什么是神经网络?为什么它会成为工业图画处理体系的热点话题?由于神经网络不只使开发人员从杂乱的差异化规范界定程序中摆脱出来,还可以自主辨认并学习这一规范,并将这一“才干”运用于准确的使命中。但神经网络并不能坚持继续可靠地运作,也无法主动完成与时俱进的更新。它们有必要先承受专业且深化的培训。本文详细描绘了应该怎么进行这一培训,所需的准备作业以及与树立神经网络有关的各个开发进程。
1 简介
1.1 苹果和梨
有人说苹果和桔子底子不具有可比性,而假如谈及机器视觉体系的话,苹果和梨这一组合好像也找不到任何共同点。即便如此,咱们依然急迫地需求可以准确处理不同使命的体系,相似可以依据图画数据区别两种不同类型生果的使命。
一般来说,开发人员总是会堕入“区别两种生果需求依据怎样的规范”这样一个怪圈。可以幻想一个比较简略的区别办法:苹果是淡红色的,而梨是绿色的。这样一来,设定的规范之一即与色彩相关的信息。但请记住:有些苹果也是绿色的,比方当它们还未老练时。因而假如将色彩视作仅有的区别规范,那么不老练的苹果也会被误认为是梨。为确保愈加准确的成果,添加一个衡量规范是很有必要的:比方形状。苹果一般更倾向于圆形,而梨则呈现比较细长的椭圆形。

图1:经过依据相机的机器视觉体系可视化呈现苹果和梨的分类成果。
在这个分类示例中,对物体进行区别明显是比较简略的。拟定这一区别规范(一般称为“特征辨认”)并不难。那么当咱们需求对不同品种的苹果进行分类时,又该怎么做呢?色彩和形状在这种情况下现已不足以成为区别不同苹果的规范。在这个比方中,咱们自定义(“手艺定制”)的特征辨认功用达到了极限。
针对不同方针的区别和分类越困难,关于开发人员来说,规划出一种可以主动检测出不同方针之间不同和特征的演算法就显得愈加重要。
机器学习算法是远景十分宽广的一种东西和处理办法,尤其是卷积神经网络(简称CNN)。卷积神经网络可以主动学习区别不同方针所需的规范。这使得它们不只可以担任最扎手的分类使命,一起也适用于灵活性极高的各种运用事例。
1.2 卷积神经网络(CNN):成功事例
卷积神经网络并不是一个最近才呈现的新概念。早在1968年,加拿大神经生物学家David Hubel与瑞典神经生理学家Torsten Wiesel针对猫科动物视觉皮层进行了协作研讨。视觉皮层是大脑皮层中首要担任将视觉数据处理成可用信息的部分。因而他们的方针是寻求怎么从大脑承受到眼睛所收集的视觉图画信息(比方“我看到一个苹果”)中,获得方针方针有用信息办法的答案。这两名研讨人员给猫演示不同走向的光条,在这一进程中发现视觉皮层的不同细胞会依据光条的走向被激活并做出反响。他们一起还发现杂乱的光线图画,比方眼睛的形状,可以激活视觉皮层更深层部位的细胞。
经过Hubel和Wiesel的尽力,终究研宣布一个可以演绎细胞激活和转发特定图画信息进程的模型。这也为核算机辅佐图画分类建模奠定了根底。
30年后,法国核算机科学家Yann LeCun再次为Hubel和Wiesel所获得的成果所鼓励。他将视觉皮层功用的演绎叠加到一个演算中 — 并从中成功创建出第一个卷积神经网络运用。
但即便如此,卷积神经网络在之后的很多年仍未能适用于实践操作和运用。其间最首要的原因是卷积神经网络需求投入很多的核算才干。运用串行技能处理数据的CPU处理器需求对数据记载挨个进行剖析,意味着在这一网络可以终究运用于作业之前需求花费多年时刻。
直到图形处理器单元(GPU)的呈现,可以对数据完成并行处理,卷积神经网络才再一次被人们记起 — 实践上近年来卷积神经网络的开展现已有了很大的起色。研讨人员对卷积神经网络在笔记辨认、医疗确诊、主动驾驶车辆预警体系,机器人物体辨认以及生物辨认技能运用方面获得的巨大成功感到欣喜。与其它竞争性学习技能比较,卷积神经网络在具有挑战性的运用中一般可以发生更好的成果。包含Google、IBM、微柔和Facebook等大型企业所出资的数十亿美元巨额资金无不体现出其对这一范畴的极大爱好以及这一技能自身所具有的巨大潜力。
卷积神经网络不只需求密布的处理器运作;相同对数据有极大需求。对卷积神经网络进行一次彻底培训,需求输入很多现已分类的图画数据。现在开发人员可以自在拜访与此相关的数据库。最常用的图画数据库之一是ImageNet1。 它包含超越1400万幅分类图画。一起还有一系列针对详细分类问题而存在的专门数据库。比方,一个名为德国交通标志辨认基准的数据库中就保存了5万余幅关于交通标志的图画。在这一比方中,卷积神经网络在2012年测验中获得了高达99.46%的成功率 — 超越人工分类获得的98.84%。可是,在实践进程中,开发人员一般会面对高度专业化的分类问题,因而无法获取自己的图画数据库。但走运的是,现在他们并不需求收集数百万张图画。一项被称为“搬迁学习”的技能小窍门可以大大削减所需的图画数量,有时乃至只需求几百或几千幅图画。
软件仓库的首要部分都可以供开发人员自在运用。现在现已开宣布一系列适用于卷积神经网络的深度学习结构:包含Caffe,Torch和Theano在内的很多软件库都是专为这一课题而研制。2015年11月,Google乃至为此开放了内部机器学习软件TensorFlow,这一软件是从图画查找到Google Photo等多种Google产品的根本组成部分。
卷积神经网络一起也开端在机器视觉运用范畴中发挥越来越大的效果。依据2016年嵌入式视觉联盟进行的嵌入式视觉开发者查询2,77%的受访者标明现在正在或方案即将运用神经网络来处理分类作业。这一趋势正在上升:于2015年3进行的同一项查询显现,仅61%的受访者有此方案。2016年进行的该项查询还发现,86%的卷积神经网络被用于分类算法。这一成果标明,除了像Google或Facebook这样具有巨大规划和丰厚资源的大公司之外,一般的公司也可以自主研制依据卷积神经网络的产品或服务。
2 卷积神经网络开发进程
幻想一下,作为工业级生果分选线的一部分,您确实需求将苹果和梨子区别开,此外还需求依据其质量将不同的生果主动分批。那么接下来即将经过以下进程:
1. 收集图画数据
2. 卷积神经网络结构的规划
3. 履行自学习算法
4. 对培训过的卷积神经网络进行评价(并依据需求对进程1、2、3进行修正)
5. 训练有素的卷积神经网络布置
下述文字将对各进程进行详细介绍。
2.1 收集图画数据
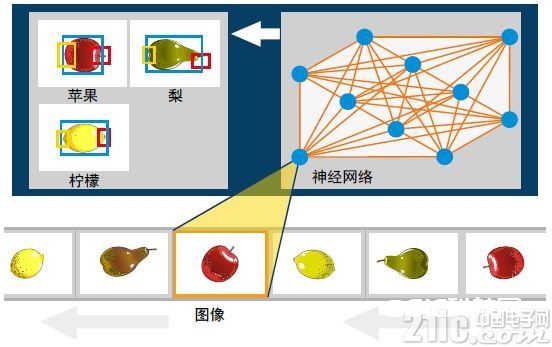
机器学习的根本原理(或许准确地说是“监督式的机器学习”)涉及到怎么运用很多示例教电脑辨认待处理的问题。关于生果分选线来说,这将涉及到拍照很多可以显现不同品种、质量和巨细的苹果和梨的图画。一起,还有必要记载下关于每幅图画最准确翔实的描绘,这意味着一切三个特点(见图2)的详细值(“标签”)。这将创建一组输入/输出对,并经过电脑视觉处理,相当于直接将其展现给“电脑的眼睛”,并由电脑指示哪幅图画应该对应哪个答复(“Braeburn, Class I, Size M”)。
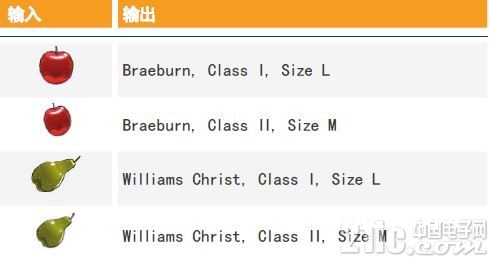
图2:具有附加文本输出的图画数据。神经网络可以运用这些输入/输出对学习区别。
在数据记载进程中,十分重要的一点是需求在图画上展现出需求丈量的一切或许的特点组合(在这种情况下指类型、质量和巨细)。一般来说,有必要留意的是运用程序的视觉改动(不只是生果的类型,一起也包含不同的光源条件,图画中生果的布景和方位等)在图画样本中也有必要有所体现。从实践的视点来看,在终究的出产环境下、以彻底相同的办法拍照图画是比较可取的做法。记载每幅图画中的生果类型、质量和巨细等特点这一使命应该由经过培训的专家进行:只要实践的生果销售者,而不是体系程序员,才有资历正确评价产品的质量。
数据收集进程中发生的别的一个极其重要的问题是所需图画样本的数量:可以幻想,图画差异越大,所需的样本数量就越多。如介绍中所述,相似ImageNet的运用程序或许在短时刻内就需求上百万幅图画。这样的数据收集操作既不实践也不划算,可是明显还有其它的处理办法。与传统的图画处理体系相同,可以在出产环境进行愈加严厉的管控。此外,经过对已拍照图画的色彩,图画偏斜和缩放进行体系改动,所收集的数据量相同可以被人工扩展(数据扩增),并用于新的样本中。当然也可以经过众包办法与服务协作伙伴协作,以完成经济可行的数据收集。
2.2 卷积神经网络结构的规划
由于具有不同层次的各种功用,最顶尖的卷积神经网络技能得以锋芒毕露。与旧式的根底多层感知器4不同,现有的网络由一系列替换卷积层和会聚层组成(见图3)。
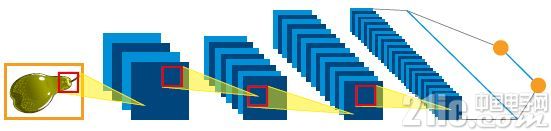
图3:树立一个最顶尖的卷积神经网络。输入(一幅图画)可以经过输出在一系列不同的层之间进行处理。
卷积层经过进行一项数学“卷积”操作将输出图画相邻区域的像素值转换为单个值。卷积运算相似于特征检测器,仅需查找图画中的特定特点(如辨认水平定向边际)。会聚层是在处理链中进一步被树立起来的,它可以总结用于较大图画区域的特征检测器的起伏。这些层形成了一个结实的金字塔结构,发生了越来越多针对更大规模的图画区域进行操作的专门的特征检测器。回到开始的生果分选线上来,可以幻想网络的第一层对应的是具有梨特征的斑驳图画;而相对的上一层则证明特定苹果类型的茎、暗影及上半部分的视觉一致性都可以确保网络终究核算出哪种生果类型、质量和巨细是可见的)。

图4:经过培训的网络具有所谓的特征检测器,使其可以对图画中的特定结构做出相应反响。当网络的第一层更倾向于对具有梨特征的斑驳图画做出反响时,更高层则可以对茎干和暗影的视觉一致性做出反响。
卷积神经网络的准确结构实践上是由开发人员开宣布的网络的变形,如AlexNet5、VGG Net6或GoogLeNet7。在这一进程中一般需求进行必要的调整,由于特定的使命在输入图画的分辨率或可用的核算才干方面会有特定的要求。这些网络是经过上述开源深度学习结构被编程的,这些结构可以供给包含卷积层在内的一切中心元素以作为软件功用之一。依据要求,这需求必定程度的专业知识。一个开始的可行性研讨一般可以经过几项定制内容来完成,而一个实在100%的最优化处理方案则需求富有经验的专家高强度的作业才干完成。
2.3 履行自学习算法
一旦树立起卷积神经网络的数据和规划方案,就有必要相应地履行一项所谓的自学习算法。以不同的变体方法,它将成为被布置的深度学习结构的一部分。这些算法均是依据反向传达算法这一概念,其中心是一个(随机)优化的进程。这些算法担任卷积神经网络自在参数(“权重”)的装备,以便网络可以适用于所供给的数据。因而,自学习算法一般用于卷积神经网络的“培训”。
履行这种自学习算法是运用程序处理方案整个开发进程中最耗费处理器的一个进程:假如您需求运用数百万幅示例图画,那么您需求一个或多个更好的GPU服务器(更多概况请参阅下一节),一般需求花费几天到几周时刻才干进行数据的处理。只要一种办法可以防止这一剩余的杂乱操作:即在您的运用程序中运用搬迁学习技巧。
与网络的规划相同,不同等级的质量预期或许需求相应不同等级的专业知识:每种可用的自学习算法也都具有可以影响其功用的不同参数(如学习或衰减速率,批量巨细等)。还有一些如Dropout,Batch和Layer Normalization procedure这样的小技巧有助于使卷积神经网络终究可以开展得愈加强大和巩固。还有一点有必要清晰的是,没有任何一种自学习算法具有彻底确实定性;它们总是包含随机组件。这意味着开发人员一般有必要对中期成果进行评价,并对算法的履行进行手动更改。
2.4 网络评价
经过自学习算法进行培训的卷积神经网络有必要进行核算评价。为进行这一评价,需求将一组已知内容的样本图画与电脑核算值进行比照。这将发生一个出错率,标明由网络正确辨认出的图画内容特点的百分比。假如成果不符合预设质量要求–比方说,将5%的Braeburn苹果辨认为Granny Smiths是必定不能承受的–那么就有必要回到开始的三个开发进程并对其进行改善。
原则上来说,需求满意该评价所需的数据是随时可用的,由于这些数据正是为了培训网络而收集而来。要害是绝对不要运用在培训进程中现已用的图画来对网络进行测验。这样做会主动导致对体系实在功用的轻视,一起实在的过错只会在出产进程中才被发现。在特别情况下,当测验数据与培训数据彻底一致时,网络会记住这些图画,并在评价进程中做出完美的体现,但在新的图画被输入出产体系中时则会失利。为防止这一问题的呈现,十分重要的一点是怎么布置比方穿插验证这样的进程,从而在培训和评价阶段将数据体系地分隔。
2.5 训练有素的卷积神经网络布置
一旦最终一步获得了令人满意的成果,那么接下来的进程则是将培训后的网络植入出产体系中。最遍及运用的深度学习结构供给了一系列丰厚的东西,可以将网络不同的必要元素整合输入软件,以便它们可以与体系其它组件相衔接,比方与相机衔接或对检测到的图画内容做出的反响进行操控。
假如在卷积神经网络对图画进行评价的进程中对运转功用有特定要求,则会发生额定的作业量。这一般是因培训网络(GPU服务器)时与出产环境下的硬件设置的不同所导致。在某些情况下也有或许会被逼运用特别的办法(如量化法)来削减已培训过的网络,以习惯方针体系的需求。可是,经过完善的网络规划可以防止这种在技能上具有挑战性的行为。
3 搬迁学习
正如此前现已说到的,假如单以其原始的形式来看,卷积神经网络对数据有极大的需求,在培训进程中相同对处理器有着极高需求。好在(关于开发人员来说)总有一种可以简化一切的更好的办法,特别是众所周知的搬迁学习法。这也让现已运用很多通用图画(如ImageNet数据库中的图画)进行培训的网络可以与仅运用少数特定范畴的图画的详细运用进行适配。开发人员向一个网络,如AlexNet,VGG Net或GoogLeNet“展现”运用程序特定的培训图画,然后将成果值贮存在网络最终一层以作为特征向量。这些向量代表的是以高度紧凑的办法展现给网络的图画,而且可以经过规范的机器学习程序(如逻辑回归、支撑向量机或“简略”多层感知器)进行分类。经过这种办法,卷积神经网络可以替代传统的图画处理东西,如Hough transformation、SIFT Feature,Harris Corner或Canny Edge detectors。近年来,科学研讨的比照剖析和许多实践运用都清楚地标明,卷积神经网络中学习的特征向量比传统的手艺特征检测器愈加有用和具有操作性。
4 卷积神经网络处理器
如上所述,在卷积神经网络的开展进程中,培训与运用进程之间的区别是清楚明了的。这两个进程关于硬件的需求是天壤之别的。
培训 – GPU
推理 – FPGA
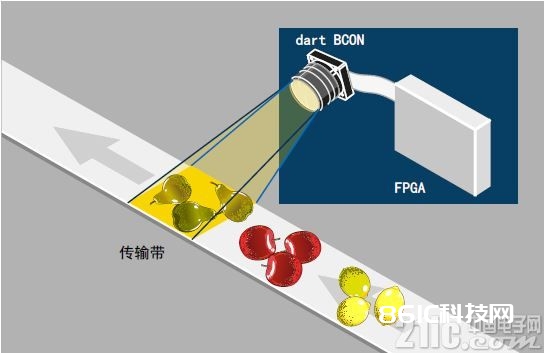
图5:图形处理器单元(GPU)是卷积神经网络培训进程中的首选硬件。关于嵌入式视觉体系中的集成和运用,现场可编程门阵列(FPGA)一般被用作培训后的网络运转所需的处理单元。
在或许的情况下,高功用GPU处理单元应该被用于卷积神经网络的培训进程中。像NVIDIA这样的制造商可以供给专门为此使命而定制的DGX-1这样的AI超级核算机;而运用愈加经济实惠的NVIDIA TitanX卡相同也是可行的。NVIDIA公司陈述指出,它们可以以比一般CPU快80倍的速度对卷积神经网络进行培训。
一旦网络承受了培训,就将被传输至具有低硬件需求和处理单元的嵌入式视觉体系。关于处理单元来说,则引荐运用现场可编程门阵列(FPGA),由于它们可以并行高速处理图画数据。
因而,这种嵌入式视觉体系的要害部件是一台可以记载要分类的图画数据的相机;一根传输该图画数据的线材;以及用于对图画数据进行分类的卷积神经网络处理单元。

图6:适用于卷积神经网络实践运用的嵌入式视觉体系。嵌入式相机(Baslerdart BCON)经过柔性带状线材与具有FPGA(XilinxZynq)的处理单元相衔接。图画数据的分类在FPGA上运转,因而可以进行实时核算。
装备了FPGA的嵌入式视觉体系具有一系列可以完美适用于卷积神经网络的长处:
FPGA可以履行卷积操作和网络所需的其它数学运算,以便对图画进行并行和高速分类使命。此设置供给实时图画剖析和分类功用。
比较GPU,FPGA所需功耗更小,因而更适合低功耗的嵌入式体系。微软研讨院最近发布的一份陈述8显现,FPGA可以比GPU节约10倍功耗。
FPGA的大型片上存储和带宽使卷积神经网络可以对更高分辨率的图画进行实时分类。
可以与FPGA直接衔接的相机(如Basler’s dart BCON相机)可以将数据直接传送到FPGA。这是处理器密布型运用程序(如卷积神经网络)的一个首要优势,由于经过USB传输的数据在抵达FPGA之前有必要经过不同的硬件组件(比方主机操控器)运转。完成相机与FPGA的直接衔接可以确保愈加高效的作业功用。
5 扼要概述
1. 当担任处理传统分类问题的开发人员还在焦头烂额于手动拟定的“特点”或规范时,卷积神经网络现已可以自行学习这些差异化规范。
2. 网络经过运用一组已知内容的图画主动学习差异化规范。在所需图画的数量以及处理才干方面,这是一个高度资源密布型的学习进程。
3. 可是,搬迁学习的原理使得少数图片和处理才干也或许完成出产安排妥当的处理方案。
4. 卷积神经网络十分适用于具有相机与FPGA直接衔接的嵌入式视觉体系(如Basler BCON相机)。
5. 依据2016年嵌入式视觉联盟进行的嵌入式视觉开发者查询9,77%的受访者标明现在正在或方案即将运用神经网络来处理机器视觉运用程序中的分类作业。
作者简介:
Peter Behringer
Basler公司产品商场司理
Peter Behringer自2016年以来担任产品商场司理,担任Basler嵌入式相机在医疗和生命科学范畴的商场。
在参加Basler之前,他获得了吕贝克大学医学工程的理学硕士学位。大学期间,他曾在Charité(柏林大学隶属夏里特医院)以及哈佛医学院外科手术辅佐实验室等闻名组织实习。
Peter Behringer宣布了很多首要针对医学图画处理的科学研讨成果。
Dr. Florian Hoppe
Florian Hoppe是Twenty Billion Neurons GmbH(TwentyBN)的联合创始人兼董事总司理,其责任规模包含事务开展部分等。Hoppe先生具有核算机科学博士学位,一起是一名机器学习进程范畴的出色专家。在创建TwentyBN公司之前,他曾担任IT部分参谋和司理,并一向致力于立异软件体系方面的研讨。