为了下降手机终端的功率损耗[1],LTE上行链路选用依据DFT扩频OFDM(DFTS_OFDM)的单载波传输,又称为单载波FDMA(SC_FDMA)。DFTS_OFDM计划的根本结构如图1所示。3GPP协议规则[2]上行PUSCH信道发生SC_FDMA符号要求DFT点数满意式(1)。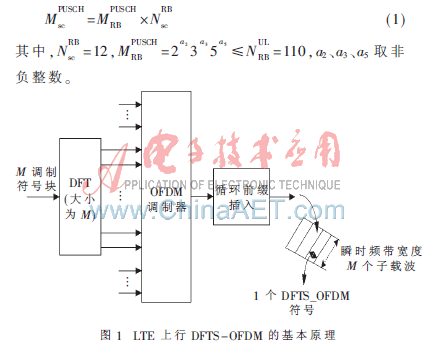
由几个参数的改变能够得到最小12点、最大1 296点共35种办法的DFT[3]。现在已有的研讨办法(如质因子分化结合WFTA算法)解决非2n点DFT,但此法不行灵敏,不适合长度可变的DFT。在数字电视DTMB体系中,3 780点FFT的处理选用割裂基与质因子分化结合WFTA算法完结,但关于LTE上行可装备长度DFT的完结还没有一个老练有用的办法。

依据LTE实时体系需求选用pipeline流水线结构完结高速可装备的DFT规划,一起在结构和资源运用上进行优化,最终给出仿真图形以及归纳成果,为上行LTE规划供给一种参阅。
2 全体结构及技能完结
2.1 全体结构框图
LTE DFT的模块化全体结构如图3所示,依据算法剖析能够知道LTE DFT的分而治之需求几个阶段才干完结,每个阶段需求做屡次小因子点的DFT,所以图示是一个循环的办法。由状态机操控这些阶段的完结,直到最终一个循环完毕输出数据。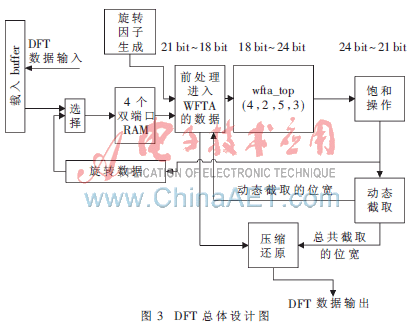
其间前处理进入WFTA模块的包含对4个双端口RAM的读取操控以及对旋转因子ROM的读取,还有旋转因子地址的核算。饱满操作依据体系的最大bit数限制,对经过WFTA核算后的数据进行饱满处理,超越的bit数直接截取掉。
2.2 技能完结
2.2.1 4个双端口RAM的数据存储
为确保pipeline地处理每次循环的数据,这儿选用4个双端口RAM对数据进行存取。对4、2、5、3四种小因子的WFTA核算来说,选4个RAM最便利,假如需求进行4点的WFTA核算,则从每个RAM中读出一个数据,这仅需求一个时钟就可读出4个数据。对2点的WFTA核算,则能够一个时钟读出两组的2点WFTA进行核算。对3点的用一个时钟,关于5点的用两个时钟读取。
在依据原位核算的基础上进行改善,参加旋转数据模块,是为了将原本是在一个RAM中的数据在填入RAM前进行旋转,使其在不同的RAM中便于下一阶段pipeline读取。图4展现了一个最简略的12点的填写RAM实例,在开端榜首阶段前先将12点的输入数经过载入buffer模块用12个clk按图3次序载入4个RAM中,也便是将数据倒位序放入4个RAM中。将倒位序之后的数据从头标号,即1对应载入buffer的3,2对应6等。这样做的意图是为了便利核算地址。例如,在榜首阶段读的过程中,0、1、2、3经过右移2 bit,即除以4能够算出地址为0,它们别离对应4个RAM的第0地址;同理4、5、6、7除以4能够得到1,即对应1地址,依此类推。
依据公式4的推导可知在榜首阶段DFT的处理中不需求乘以旋转因子,所以旋转因子为0,在榜首阶段和第二阶段中需求先乘以旋转因子,旋转因子依照公式推导处理列出在表中。在榜首阶段先处理0、1、2、3四点的WFTA,然后按原位次序填入4个RAM,接着处理4、5、6、7四点的WFTA,原本应该也按原位填入RAM中,可是注意到在第二阶段需求处理0、4、8三点的WFTA,假如还依照原位填入,则0、4、8三个数据在同一个RAM中,要读取这3个数需求3个clk,明显不适应pipeline的处理。所以在做完4、5、6、7四点的WFTA之后将数据旋转再写入4个RAM中,相同将8、9、10、11四点的成果也旋转,如图4所示。这样的读写RAM操作能够确保pipeline的处理。
2.2.2 旋转因子的存取
依据式(4)的推导,每一级之间需求先乘以旋转因子,关于旋转因子的地址核算依据式(4)的推导。由于要完结35种可装备办法的DFT规划,所以在完结时要尽或许地考虑旋转因子的同享存储,然后尽或许地削减存储这些旋转因子的ROM巨细。
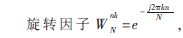 一般做法是将N点的旋转因子悉数存储,然后依据算出来的nk乘积来查找对应的旋转因子,这样35中办法需求许多的ROM地址来存储。这儿将具有2的幂次方联系的旋转因子共用,如12、24、48…768点DFT的旋转因子共用,12点的旋转因子是24点的一部分,24点的是48点的一部分等,这样就只需求存储具有两的幂次方联系的DFT点数的最大那个点768点,又由于旋转因子本身的对称性,只存储最大点数的1/8就能够了,其他部分经过对称性来查找。
一般做法是将N点的旋转因子悉数存储,然后依据算出来的nk乘积来查找对应的旋转因子,这样35中办法需求许多的ROM地址来存储。这儿将具有2的幂次方联系的旋转因子共用,如12、24、48…768点DFT的旋转因子共用,12点的旋转因子是24点的一部分,24点的是48点的一部分等,这样就只需求存储具有两的幂次方联系的DFT点数的最大那个点768点,又由于旋转因子本身的对称性,只存储最大点数的1/8就能够了,其他部分经过对称性来查找。
具体完结过程如下:
(1)依据2的幂次方联系特性,将35种办法的DFT旋转因子分红10组,并存储这10组中最大的点的八分之一构成一个ROM。关于N点(对应组中最大的点),只存储[N/8]个地址数据;
(2)关于核算出的旋转因子地址K,依据它所在的DFT办法,挑选它所属的组,10组别离用{R0,R1,R2,…,R9}表明;
(3)假如K在R5,则R0+R1+R2+R3+R4为它的偏移地址offset;
(4)12点的DFT需求用此组中最大的768点ROM表来找数,则地址K有或许是[0,…,11]×768/12中的一个作为有用地址eff_dft_addr;
(5)关于算出的eff_dft_addr,依据对[N×1/8],…,[N×7/8]的比较找出它处于768点中的哪个方位(此处N为768),即哪个1/8象限;
(6)找出所在的象限后,再找出其在榜首个1/8对称的方位值dft_8_addr,核算出dft_addr=offset+dft_8_addr,然后在ROM表中找出对应的值,再依据对称性复原其本来的所属象限的值。如图5所示,展现一个点的查找办法。经过查找A″的值来得到A的值。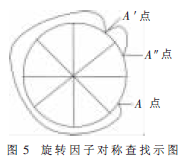
2.2.3 WFTA的运算单元
WFTA算法对2、3、4、5、7、8、9、16等小N点有较快速处理才能,它将小N点DFT转换为循环卷积,运用多项式理论使卷积核算尽或许削减乘法。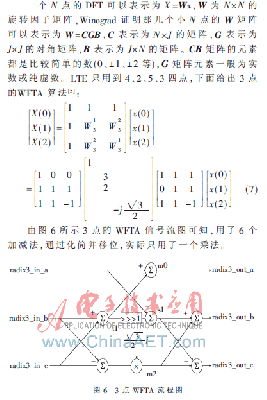
2.2.4 块浮点的数据处理
定点运算的特色是速度快但动态规模小。浮点运算的特色则是动态规模大但占用资源大。块浮点具有两种运算的长处,是两种运算的折中,让一组数具有一起的阶码,这个阶码是同组数中最大的那个数的阶码,简化体系资源进步运算的精度[6]。
如表1所示,由于每次WFTA运算后都有数据位宽的扩展,本结构具有3 bit的扩展。为坚持输入wfta_top的模块数据一直为18 bit,这儿用块浮点动态截取的办法对每一级的WFTA成果进行处理,动态截取的位宽决议下一级的数据宽度,一起循环累加每个阶段的阶码,在数据输出时进行复原操作。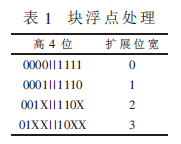
3 仿真归纳
图7所示为12点DFT的仿真图形,dft办法是榜首种,首要data_in_vld为高时开端数据输入,然后用12个clk将数据读入4个RAM,之后核算榜首级RAM读取地址将数据读出,处理3次4点的DFT,处理后将数据写入RAM,需求3个clk;再后读出数据做4次3点的DFT,处理后将数据写入RAM,需4个clk;最终将数据读出做紧缩复原处理,data_out_vld为高后pipeline出数,需求12个clk。理论上需求31个clk,可是在处理中需求处理与其他办法的同享,还要有打拍延时等操作,实践用掉98个clk。120点的DFT实践用502个clk,理论上是120×2+30+30+24+40=364个clk,阐明处理的点数越多冗余clk份额越小。
运用Stratix III EP3SL340F1517I3芯片,运用Quartus II归纳后的成果为:7 824个组合ALUT,0个内存ALUT,8 699个逻辑寄存器,可达到时钟124.64 MHz,满意LTE体系时钟122.88 MHz的要求。
文章在介绍LTE上行SC_FDMA的基础上,对35种办法的DFT预编码进行算法剖析,提出并用FPGA完结了一种高速可装备的计划。文中对数据存储、WFTA运算单元和块浮点处理进行简略表述,依据旋转因子特性,具体介绍了旋转因子的优化,大大下降了35种办法旋转因子的存储巨细。最终给出的仿真归纳成果表明该计划具有较好的功能。