针对数字匹配滤波器(DMF)的FPGA完结提出一种优化结构。运用16位移位存放器(SRL16E)的存储潜力,规划递归推迟线(RDL);再运用RDL抽头个数倍减而抽头样本速率倍增的特色和时分复用技能,提出DMF的递归折叠结构。该结构以进步作业时钟频率为价值,增大推迟线的采样率以及相关运算单元的吞吐率,然后成倍下降DMF的资源耗费。当选用l/4递归折叠结构时,资源耗费仅为优化前的l/3.
跟着直接序列扩频(DSSS)通讯技能和软件无线电技能的开展,全数字扩频接纳机成为研讨的热门。数字匹配滤波器(DMF)是全数字扩频接纳机的核心部件,它首要用于伪码(PN)快速捕获宽和扩。传统的DMF规划功率较低,当PN码码长较长时,需求占用较多的FPGA资源,本钱较高。作者经过改善推迟线的结构,并结合时分复用技能,提出DMF的递归折叠结构,该结构极大地下降了DMF的资源耗费。
1 DMF的根本结构和参数
DMF是一种抽头距离即码片周期为Tc、抽头系数为扩频序列(取值为±1)的特别的FIR滤波器。其直接型结构由推迟线和相关运算单元(CCU)构成,如图1所示.

推迟线用于保存相关时间规划(LTc)内的一切输入样本,它由L个推迟单元组成。尽管级联多个D触发器是完结推迟单元的最简办法,但它将很多运用D触发器,因而不宜用于构建量化位数大、阶数高的DMF推迟线.FPGA具有丰厚的查找表(LUT)资源,它能够用16位循环移位存放器(SRL16E)完结 l~16个节拍的信号推迟。关于M bit量化、过采样倍数R≤16的DMF来说,结构一个推迟单元需求M个SRL16E.
如图1所示,相关运算单元由L个乘法器和一个倒金字塔形的加法树组成。加法树的第1级有L/2个(M+1)bit二输入同步加法器(参加运算的是推迟抽头样本,字长为M bit,为了防止核算溢出,在相加之前需求进行1 bit的符号位扩展)、第2级有L/2个(M+2)bit二输入同步加法器,……,整个加法树有L- 1个二输入同步加法器。
DMF的量化位数、输入采样率以及作业频率是影响DMF功用的3个要害参数,后两个参数是优化结构的根底,需求细心权衡。
DMF的输入为数字下变频器的输出(数字解调计划)或许模仿基带ADC的输出(模仿解调计划),其量化位数一般都为8 bit以上.DMF的资源耗费近似正比于量化位数,因而需求在这两者之间做出恰当的折衷。文献中给出了DMF的量化精度对解扩功用的影响及DMF量化位数的挑选依据。一般以为高斯信道下DMF挑选3 bit量化较为适宜,此刻量化差错形成的功用丢失不大,再添加量化位数并不能显着改善体系功用。为了叙说的一般性,界说DMF的输入量化位数为M.
采样率是全数字接纳机的要害参数之一,为了下降完结难度,防止采样率改换环节,DMF的采样率一般为接纳机中频或基带ADC的采样率。为了下降对ADC前端模仿滤波器功用的要求并进步PN码同步精度,需求进步采样率。可是采样率的进步将添加接纳机的运算量,然后导致占用更多的FP-GA资源,因而相同需求折衷考虑。工程上采样率一般是chip速率的整数倍,用过采样倍数R表明,R值一般取4~8.
模块的数据处理才能与其并行程度(取决于硬件规划)和吞吐率(取决于作业频率)成正比。在额定数据处理才能下,进步模块的作业频率能够下降对模块并行程度的要求,即作业频率和规划规划是能够交换的。现在干流的高端FPGA的作业频率能够到达200~400 MHz,远远高于DMF的采样率,选用时分复用方法将大大下降硬件资源耗费量。
作者提出的递归折叠型DMF,充分运用SRL16E的存储潜力,用递归结构下降推迟线的资源耗费,然后运用递归推迟线具有抽头个数倍减而抽头样本速率倍增的特色来时分复用相关运算单元,然后下降乘法器和加法器的数量。上述办法可成倍下降DMF耗费的硬件资源。
2 递归推迟线的结构与特色
传统的推迟单元用SRL16E完结R(R≤16)位移位存放,在每个采样周期Ts内,推迟单元中的R个样本悉数右移一位,这样,输入样本经过R×Ts后送到抽头处,然后完结了Tc时延.R位移位操作未能充分运用SRL16E的存储潜力,为此作者提出递归推迟线结构。在该结构中,不管R取何值,SRL16E 都进行16位移位操作。这样保存L×R个输入样本一共需求M×L×R/16个SRL16E,仅为传统结构的R/16.下面结合图2进行时序剖析.
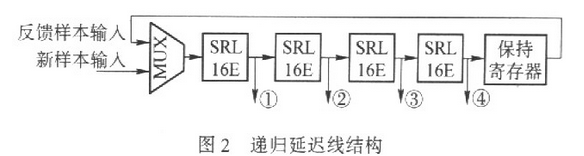
由于SRL16E进行16位移位操作,为了确保当时延等于Tc,移位周期有必要为Tc/16.把R×Ts/16定为推迟线的作业时钟周期,那么作业时钟频率为chip速率的16倍,即采样率的C倍,其间C△16/R,因而每C个作业时钟周期才输入一个新样本。无妨假定新样本在第nC个作业时钟周期(后边简称为时间)到来,其间n为整数。假如时间m是C的整数倍,MUX把新样本推入推迟线,不然MUX把坚持存放器中的旧样本反应到推迟线的输入端。
在nC时间被MUX推入到推迟线进口的样本,在经过L×R个时钟周期后将在nC+L,×R时间被推到坚持存放器中,然后在nC十L×R+l时间(由于该时间不是C的整数倍)将再次被送入到推迟线的进口,……;当该样本第C次进入坚持存放器后,已是C(L×R+n+1)时间,此刻.MUX将选入一个新的样本,而它将被扔掉。这样一个新样本在递归推迟线中刚好循环C次,历时C(L×R+1)时钟周期,然后完结了L×Tc+Ts时间的推迟。
下面剖析递归推迟线各抽头的输出样本在时间上的相位联系。设nC时间输入样本为x(n),那么抽头①~④处的输出样本应该是x(n- R),x(n2R),x(n-3R)和x(n-4R);nC+1时间推迟线输入的应该是现已推迟L×R+1时钟周期的样本,即x(n-L×R/C);抽头 ①~④处的输出样本应该是x(n-R- L×R/C),x(n-2R-L×R/C),x(n- 3R-L×R/C)和x(n-4R-L×R/C);第nC+c(0≤c≤C-1)时间推迟线输入的应该是现已推迟c(LR+1)时钟周期的样本,即 x(n-c×L×R/C)。那么抽头①~④处的输出样本应该是x(n-R-c×L×R/C),x(n-2R-c×L×R/C),x(n-3R- c×L×R/C)和x(n-4R-c×L×R/C)。
能够看出,同一个抽头在相邻2个时间输出的样本相差L×R/C个采样点,即1/C个码周期。这样递归推迟线把一个码周期内的信号样本分化到C个相位上,并在C个时钟周期内顺次串行输出,然后以多相的方法完结了信号推迟的功用。
递归推迟线仅需L/C个推迟单元即可完结L×Tc时延,它以作业时钟频率进步C倍为价值,将资源耗费量压缩到优化前的1/C.例如,当R=4时,C=16/R=4,即资源耗费仅为原先的25%.
3 递归折叠DMF
3.1 递归折叠DMF的结构
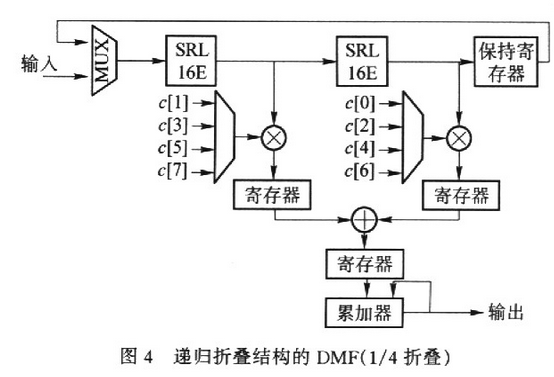
递归推迟线不只使抽头数削减到优化前的1/C,并且使抽头的样本输出速率增大C倍。与之对应,相关运算单元中乘法器和加法器的个数分别从L和L-1削减到 L/C和L/C-1,一起作业频率进步C倍。在C个作业时钟周期内,相关运算单元依据递归推迟线分化的信号相位,顺次核算出C个相位上的接纳信号与PN序列的部分相关值,并运用累加器完结部分相关值的兼并,然后得到完好的相关值。依据这个思路,作者提出递归折叠结构的DMF如图3所示。
该结构在递归推迟线的根底上,折叠运用相关运算单元,然后用一个L/C抽头的DMF完结L阶匹配滤波运算。
图3是一个1/2递归折叠滤波器,其参数为:L=8,R=8,C=2用1个4抽头DMF时分复用完结了8阶匹配滤波。时序剖析与上节类似。不失一般性,假定在偶时间输入新样本,那么在第0,2,4,6,…时间MUX将输入样本推入推迟线,在第1,3,5,7,…时间,MUX将坚持存放器中的样本反应到推迟线的进口。经过一段时间后,某个抽头在偶时间的样本与其鄙人一时间输出的样本在相位大将相差半个码相位周期,因而在相邻的时钟周期内,加载到各抽头的乘法系数也相差半个码相位周期。累加器兼并奇、偶时间的部分相关成果,然后得到完好的成果.
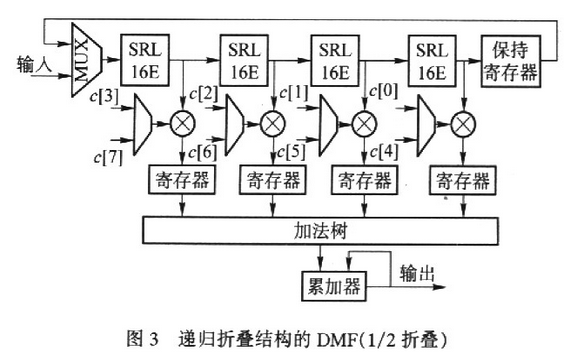
图4为l/4递归折叠滤波器的结构框图。(参数为L=8,R=4,C=4)。时序愈加杂乱,在相邻时钟周期内,抽头样本之间的相位差为1/4码周期.
3.2 递归折叠DMF与传统DMF资源耗费比照
为了评价优化作用,表1给出了选用根本结构和改善的折叠结构完结DMF所耗费的资源(L=256,M=4,R=4,采样率为fs).
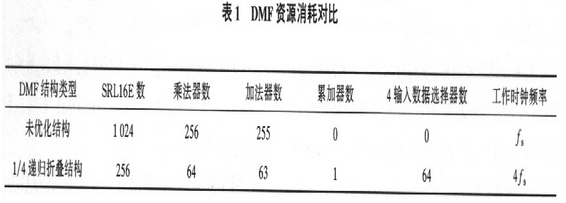
从表1能够看出,除了需求1个额定的累加器以及L/C个C输入数据挑选器之外,递归折叠DMF所耗费的资源(包含SRLL6E、乘法器和加法器)压缩到挨近未优化结构的l/C,可是其作业时钟频率也进步到本来的C倍,这也证明了硬件规划和作业频率能够交换。
可是作业时钟频率的进步是有约束的,更高的作业频率要求选用层次更高的FPGA或许需求在FPGA的细节完结中支付更高的价值,因而在规划递归折叠DMF 时,需求统筹考虑chip速率、过采样倍数和FPGA的作业时钟频率。例如。关于xilinx Virtex2系列FPGA,当chip速率不超越10 MHz/s时,能够选用1/4或许l/2递归折叠结构,此刻作业频率不超越160 MHz,时序要求适中。
4 结束语
运用作业时钟频率与规划规划可交换的原理,经过递归推迟线、折叠相关运算单元以及时分复用技能,使递归折叠结构大大下降了DMF的资源耗费。该结构现已使用于某类型中频数字化直接序列扩频接纳机中,使用成果表明优化作用显着。在采样率为40.96 MHz,作业时钟频率为163.84 MHz的条件下,经过4倍时分复用,其资源耗费约为优化前的l/3.