当时,线路传输技能开展迅速,光传输技能更是前进飞速,无论是单波长载荷速率仍是单纤可用波长数量,都以惊人的速度增加。现在,已呈现各种10Gbps的接口类型,如POS、LAN、WAN等。作为T比特路由器的中心部分,转发引擎的线速报文转发才干决议了路由器所能够支撑的最高端口速率。T比特路由器中线速转发引擎有必要支撑10Gbps接口,而传统的报文处理结构由于单包处理时刻过长,已无法满意线速转发的功用需求。
1 线速转发引擎的结构规划
转发引擎是高功用T比特路由器的要害部分之一,其规划的合理性、功用的好坏直接影响路由器的全体功用。当时,业界的硬件转发引擎首要有两种计划:一种是根据网络处理器的转发引擎,一种是根据FPGA渠道的转发引擎。本规划选用FPGA作为规划渠道,如此挑选首要是出于以下两点考虑:
(1)现在支撑端口速率为10Gbps的线速处理的商用网络处理器还不老练,尤其是没有自主知识产权、安全性弱、受芯片提供商的限制,所以网络处理器并不是最佳挑选;
(2)选用FPGA是为规划单片转发体系(SOC)奠定根底,终究意图是要完结我国自主的高功用网络处理器。
数据包的10Gbps线速转发,报文转发率到达31.25Mpps以上,支撑IPv4、IPv6和MPLS三种类型报文的处理,支撑IPv4、IPv6优先级分类,支撑组播以及1M路由表项等,都是T比特路由器有必要完结的要害技能指标。为此,10Gbps线速转发引擎选用根据大规模FPGA、TCAM和SRAM的全硬件流水并行结构,使用硬件的高速特性和高可靠性,实时处理路由分组的各项信息并对路由分组进行硬件线速转发。
下面给出一种根据FPGA的转发引擎结构,该引擎选用并行处理方法和流水线结构,有用地降低了报文的处理时刻,完结了对多协议报文的支撑,到达了10Gbps线速转发的功用需求。
2 并行处理结构的规划
并行机制便是对同一段时刻内需求处理的每个使命各选用一个处理通道的并行方法进行操作,从而使多个使命所需的处理时刻降至最少。转发引擎要进行报头剖析、QoS完结、安全检测、直连查看、单播查表、组播查表等处理。并行处理方法便是依照各个功用模块之间在处理次序上的关联性,将以上的功用模块进行并行处理;并尽可能对并行技能进行进一步发掘。以报头剖析模块为例,可进一步分为版本号查看、TTL查看、地址规模查看、有用负载长度查看等四个小模块,从而进行小模块的并行处理。并行处理结构如图1所示。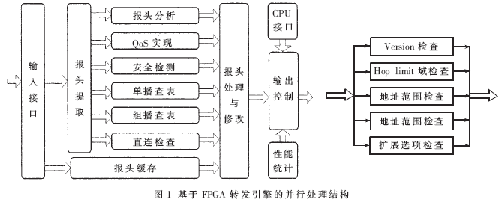
选用并行处理技能之后的总处理时刻仅仅其间要害并行模块的处理时刻,要害并行模块是指一切并行处理模块中处理时刻最长的模块。
3 流水线机制的规划
若要在数据速率高达10Gbps的条件下完结IPv6最短包(长度为40字节)的线速转发,则转发引擎处理一个数据包的最长时刻为:IP报文长度(字节)×8(比特)/端口速率(Gbps)=40×8/10=32ns。即便选用100MHz的时钟,处理时刻也只需3.2个周期,要在如此短的时刻里完结杂乱的IP报文处理,有必要选用流水线规划。
3.1 体系级流水线
根据FPGA的转发引擎内部各大模块间的流水线,本文称为体系级流水线。转发引擎的体系级流水线结构如图2所示。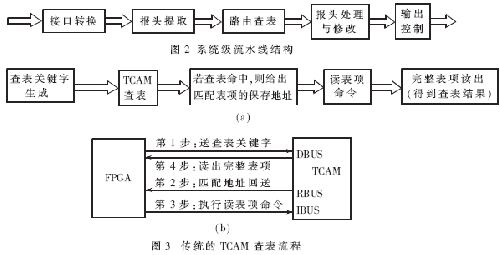
该流水线结构将转发处理分为接口转化、报头提取、路由查表、报头处理与修正、输出操控等五个流水操作子进程。它们都是在时刻上先后履行的串行使命单元,且前后子进程之间的操作彼此独立。转发引擎选用流水线操作今后,只需各子进程能满意给定接口速率下最短报文的处理时刻要求,则整个转发引擎就支撑该接口速率。
3.2 流水线查表规划
在该流水线各段中,需求时刻最长的功用段为路由查表。在查表模块进一步引进流水线规划,能够削减整个转发处理的流水时刻,使之能够满意路由器功用要求。
硬件查表一般由TCAM完结,传统的TCAM查表流程如图3所示。
传统查表由TCAM查找和TCAM读表项两个操作串行进行,无流水线操作,整个进程需求十几个时钟周期。
在本文提出的由TCAM和SRAM共同完结路由查表的流水线结构中,查表分两级进行:由TCAM完结查找进程,再由SRAM读出查表成果。这样可将查表时刻缩短为4个周期。
在本流水查表计划中,TCAM表项仅存储查表要害字,查表成果则存储在SRAM的相应地址空间中。关于单播查表,意图IP地址作为查表要害字保存在TCAM的某个地址中,意图接标语作为查表成果则保存在SRAM中的相应地址空间中,这样就构成一条完好的单播表项。其流程如图4所示。
图4给出了两种流水线规划计划,它们的差异首要在于是否将TCAM的RBUS直接连接到SRAM的地址总线上。
(1) 计划(a)是将TCAM的RBUS直接作为SRAM的读取地址,长处是PCB制造略为简略,削减FPGA中User I/O资源严重的问题,缺陷是写表项的时刻较长。由于写SRAM表项有必要经过相应的TCAM操作才干进行,即写TCAM表项和写SRAM表项均经过TCAM来完结,所以写一条完好表项的时刻为二者处理时刻之和。
(2)计划(b)是将TCAM的成果总线RBUS与SRAM的地址总线经过FPGA连接起来,尽管增加了PCB制造的难度,但由于写表项时TCAM和SRAM的写操作可一起进行,因此写一条完好表项的时刻为这二者处理时刻的较大值。一般TCAM的读写时刻远大于SRAM的读写时刻。
经过TCAM写SRAM表项的时刻往往与独自写TCAM表项的时刻适当,即计划(a)写表项的时刻大大超越计划(b),因此计划(b)具有更好的线速转发功用。
4 工程完结
经过选用并行处理技能和流水线技能规划的转发引擎在实践工程中得到了很好的使用,工程中选用的FPGA为VIRTEX PRO系列的XC2VP70芯片。凭借思博伦通讯公司(Spirent Communications)的Adtech AX/4000网络测验仪结构的测验环境如图5所示。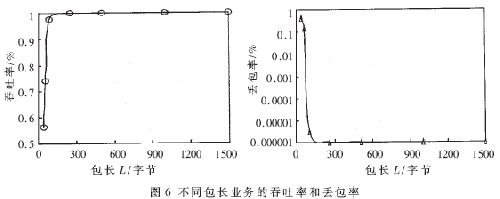
图5中,测验仪与10GPOS线卡相连,双向发送与接纳数据,线卡将10Gbps数据输入转发引擎,再由转发引擎送往高速交流网络。在测验进程中,挑选40、64、128、256、512、1024、1280和1500字节的定长包进行分组转发率和丢包率测验。测验标明,在10G VAN和10G LAN接口下,转发引擎不丢包,即丢包率为0。在10GPOS接口下,转发引擎的吞吐率和丢包率如图6所示。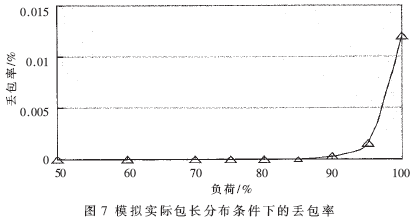
图中标明,在单一包长测验条件下,在负荷为100%、包长大于等于109.5字节时的丢包率低于1.07×10-6%,吞吐率接近于1%,该转发引擎能够完结40字节IPv6报文的10Gbps线速转发。
在测验进程中,还做了模仿实践使用的混合包传输(40字节包占25%,172字节包占20%,360字节包占15%,552字节包占20%,1500字节包占20%)测验。图7表明在模仿实践包长散布条件下,不同负荷时的转发引擎丢包率。
图中所示的测验成果标明,端口负荷低于90%时,丢包率低于3.0×10-4%。以上成果标明,该转发引擎能完结100%报文经过率的10Gbps线速转发。
10Gbps线路接口的呈现,对转发引擎的规划是个极大的应战:在不到4个时钟周期的时刻内,需求完结各种协议类型的报文的线速转发。本文提出的一种根据FPGA的并行流水线转发引擎结构,很好地处理了10Gbps线速转发的问题。该引擎结构现已使用在863严重课题“可扩展到T比特的IPv4/v6 路由器根底渠道及试验体系”中,并经过了测验。
跟着线路传输技能的开展,链路接口速率行将打破40Gbps,这对转发引擎的结构规划又将是进一步的应战,研讨支撑40Gbps的线速转发引擎将是咱们下一步的研讨方向。