跟着核算机技术和信息技术的迅速发展,语音口令辨认现已成为了人机交互的一个重要方法之一。语音口令辨认体系将依据人宣布的声响、音节或短语给出呼应,如经过语音口令操控一些执行机构、操控家用电器的运转或做出答复等。在数字信号处理芯片上现已完结了语音口令辨认体系或语音口令辨认体系的部分功用,但是跟着嵌入式微处理器处理才能的大幅度进步,核算量大的语音口令辨认算法现已能够经过嵌入式微处理器来完结,将语音口令辨认体系与嵌入式体系相结合,发挥语音辨认体系的潜力,使语音辨认体系能够广泛应用于便携式设备中。
选用隐马尔克夫模型(Hidden Markov MODEL,HMM) 描绘语音信号的非平稳性和部分平稳性,HMM中的状况与语音信号的某个平稳段相对应,平稳段之间以搬运概率相联系。因为HMM建模对语音信号长度和模型的混合度的要求都比较低,因此在现有的非特定人语音口令辨认体系中,多选用状况输出具有接连概率散布的接连隐马尔可夫模型(ConTInuous Density Hidden Markov MODEL,CDHMM)。
论文给出一种依据嵌入式体系的语音口令辨认体系的规划方案,硬件体系的中心芯片是嵌入式微处理器,语音口令辨认算法选用CDHMM。语音口令首要经过预处理,提取MFCC(Mel-Frequency Ceptral Coefficients)特征参数,然后树立此口令的CDHMM模型,把一切语音口令的模型放在模型库中,在辨认阶段,经过概率输出*分,取*分最大的一个作为辨认出的口令。将语音辨认体系与嵌入式体系相结合,能够使语音口令辨认体系广泛应用于便携式设备中。
1 硬件电路的规划和作业原理
依据嵌入式体系的语音口令辨认体系需求有接纳语音信号的输入芯片合作麦克风完结将模仿语音信号转化成数字信号的功用,然后由嵌入式微处理器对输入的语音口令信号进行处理。完结语音口令信号输入功用的芯片选用的是PHILIPS公司的低功耗芯片UDAl341TS,供电电源电压为3V,该音频处理芯片由模数/数模转化(ADC)、操控逻辑电路、可编程增益放大器(PGA)和数字自动增益操控器(DAGC)以及数字信号处理器等部分组成,能进行数字语音处理。
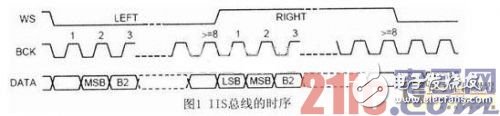
芯片UDAl341TS选用规范的内部集成电路声响总线IIS(Inter IC Sound Bus),该总线是由PHILIPS等公司一起提出的数字音频总线协议,专门用于音频设备之间的数据传输,现在许多音频芯片和微处理器都供给了对IIS总线的支撑。
IIS总线有三根信号线,分别是位时钟信号BCK(Bit Clock)、字挑选操控信号WS(Word Select)和串行数据信号Data,由主设备供给串行时钟信号和字挑选操控信号,IIS总线的时序如图1所示。
2 依据CDHMM的口令辨认的软件规划
2.1 口令辨认的软件体系框图
语音口令辨认的软件体系分别由特征参数提取、语音模型库和概率输出*分三大模块组成,如图3所示:1)语音口令特征参数的提取,输入不同的语音口令,首要要进行特征参数提取,选用Mel频率参数作为CDHMM的建模参数,Mel频率参数是依据人耳的听觉特性将语音信号的频谱转化为依据Mel频率的非线性频谱,然后转化到倒谱域上。2)在练习阶段,对不同的语音口令树立CDHMM模型。3)在口令辨认阶段,经过概率输出*分对待测语音口令做出辨认。
N(o,ujk,∑jk)为多维高斯概率密度函数,o是调查矢量序列,即从语音中提取的特征矢量参数(o1,o2,…,ot),t为调查矢量序列的时刻长度。ujk,∑jk分别为高斯散布的均值和方差参数,Cjk为高斯散布的权值,满意约束条件
是改善后的模型,再将作为初始值,从头估量。
依据“分段K-均匀法”的CDHMM参数估量详细进程为:
(1)设置模型参数初始值λ=(π,A,B)。
(2)依据此λ用Viterbi算法将输入的练习语音数据划分为最或许的状况序列,使用状况序列估量参数A。
关于概率密度函数由若干正态散布函数线性相加的CDHMM体系,每个状况θj(1≤j≤N)的概率密度函数bj(X)由K个正态散布函数线性相加而成,这样能够把每一状况语音帧分红K类,然后核算同一类中诸语音帧矢量X的均值矢量,方差矩阵∑jk和混合密度函数中各概率密度函数的权重系数 Cjk。
(4)由(2)和(3)估量的CDHMM参数作为初值,使用重估公式对CDHMM参数进行重估,得到参数。
(5)使用(4)所得的核算,并与p(O/λ)相比较。假如差值小于预订的阈值或迭代次数超越预订的次数,即阐明模型参数现已收敛,无需进行重估核算,可将作为模型参数输出。反之,若差值超出阈值或迭代未到预订的次数,则将核算结果作为新的初值,重复进行下一次迭代。
3 结束语
论文树立了一种依据嵌入式体系的语音口令辨认体系,而且对上升、下降等14条口令进行测验,每条语音先切除静音,预加剧,然后经过 Hamming窗分帧处理,帧长和帧移分别为20ms和10ms,然后对每一帧语音信号提取16MFCC+16AMFCC共32维参数作为特征矢量。该语音口令辨认体系达到了实时的要求,能够使语音口令辨认体系广泛应用于便携式设备中。