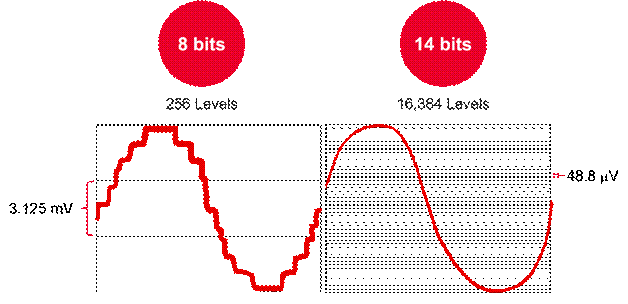
现在支撑消费电子和其它商场的嵌入式体系需求更高档的网络衔接才能。非PCI接口的以太网操控器为体系规划师的嵌入式衔接计划供给了功用和架构挑选的最佳结合。因而,非PCI接口的以太网操控器成为这些嵌入式规划中外设联网的规范处理计划。
一直以来,规划师在对非PCI总线的嵌入式体系添加以太网衔接功用的时分面对多种应战。这些常见的应战包括:为现有的以太网操控器调整非规范的总线接口,满意TCP/IP数据包处理所要求的CPU带宽,使得由于外设和存储器接口结合带来的固有体系功用下降最小化。
为了更好地战胜这些应战,规划师有必要寻求对传统的以太网操控器做出一些改动。其意图是在运用现有的嵌入式CPU的状况下得到一种能进步功用的嵌入式体系处理计划。下面让我们了解怎么完成这个方针。
操控器规划根底
图1介绍了典型的嵌入式体系,其间选用了无PCI接口的嵌入式CPU和相关的存储器(SRAM、SDRAM和闪存)以及经过本地总线衔接的外设(视频、USB和IDE操控器)。嵌入式CPU和操作体系的比方包括英特尔的XScale、瑞萨的SHx、松下及ST的芯片,这些芯片运转Linux、Windows CE、VxWorks和其它实时操作体系(RTOS)。
从操作体系或软件的视点来了解数据怎么从嵌入式体系运用程序到以太网传输非常重要。图2显现了一种嵌入式体系软件结构的完成。软件结构分红运用程序、包括TCP/IP协议栈的操作体系和以太网操控器驱动程序。非PCI接口的以太网操控器经过本地总线与其软件驱动程序衔接。
当运用程序经过网络发送数据或操控信息时,它与操作体系一同产生一个指向不同缓冲区的软件数据结构链表,以防止数据仿制。此外,缓冲区还保存要放入以太网数据包的数据。每块缓冲区代表一个以太网数据包的一个不同的部分,由以太网操控器驱动程序将这些不同的部分组合起来进行传输。数据缓冲区不是彼此附近的,这意味着每块缓冲区的头和尾不在相同的线性地址空间内。
如图2所示,操作体系将“Tx Data Ptr”变量或软件指针传递到以太网操控器软件驱动程序。“Tx Data Ptr”具有描述符1的地址,描述符1指向描述符2,以此类推。这些描述符都指向数据缓冲区。然后,以太网操控器驱动程序经过本地总线将每一块数据缓冲区转移到以太网操控器。
接纳操作按相反的次序履行。这个进程需求许多软件参加,假如处理不妥或许下降功用。相同重要的是不同的数据缓冲区或许没有在存储器中天然地摆放,这关于全体的网络体系功用至关重要。
有限的挑选
当时,选用以太网衔接的消费电子设备只限于下面的三种挑选:
1. 外部PCI以太网操控器——大多数嵌入式处理器不支撑PCI总线,因而挑选一个PCI以太网操控器一般就不可行。如表所示,依据商场研讨标明,商场上8位或16位的CPU都不支撑PCI,并且只要16%的32位CPU支撑PCI,而大多数的嵌入式处理器支撑一种本地/存储总线。嵌入式CPU制造商没有“拥抱”PCI是由于几方面的原因。其一是本钱。用来完成PCI的额定I/O管脚和电路会添加嵌入式处理器的本钱。嵌入式CPU需求一种存储器总线,而在许多状况下,这个总线是与其他外设同享的。因而,添加别的一种宽的并行总线来支撑PCI外围设备并不实际。除此之外,一般在这些嵌入式体系中并不需求像即插即用这样的先进PCI功用。
2. 集成以太网。表显现了内部集成了以太网操控器的嵌入式CPU所占百分比。很显着,大多数嵌入式处理器并不支撑集成的以太网操控器。
3. 外部的非PCI接口以太网操控器如图1所示,大多数嵌入式处理器支撑一种非PCI的本地总线,并且不包括对内部以太网操控器的支撑。 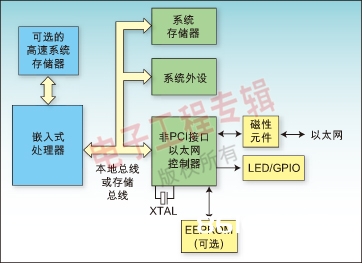
图1:支撑非PCI以太网衔接的典型嵌入式体系
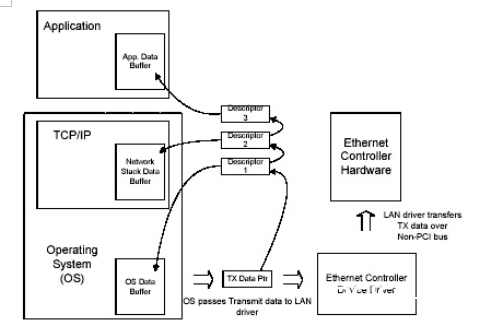
图2:经过以太网发送运用数据
首要规划应战
在为非PCI嵌入式CPU添加高功用以太网衔接功用的应战一般为那些传统上非PCI接口的以太网操控器所疏忽。但是,经过考虑必定的架构改善,非PCI以太网操控器能够供给更高的功用,一起还处理本钱和可靠性的问题。三个首要的应战是缓冲区摆放、总线架构以及流操控。下面将细心地讨论这些问题。
1. 缓冲区摆放
当以太网的帧数据存在于嵌入式CPU的体系存储器中的时分,就产生了以太网帧数据缓冲区的摆放问题。以太网帧数据会被切割开来并涣散到存储器的多个缓冲区中。每个缓冲区片段能够在帧上的任一字节摆放上开端和完毕,并且或许是恣意长度。
未摆放的数据关于传统的以太网操控器来说并不抱负,由于传统的以太网操控器需求将发送数据以32位摆放的方法提交给操控器。由于数据或许以未摆放规整的片断方法抵达驱动程序,驱动程序有必要用CPU来搜集涣散的片断,并在写入以太网操控器之前对数据进行从头摆放。这个进程的功率很低,由于有必要从体系的存储器中读取数据、从头摆放并写入到以太网操控器。比较从体系存储器中读取数据并直接写入到以太网操控器,这个进程至少要三步。
最糟糕的负面影响是与直接存储器拜访(DMA)操控器不兼容。传统上,在嵌入式CPU中的DMA操控器不能履行数据的从头摆放,这使得它们不能在体系中移动以太网数据。数据移动和从头摆放的使命就落到了嵌入式CPU上,其所占用的MIPS原本能够在其它运用中得到更好的运用。
抱负的以太网操控器会主动地处理数据的从头摆放。数据会以天然摆放的方法传递,以太网操控器将了解包的数据鸿沟,然后以太网操控器在数据发送之前在内部通明地对数据进行从头摆放。这种通明的从头摆放经过缓冲区仿制使嵌入式CPU从从头摆放数据的使命中解放出来。现在体系就能够挑选运用简略的DMA操控器来移动数据了。
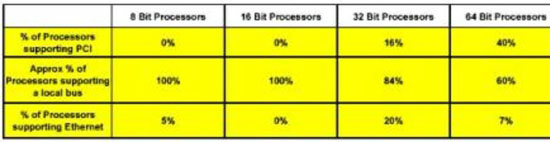
表1:总线类型和对集成以太网操控器的支撑
2. 总线架构
嵌入式CPU为了发送以太网数据包,需求将数据写入到以太网操控器中的缓存内。反之,关于接纳以太网数据包,嵌入式CPU有必要从以太网操控器的内部缓存中读出收到的数据。嵌入式CPU运用编程I/O(PIO)周期或DMA周期移动数据。
不管是运用PIO或DMA进行发送或许接纳操作,数据都是经过嵌入式CPU的外部本地总线传送的。每次操作都需求花费时刻,并且花费的时刻越多,操刁难体系全体功用影响就越大。要害问题是要使拜访以太网操控器时刻很短,以进步整个体系的速度。传统上,低功用的以太网操控器在读和写拜访期间会迫使CPU处于等候状况,这等效于更长的读和写周期。在本地总线上添加更多的等候状况意味着CPU履行其它使命的时刻更少,以及用于内部和外部设备的带宽更少。
其它一些不太显着的机制会导致额定的等候状况。例如,许多的传统以太网操控器需求很长的数据和地址树立时刻。这或许需求额定的衔接逻辑以及锁存器。在这种体系中,或许需求削减体系中每个器材的总线周期时刻-包括存储器。
某些嵌入式CPU选用其它机制来削减外部本地总线上的处理时刻。这种机制的一个实例是突发形式读处理。这种操作形式一般与DMA操控器有关,能够下降总线周期占用。在突发处理期间,操控信号被保持,在每次读操作时地址都改动。一般与PIO读相关的读周期之间的免除保持时刻被消除。传统的以太网操控器不支撑突发形式读。大多数嵌入式处理器自身支撑SRAM类型的本地总线接口。因而优化以太网操控器以模仿SRAM存储器接口很有含义。这样做优势很显着。这种以太网操控器不仅为大多数嵌入式处理器供给一种无缝的接口,并且一切前面现已讨论过的特性都能够运用,比方快速的全体总线周期时刻、最小的地址和数据树立时刻以及支撑突发形式读取等。
3. 流操控
别的一种添加非PCI接口以太网操控器功用的方法是优化以太网流量状况。这能够经过支撑以太网流操控完成。
以太网流操控容许以太网接纳器减缓其对应的发送器的速度,这能够防止接纳器缓存溢出。中止推迟或其它原因会导致嵌入式CPU无法跟上以太网数据接纳的速度,这会导致接纳缓存溢出。一旦呈现溢出,接纳到的数据便会丢掉,然后导致严峻的体系功用下降。
许多以太网设备运用一种“暂停操控”帧支撑全双工流操控。暂停操作在规则的时刻段内制止发送数据帧。暂停操作由由一个暂停操控帧组成,这个帧包括大局分配的多播地址、暂停操作码以及指出数据制止传输的持续时刻的参数组成。当接纳到包括预留的多播地址和暂停操作码的帧时,以太网设备就制止在指定的时刻段内传输数据。在半双工形式,反压(backpressure)用于流操控。以太网操控器经过“阻塞”接纳数据和成心产生抵触来调理数据接纳。在检测到抵触后,远端站点将中止发送数据。
抱负的以太网操控器需求能检测其内部缓存空间,然后在没有处理器的干涉下主动地发送一个暂停帧,或许产生阻塞。并且,设备应该能发送一个“零时刻”的暂停帧,以在内部缓存有可用空间时从头建议数据传送。主动流操控经过削减处理器中止次数和开支进步了体系的全体功用。恰当地完成流操控还能防止网络两头的接纳缓存溢出。
本文小结
消费电子设备、文娱音视频设备以及传统的家庭网络设备(例如PC和打印机)正在向一个网络交融,很显着以太网成为家庭中完成衔接的网络挑选。在许多状况下,关于能够挑选哪种嵌入式CPU用于消费电子或音视频规划,体系规划者的挑选有限。因而,在不换用高本钱的CPU计划的条件下,完成希望的功用水平的仅有方法是优化现有的非PCI接口以太网操控器。经过优化非PCI接口以太网操控器的架构,能够进步要求严苛的运用的全体体系功用。
作者:Charlie Forni
工程总监,charles.forni@smsc.com
Paul Brant
高档首席体系架构师,paul.brant@smsc.com
SMSC公司