导言
面向便携式设备的SoC规划,不仅仅要求功用高、体积小,更要求功耗低。一般来说,SoC的静态功耗很小,而对负载电容充放电的动态功耗很大。
SoC内部,总线上挂着许多功用设备,导致总线的电容负载很大。假如总线与片外设备联络,那么,它还要驱动很长的片外连线以及片外设备,负载高达50pF,比SoC内部各个节点的电容负载0.05pF高出三个量级。一般来说,总线的功耗占SoC总功耗的10%~80%;一个现已对内部电路优化过的SoC,总线功耗约占50%[1]。跟着宽度的添加,总线耗费的功率占 SoC总功率的比重越来越大,因而,总线的低功耗规划很重要。
许多经过削减总线动态翻转来下降总线功耗的算法现已被提出来。数据总线的数据随机性较大,地址总线的地址向量接连性较大。它们传送的数值各有特点,所以,针对不同类型总线的算法也不一样。针对数据总线有bus- invert算法,针对地址总线有PBE (Page-Based Encoding)算法、WZE(Working Zone Encoding)算法等。本文使用地址总线零翻转编码方法,经过规划编码器和解码器的结构,有效地下降SoC地址总线的功耗。
1集成电路功耗剖析
数字集成电路的静态功耗十分小,往往只要nW(纳瓦)级,因而,它的功耗近似等于动态功耗 [2],如式(1)所示:
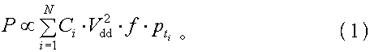
其间,P标明数字%&&&&&%的总功耗;Ci标明电路第i个节点的负载%&&&&&%;Vdd标明电源电压;f标明作业频率;标明t时刻节点i的活动因子,正比于节点i的电平翻转频率。
设参数Cint标明内部节点的均匀负载,Cbus标明总线各位的均匀负载,Nint标明单位时刻一切内部节点的均匀翻转次数,Nbus标明单位时刻总线的均匀翻转次数。那么,式(1)能够简化为式(2):
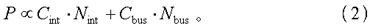
由于内部节点的个数远远大于总线的位数,所以均匀翻转次数Nint远远大于Nbus;而负载Cint却远远小于Cbus。前者大约只要后者的千分之一,所以,式(2)中Nbus具有很大的权重。减小Nbus,能够显著地下降P。
2低功耗规划
2.1地址总线零翻转编解码原理
总线宽度为N,t时刻,总线需发送的数据为Bt。假如Bt与Bt-1持平,则时刻总线状况彻底不变;假如Bt与Bt-1不持平,则t时刻,总线就会产生电平翻转。Bt与 Bt-1不同的比特位数目(0≤≤N)越大,总线电平翻转的位数就越多,功耗就越大。当Bt与Bt-1互为反码,则总线每一位都要翻转,此刻总线翻转的功耗最大。
零翻转编码法使用下降总线的电平翻转次数,来下降总线功耗。界说bt为内核MCU核算出来的t时刻总线数据(即编码前的数据),Bt是t时刻已放到总线上的数据(即编码后的数据),Jt是解码器解码后的数据。
总线接连取址时,相邻两次地址的差是持平的,界说为Stride。一般的ROM寻址Stride=1;对Cache寻址时,Stride依据Cache的寻址特性而定。假如Cache寻址步长是一个word,则Stride=2。
编码需求一个额定的状况信号INC。
零翻转编码的算法过程如下:
①核算bt-1+Stride,比较bt与bt-1+ Stride;
②假如bt=bt-1+Stride,标明是接连寻址,那么Bt= Bt-1,置INC=1;
③假如bt≠bt-1+Stride,标明是不接连寻址,那么Bt=bt,置INC=0;
④接纳端解码器依据INC来处理收到的总线数据。
零翻转解码的算法过程如下:
①核算Jt-1+Stride;
②假如INC=1,标明是接连寻址,那么Jt=Jt-1+stride;
③假如INC=0,标明是不接连寻址,那么Jt=Bt。
中止和跳转子程序的多少,会影响功耗的下降。中止和跳转越少,地址向量接连性越高,零翻转编码后总线电平翻转越少,节约的功耗就越大。当地址总线一向接连寻址时,零翻转法理论上能够到达地址总线的零翻转,而且,Stride变量能够依据寻址目标的不同而设置成对应的数值。
2.2零翻转编解码器电路结构
编码器组成如图1左半部分。D1存放bt-1,加法器将bt-1与Stride相加。比较器EQ比较 bt和bt-1+Stride,输出INC。选择器MUX的两组输入是bt和Bt-1。
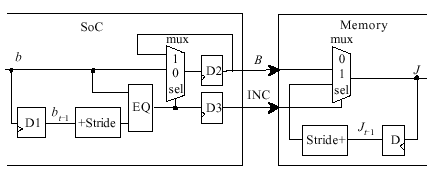
图1零翻转编码器和解码器
编码器是组合逻辑,不可避免的有毛刺。毛刺尽管时刻很短,但仍然会添加总线功耗,因而,使用D2、D3触发器来同步,过滤掉一切的毛刺。
解码器结构如图1右半部分,在接纳设备Memory操控逻辑中完成。存放器D存储Jt-1,MUX的两组输入是(bt-1+Stride)和Bt。它的结构比编码器简略得多。