数据发掘便是从存放在数据库、数据仓库或许其他信息库中的很多数据中发掘风趣常识的进程。它是在多种数据存储办法的根底上,凭借有用的剖析办法和东西,从传统的事务型数据库功用(增加、删去、修正、查询、计算等)背面,取得更深层次的信息。在数据发掘技能的不断开展进程中,如何将数据发掘(DM)体系与数据库(DB)体系和数据仓库(DW)体系严密耦合(所谓耦合,便是数据发掘体系和数据库或许数据仓库的集成程度)在一起是一向困扰着人们规划一个好的数据发掘东西的最大问题。从开始的不耦合到松懈耦合再到半严密耦合,人们一向寻求着如何将DM体系滑润的集成到DB/DW中(即严密藕合)。现在很多数据发掘体系、数据发掘东西中,大部分都是完成一个与数据仓库体系独立开来的数据发掘体系,这样便使得数据发掘进程中要花费很多的时刻进行数据加载转化,算法运转时刻长、功率低,特别是面临当时数据仓库中保存的海量数据时,更是功率低下。
文中在已有的数据发掘体系体系根底上,运用数据发掘体系与数据仓库体系严密耦合的战略,提出了嵌入式数据挖模型,把数据发掘体系和整个数据发掘流程彻底控制在数据仓库体系中,然后大大进步数据发掘的功率。并且针对市道的一些用于银行卡事务的数据发掘体系过于繁琐,可是功率不高、针对性不强等问题,本文提出将嵌入式数据发掘运用于银行卡事务中,使得运用针对性更强,在节省了开发本钱的一起也进步了发掘功率。
1 嵌入式数据发掘模型
嵌入式数据发掘模型首要是选用多种数据库拜访技能把算法嵌入到数据发掘体系中。该模型支撑依照必定的标准规范来开发发掘算法,并把算法发布嵌入到多种数据库、数据仓库傍边,将数据发掘进程彻底控制在数据库、数据仓库体系中,将数据发掘功用转化成咱们了解的、通用的、灵敏的、可二次开发的数据仓库功用。
该体系结构首要由数据层、算法嵌入层、数据发掘层以及用户层,体系模型如图1所示。
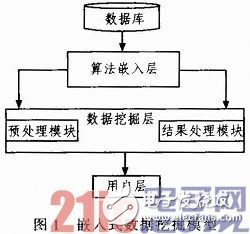
1.1 数据层和用户层
数据层首要包含数据库或数据仓库中的海量事务数据以及元数据,它是数据发掘进程中最根底的部分。
在该模型中,用户层包含算法发布人员、数据剖析人员、数据库办理人员,即便得数据发掘面向更多的用户,摆脱了曾经数据发掘对专业人士的过多依赖性。
1.2 算法嵌入层
整个嵌入流程能够分为两个进程:算法发布和算法调用。算法发布进程首要是把算法发布到特定的数据仓库体系中,为数据发掘体系在数据仓库体系中的履行奠下根底;算法调用进程则是在数据仓库体系中进行的,首要通过数据仓库体系中的存储进程,让用户传人相关参数,然后调用第一步发布的算法对用户指定的数据进行发掘。
1)算法发布
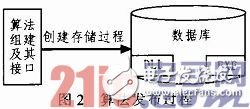
算法发布进程首要便是把算法封装成DLL文件,一起把调用算法的接口编译成EXE文件,然后把算法DLL文件和相应的EXE文件发布到数据库或数据仓库中,最终在相应的数据库中创立存储进程(简称SP),流程如图2所示。
2)算法调用
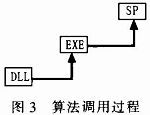
在调用进程中,因为不同数据仓库体系的存储进程的功用巨细不同,不同数据仓库体系对EXE文件,DLL文件的调用办法都有很大的差异,所以详细的完成细节在不同数据仓库体系下仍是有很大的差异的。在该模型中,数据仓库终端调用存储进程(SP),把算法参数和用户参数传进存储进程,然后让存储进程调用EXE文件,EXE文件首要是处理存储进程传入的参数,然后调用DLL算法生成发掘成果。详细流程如图3所示。
1.3 数据发掘层
1)预处理模块
数据预处理在数据仓库(或数据库)中进行,首要有两个途径能够完成:一种是直接运用数据仓库办理体系(SQL等)来对数据仓库的数据表进行加工处理,还有一种便是像发掘算法相同,用高档言语完成,然后嵌入到数据仓库体系中,用户就能够像一般的存储进程相同调用相应的预处理办法来对数据进行预处理。这两种预处理能够彼此循环运用,直到加工满意的数据停止。
2)成果处理模块
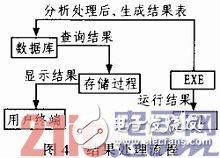
成果处理流程其实和算法凋用进程是一起进行的,在EXE文件中通过数据库拜访技能获取数据,在EXE中调用DLL算法发生文本成果返回到EXE文件中。这时候,这个文本成果能够通过加工处理写回数据仓库,一起也能够展现给用户。详细如图4所示。剖析处理后,生成成果表查询成果。
2 嵌入式数据挖据的运用
2.1 嵌入式数据发掘在银行卡事务中的运用
现在的数据发掘技能在银行卡事务上的运用大多存在3个方面的限制:1)功率不高:面临现在的海量数据发掘时,显得力不从心;2)专业化程度较低:不能很好的专门针对银行卡事务进行发掘;3)开支较大:需求开发专门的体系来进行数据发掘,并且大多数体系不能进行二次开发。
嵌入式数据发掘明显很好的弥补了一般数据发掘技能所带来的缺点。首要,嵌入式数据挖据是把算法直接嵌入到数据仓库下,然后削减数据转化的时刻,充分运用整个数据仓库的处理才能,大大进步数据发掘的功率;其次,它完成了算法的组件化办理,针对不同的职业开发不同的算法组件,对银行卡事务进行数据发掘的首要意图是对客户进行分类,从中发现对银行奉献度较大的优质客户,嵌入式数据发掘能够开发独自的算法专门满意客户分类的需求,然后具有了很好的专业性。最终,嵌入式数据发掘体系是个种很灵敏的数据发掘体系,客户能够在体系中不断增加新的算法、改善算法,一起进行二次开发,然后省去了从头开发大型体系的开支,这点关于当今企业来说显得尤为重要。
2.2 运用实例剖析
为了证明嵌入式数据发掘模型的有用性,咱们与中国银行湖南分行进行了协作,选用其信用卡事务数据分别对嵌入式数据发掘模型体系和非嵌入式数据发掘模型系进行运转比照,测验是在PC机(P4 2.5G CPU,HY DDR512M RAM)上进行的,选取CMP和Apriori两种数据发掘算法。挑选嵌入的数据库为SQL Server 2005试验钱据从10 000条记载到160 000条记载,以测验上述两种算法在巨细不同数据集上选用嵌入式数据发掘和非嵌入式数据发掘所表现出的功能差异。嵌入式数据发掘在银行卡事务中的运用首要包含相关规矩发掘和分类发掘。
1)相关规矩发掘
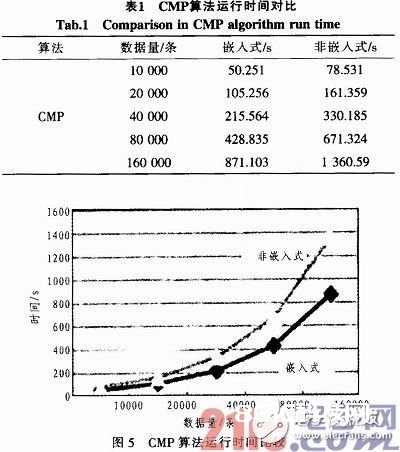
归纳持卡人用卡行为和基本情况进行剖析,导出具有必定支撑度和可信度的用卡习气的人群组成之间的相关规矩。在算法挑选方面,挑选了由wang H等提出的一种新式高效决议计划数算法:CMP算法。在实例中,当实例数据呈倍数增加时,数据发掘所需时刻比照如表1所示。
算法运转功率曲线如图5所示。
2)分类发掘
依据持卡人的运用情况和交易办法,对持卡人群进行分类,首要分为优质客户、潜在优质客户、丢失客户和潜在丢失客户等,这也是当时比较盛行的用法。在分类发掘进程中,运用相关规矩中的Apriori算法对实例进行了数据的发掘,算法时刻比照如表2所示。
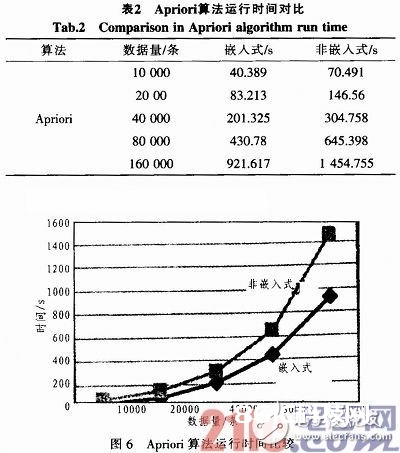
算法运转功率曲线如图6所示。
从以上比照数据能够看出,在将嵌入式数据发掘运用到银行卡事务数据的发掘傍边后,关于两种不同的算法,其功率的进步都是清楚明了的,从图形中能够看出,不管是CMP仍是Apriori,其功率上都有2~3倍的进步。从运用实例中,还能够看出,跟着事务数据量的不断加大,嵌入式数据发掘能更进一步的节省时刻。全体说来,嵌入式数据发掘模型对错常有用的,一起把它运用于银行卡事务数据的发掘中也是切实可行的。
3 结束语
嵌入式数据发掘模型使发掘算法愈加简略易用、便利,它将成为第四代数据发掘体系的一个重要开展方向之一,也是数据仓库体系,商业智能渠道的一个重要开展方向。把新的嵌入式数据发掘技能运用到银行卡事务中,一方面能够验证嵌入式数据发掘技能的优越性,推进数据发掘技能的开展;另一方面,为商务智能运用软件晋级做出奉献,这是一个极具吸引力的课题,具有十分重要的社会效益和经济价值。