, BSYM(1b)//同理,这儿也是将回来地址设置为ALT_SMP的第二条指令,构形成一个循环 bne do_IPI//只需存在IPI就调用do_IPI,并循环直到处理完一切IPI #ifdef CONFIG_LOCAL_TIMERS//同理,这儿循环处理多核体系中的本地时钟中止。 test_for_ltirq r0, r6, r5, lr movne r0, sp adrne lr, BSYM(1b) bne do_local_timer #endif #endif 9997: .endm |
2.2.6 get_irqnr_preamble
get_irqnr_preamble用于取得中止状况寄存器基地址,特定于CPU,这儿CPU用的是tegra,其界说如下
|
/* arch/arm/mach-tegra/include/mach/entry-macro.S /* Uses the GIC interrupt controller built into the cpu */ #define ICTRL_BASE (IO_CPU_VIRT + 0x40100)// #define IO_CPU_VIRT 0xFE000000 .macroget_irqnr_preamble, base, tmp movw \base, #(ICTRL_BASE & 0x0000ffff) movt \base, #((%&&&&&%TRL_BASE & 0xffff0000) >> 16) .endm |
2.2.7 get_irqnr_and_base
get_irqnr_and_base用来获取中止号。
|
/* arch/arm/mach-tegra/include/mach/entry-macro.S .macro get_irqnr_and_base, irqnr, irqstat, base, tmp ldr \irqnr, [\base, #0x20] @ EVT_IRQ_STS cmp \irqnr, #0x80 .endm |
get_irqnr_preamble和get_irqnr_and_base两个宏由machine级的代码界说,意图便是从中止操控器中取得IRQ编号,紧接着就调用asm_do_IRQ,从这个函数开端,中止程序进入C代码中,传入的参数是IRQ编号和寄存器结构指针,
2.2.8 asm_do_IRQ

图4 asm_do_IRQ流程图
asm_do_IRQ是ARM处理硬件中止的中心函数,第一个参数指定了硬中止的中止号,第二个参数是寄存器备份组成的一个结构体,保存了中止发生时的形式对应的寄存器的值,在中止回来时运用。
|
linux/arch/arm/kernel/irq.c asmlinkage void __exception_irq_entry asm_do_IRQ(unsigned int irq, struct pt_regs *regs) { struct pt_regs *old_regs = set_irq_regs(regs);//取得寄存器值 irq_enter(); /* * Some hardware gives randomly wrong interrupts. Rather * than crashing, do something sensible. */ if (unlikely(irq >= nr_irqs)) { if (printk_ratelimit()) printk(KERN_WARNING “Bad IRQ%u\n”, irq); ack_bad_irq(irq); } else { generic_handle_irq(irq); } /* AT91 specific workaround */ irq_finish(irq); irq_exit(); set_irq_regs(old_regs); } |
2.2.9 irq_enter
irq_enter是更新一些体系的计算信息,一起在__irq_enter宏中制止了进程的抢占。虽然在发生IRQ时,ARM会主动把CPSR中的I方位位,制止新的IRQ恳求,直到中止操控转到相应的流控层后才通过local_irq_enable()翻开。那为何还要制止抢占?这是由于要考虑中止嵌套的问题,一旦流控层或驱动程序主动通过local_irq_enable翻开了IRQ,而此刻该中止还没处理完结,新的irq恳求抵达,这时代码会再次进入irq_enter,在本次嵌套中止回来时,内核不期望进行抢占调度,而是要比及最外层的中止处理完结后才做出调度动作,所以才有了制止抢占这一处理。
|
linux/kernel/softirq.c voidirq_enter(void) { int cpu = smp_processor_id(); rcu_irq_enter(); if (idle_cpu(cpu) && !in_interrupt()) { /* Prevent raise_softirq from needlessly waking up ksoftirqd * here, as softirq will be serviced on return from interrupt.*/ local_bh_disable(); tick_check_idle(cpu); _local_bh_enable(); } __irq_enter(); } #define __irq_enter() \ do { \ account_system_vtime(current); \ add_preempt_count(HARDIRQ_OFFSET); \ trace_hardirq_enter(); \ } while (0) |
2.2.10 generic_handle_irq
|
~/include /linux/Irqdesc.h /* * Architectures call this to let the generic IRQ layer * handle an interrupt. If the descriptor is attached to an * irqchip-style controller then we call the ->handle_irq() handler, * and it calls __do_IRQ() if its attached to an irqtype-style controller. */ static inline void generic_handle_irq_desc(unsigned int irq,struct irq_desc *desc) { desc->handle_irq(irq, desc);//调用该irq注册的函数处理,该函数在注册中止时填写irq_desc结构体时指定。 }// handle_irq是个函数指针,它用来完结中止处理器的电流处理。电流处理分为边 //沿跳变处理和电平处理。 static inline void generic_handle_irq(unsigned int irq)//该函数是与体系结构无关的通用逻辑层API { generic_handle_irq_desc(irq, irq_to_desc(irq)); } |
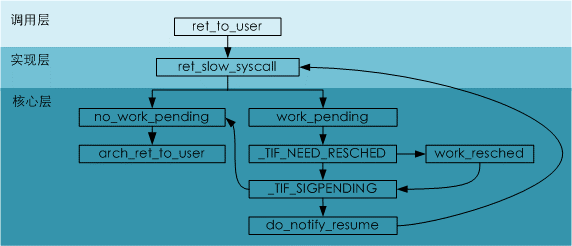
2.2.11 ret_to_user
以上内容处理完毕后,退回用户层。
|
arch/arm/kernel/entry-common.S /* * “slow” syscall return path. “why” tells us if this was a real syscall. */ ENTRY(ret_to_user) ret_slow_syscall: disable_irq @ disable interrupts ldr r1, [tsk, #TI_FLAGS]//从使命的TI_FLAGS标志判别是否需求处理抢占或许信号。 tst r1, #_TIF_WORK_MASK bne work_pending//处理抢占或许信号 no_work_pending: //没有抢占或许信号需求处理,或许现已处理完毕,开端退回用户态 #if defined(CONFIG_IRQSOFF_TRACER)//退回用户态必然会翻开中止,这儿记录下翻开中止的现实,供调试用。 asm_trace_hardirqs_on #endif /* perform architecture specific actions before user return */ arch_ret_to_user r1, lr//在回来用户态前,处理各个体系结构的钩子 restore_user_regs fast = 0, offset = 0//康复寄存器现场,并切回用户态。这儿不再详细剖析康复方法。 ENDPROC(ret_to_user) |
3.问题及回答
问题1:vector_irq现已是反常、中止处理的进口函数了,为什么还要加stubs_offset?( b vector_irq + stubs_offset)
答:(1)内核刚发动时(head.S文件)通过设置CP15的c1寄存器现已确认了反常向量表的开端地址(例如0xffff0000),因而需求把现已写好的内核代码中的反常向量表考到0xffff0000处,只需这样在发生反常时内核才干正确的处理反常。
(2)从上面代码看出向量表和stubs(中止处理函数)都发生了搬移,假如还用bvector_irq,那么实践履行的时分就无法跳转到搬移后的vector_irq处,由于指令码里写的是本来的偏移量,所以需求把指令码中的偏移量写成搬移后的。至于为什么搬移后的地址是vector_irq+stubs_offset,如图一所示。下图是搬移示意图愈加明晰阐明晰搬移进程。。
问题2:为什么在反常向量表中,用b指令跳转而不是用ldr肯定跳转?
答:由于运用b指令跳转比肯定跳转(ldr pc,XXXX)效率高,正由于效率高,所以把__stubs_start~__stubs_end之间的代码考到了0xffff0200开端处。
留意:
由于b跳转指令只能在+/-32MB之内跳转,所以有必要复制到0xffff0000邻近。
b指令是相关于当时PC的跳转,当汇编器看到 B 指令后会把要跳转的标签转化为相关于当时PC的偏移量写入指令码。
通过Uboot的发动,内核跳入linux/arch/arm/kernel/head.S开端履行。
问题1:为什么首要进入head.S开端履行?

问题3:为什么首要进入head.S开端履行?
答:内核源代码顶层目录下的Makefile拟定了vmlinux生成规矩:
# vmlinux image – includingupdated kernel symbols
vmlinux: $(vmlinux-lds)$(vmlinux-init) $(vmlinux-main) vmlinux.o $(kallsyms.o)FORCE
其间$(vmlinux-lds)是编译衔接脚本,关于ARM渠道,便是arch/arm/kernel/vmlinux-lds文件。vmlinux-init也在顶层Makefile中界说:
vmlinux-init := $(head-y)$(init-y)
head-y 在arch/arm/Makefile中界说:
head-y:=arch/arm/kernel/head$(MMUEX T).o arch/arm/kernel/init_task.o
…
ifeq ($(CONFIG_MMU),)
MMUEXT := -nommu
endif
关于有MMU的处理器,MMUEXT为空白字符串,所以arch/arm/kernel/head.O 是第一个衔接的文件,而这个文件是由arch/arm/kernel/head.S编译发生成的。
归纳以上剖析,能够得出结论,非紧缩ARM Linux内核的进口点在arch/arm/kernel/head.s中。
问题4: 中止为什么有必要进入svc形式?
一个最重要原因是:
假如一个中止形式(例如从usr进入irq形式,在irq形式中)中从头答应了中止,并且在这个中止例程中运用了BL指令调用子程序,BL指令会主动将子程序回来地址保存到当时形式的lr(即r14_irq)中,这个地址随后会被在当时形式下发生的中止所损坏,由于发生中止时CPU会将当时形式的PC保存到r14_irq,这样就把刚刚保存的子程序回来地址冲掉。为了防止这种状况,中止例程应该切换到SVC或许体系形式,这样的话,BL指令能够运用r14_svc来保存子程序的回来地址。
问题5:为什么跳转表中有的用了b指令跳转,而有的用了ldr px,xxxx?
W(b) vector_und+ stubs_offset
W(ldr) pc, .LCvswi + stubs_offset
W(b) vector_pabt+ stubs_offset
W(b) vector_dabt+ stubs_offset
W(b) vector_addrexcptn+ stubs_offset
W(b) vector_irq+ stubs_offset
W(b) vector_fiq+ stubs_offset
.LCvswi:
.word vector_swi
由于体系调用反常的代码编译在其他文件中,其进口地址与反常向量相隔较远,运用b指令无法跳转曩昔(b指令只能相对当时pc跳转32M规模)。因而将其地址寄存到LCvswi中,并从内存地址中加载其进口地址,原理与其他调用是相同的。这也便是为什么体系调用的速度略微慢一点的原因。
问题6:为什么ARM能处理中止?
由于ARM架构的CPU有一个机制,只需中止发生了,CPU就会依据中止类型主动跳转到某个特定的地址(即中止向量表中的某个地址)。如下表所示,既是中止向量表。

ARM中止向量表及地址
问题7:什么是High vector?
A:在Linux3.1.0,arch/arm/include/asm/system.hline121 有界说如下:
#if __LINUX_ARM_ARCH__ >=4
#define vectors_high() (cr_alignment & CR_V)
#else
#define vectors_high() (0)
#endif
意思便是,假如运用的ARM架构大于等于4,则界说vectors_high()=cr_alignment&CR_V,该值就等于0xffff0000
在Linux3.1.0,arch/arm/include/asm/system.hline33有界说如下:
#define CR_V (1 << 13) /* Vectors relocated to 0xffff0000 */
arm下规则,在0x00000000或0xffff0000的地址处有必要寄存一张跳转表。
问题8:中止向量表是怎么寄存到0x00000000或0xffff0000地址的?
A:Uboot履行完毕后会把Linux内核复制到内存中开端履行,linux内核履行的第一条指令是linux/arch/arm/kernel/head.S,此文件中履行一些参数设置等操作后跳入linux/init/main.c文件的start_kernel函数,此函数调用一系列初始化函数,其间trip_init()函数完结向量表的设定操作。
参考文献
1. ARM Linux中止向量表搬移规划进程http://blog.chinaunix.net/uid-361890-id-175347.html
2. 《LINUX3.0内核源代码剖析》第二章:中止和反常 http://blog.chinaunix.net/uid-25845340-id-2982887.html
3. Kernel Memory Layout on ARM Linuxhttp://www.arm.linux.org.uk/developer/memory.txt
4.http://emblinux.sinaapp.com/ar01s16.html#id3603818
5. Linux中止(interrupt)子体系之二:arch相关的硬件封装层http://blog.csdn.net/droidphone/article/details/7467436
附录1
Kernel Memory Layout on ARM Linux
Start End Use
————————————————————————–
ffff8000 ffffffff copy_user_page / clear_user_page use.
ForSA11xx and Xscale, this is used to
setupa minicache mapping.
ffff1000 ffff7fff Reserved.
Platformsmust not use this address range.
ffff0000 ffff0fff CPUvector page.
The CPU vectors are mapped here ifthe
CPU supports vector relocation(control
register V bit.)
ffc00000 fffeffff DMA memory mapping region. Memory returned
bythe dma_alloc_xxx functions will be
dynamicallymapped here.
ff000000 ffbfffff Reserved for future expansion of DMA
mappingregion.
VMALLOC_END feffffff Free for platform use, recommended.
VMALLOC_ENDmust be aligned to a 2MB
boundary.
VMALLOC_START VMALLOC_END-1 vmalloc() /ioremap() space.
Memoryreturned by vmalloc/ioremap will
bedynamically placed in this region.
VMALLOC_STARTmay be based upon the value
ofthe high_memory variable.
PAGE_OFFSET high_memory-1 Kernel direct-mapped RAM region.
Thismaps the platforms RAM, and typically
mapsall platform RAM in a 1:1 relationship.
TASK_SIZE PAGE_OFFSET-1 Kernel module space
Kernelmodules inserted via insmod are
placedhere using dynamic mappings.
00001000 TASK_SIZE-1 User space mappings
Per-threadmappings are placed here via
themmap() system call.
00000000 00000fff CPU vector page / null pointer trap
CPUswhich do not support vector remapping
placetheir vector page here. NULL pointer
dereferencesby both the kernel and user
spaceare also caught via this mapping.
Please note that mappings which collidewith the above areas may result
in a non-bootable kernel, or may cause thekernel to (eventually) panic
at run time.
Since future CPUs may impact the kernelmapping layout, user programs
must not access any memory which is notmapped inside their 0x0001000
to TASK_SIZE address range. If they wish to access these areas, they
must set up their own mappings using open()and mmap().