声纹辨认技能(说话人辨认技能)是一种生物认证技能,也是一项根据说话人波形反映其生理和行为特征的语音参数来自动辨认测验的说话人身份的技能。
在未来的日子中,说话人辨认将会以它本身共同的快捷性,实惠性和精准性受人注目,而且逐步遍及在生物认证技能领域。
说话人辨认首要录制声响样本和提取语音特征参数,再把它们保存在数据库中,最终把预备验证的声响和数据库中的语音特征相匹配,运用匹配成果类似度来取得说话人的身份。
1 常用语音库
现在,世界各国都很注重建造语音数据库。最具代表的是美国树立的LDC(Linguistic Data Consortium)和OGI(Oregon Graduate Inst itute),以及欧洲国家树立的ELRA(European Language Resollces Association)安排。这些安排都是长时刻研讨语音信号处理技能的。他们开宣布规划巨大的语音研讨资源。
第一个高质、大容量、高可信度的声响数据库是YOHO数据库。表1是YOHO说话人数据库。它是通过数字化的数据库,其输入特征参照了第三代安全终端单位(STU—III)的安全语音电话。规划了与文本有关的说话人承认体系,此体系是会提示用户说什么话,在YOHO中运用的是:“合成块”短语的语法。
这个数据库的环境是“工作环境”。另一方面,它还满意在噪声的环境和远间隔麦克风的条件下对语音做测验。而这些均满意了顾客的消费需求。
国内,浙江大学CCNT试验室提出和树立了面向移动通讯环境的说话人辨认语音库SRMC(speaker recognition in mobile communicatio n)。
日子中,假如要收集语音的话,就会常常运用核算机,麦克风,还有录音功用电话机,此外还要有相应的调制解调器。这些录音设备都很一般且常见。
咱们该怎样去点评和运用一个规范的语音数据库?咱们需求对点评下个界说。如点评的细节、练习和测验数据集的切割。在特定条件(如练习和测验选用不同的麦克风)下进行体系功能点评,需求有满足的录音数据。

2 声纹辨认体系
2.1 试验规划
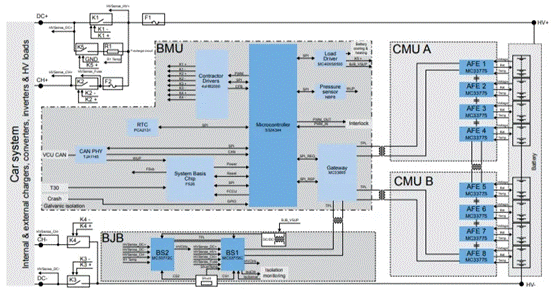
由于试验条件的约束,本课题的语音库是自己创立的,试验用来练习和测验的说话人录音,大部分是班级同学和同一试验室的同学。在这个试验中咱们运用的是一般话,咱们中每一个人说话速度和音量都处于正常状况。试验语音是在两天时刻内收集得到的。收集环境是试验室,一共有十个同学进行录音。男女比例是一比一。在本试验中,咱们尽量坚持试验室环境安静,假定咱们收集的声响都是纯音,没有噪音。试验中用到的录音软件是cool edit 2000,用的录音设备是一般的立体声麦克风和COMPAQ笔记本电脑,咱们把采样频率定为8000Hz,每一帧的帧长定为256个点,帧之间的间隔定为80点,用16比特量化办法进行量化。采样之后,得到了规范化的数字语音,这个试验中,用到的语料是阿拉伯数字。包括之间的数字,每个人的语音是1个阿拉伯数字,每个人每一天要有9次朗诵时机。咱们把取得的一切的数据样本存储在核算机的硬盘中,拿出第一天的语音来进行练习运用,把第二天的语音用来做测验。每一个数字录音看做一个单位来进行测验。本文的试验中运用阿拉伯数字1~9的语音单元构成的隐马尔可夫模型。建市了与文本有关的身份承认体系。如图1所示。
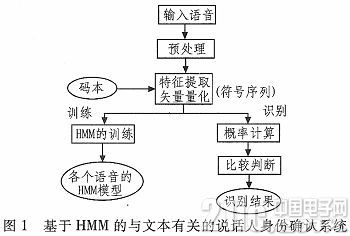
首要录制语音,收集语音,树立语音模板库,在试验室环境下,收集参与练习和辨认的说话人语音。别离树立两个数据库。第一天录音存储为Xi,第二天录音存储为Ri。别离存储在核算机的硬盘中的录音DIY材料文件夹下。语音库是用来存储说话人的语音。当需求辨认时能够用来辨认说话人身份。随后将语音送至预处理功用模块。
其次对数字化语音进行预处理,此模块的使命语音信号的数字化处理,把处理过的语音拿来端点检测。预处理进程包括去除语音信号的噪声、对信号进行预加剧、加窗、分帧等。通过加窗这一过程之后,得到了一帧帧的语音序列,然后进行预加剧处理。把信号做预加剧处理是为了把信号中的高频部分提取出来,这样做整个频谱就会变得平整起来,然后在悉数的频带中一向坚持这种平整,这个时分咱们能够用相同的信噪比求得频谱。这样都完结之后就能够频谱剖析了。预加剧滤波器的方式如:
H(z)=1-μz-1 (1)
式(1)中,μ的值在本试验中选取0.937 5。引进了预加剧参数μ,能够看出,有利于进步说话人的辨认率。表2中能够看到不同预加剧参数下的辨认率。
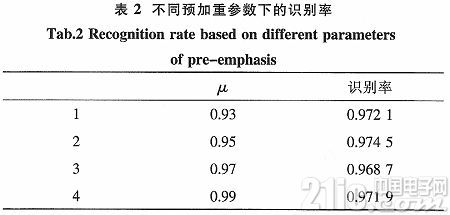
由表2可知,μ值改动,辨认率也在改动。μ=0.95时,辨认率最高。本试验选取的预加剧参数值在0.93~0.95之间。
接下来是对语音信号分帧加窗。由于语音信号不是平稳的信号,假定语音信号在10~30 ms之间是平稳的。为了得到短时的语音信号,对语音信号进行加窗核算。本课题首要选用的是汉明窗。汉明窗显现了一个好的窗口的长处。其在时域中波形细节不容易丢掉,且能避免走漏。汉明窗函数式:
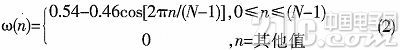
通过前面的一些处理之后,收集的语音信号就被切割成一帧帧的短时的加窗信号,把这些信号假定成随机平稳的信号,然后提取语音特征参数。
提取出来的语音参数,对其端点检测。此刻,先设置门限,根据短时能量和过零率的公式,求出来短时能量值和过零率值。然后用手艺办法在MATLAB上去除语音信号中的静音段和噪音语段来进行端点检测。
对体系的输入信号进行判别,精确地找到语音信号的起始点和停止点的方位。除掉语音中的凌乱语音段,只要这样才干收集到真实的语音数据,削减数据冗余和运算量,并削减处理时刻。如表3所示。在这里本课题用的是双门限法。将短时均匀能量和短时均匀过零率结合起来,进行端点检测,能够很好的检测语音是否开端和完毕。