语音辨认已成为人与机器经过自然言语交互重要办法之一,本文将从语音辨认的原理以及语音辨认算法的视点出发为咱们介绍语音辨认的计划及具体规划进程。
言语作为人类的一种根本沟通办法,在数千年前史中得到继续传承。近年来,语音辨认技能的不断老练,已广泛运用于咱们的日子傍边。语音辨认技能是怎么让机器“听懂”人类言语?本文将为咱们从语音前端处理、根据核算学语音辨认和根据深度学习语音辨认等方面论述语音辨认的原理。
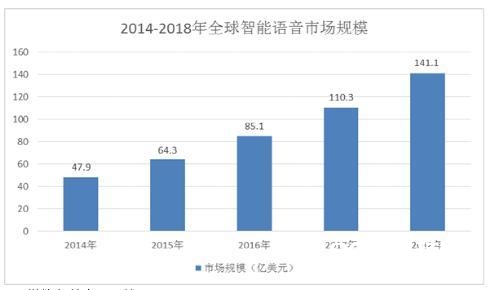
跟着核算机技能的飞速发展,人们对机器的依靠现已到达一个极高的程度。语音辨认技能使得人与机器经过自然言语交互成为或许。最常见的景象是经过语音操控房间灯火、空调温度和电视的相关操作等。而且,移动互联网、智能家居、轿车、医疗和教育等范畴的运用带动智能语音工业规划继续快速增长,
2018年全球智能语音商场规划将到达141.1亿美元。
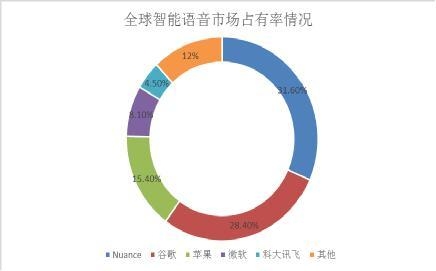
现在,在全球智能语音商场占比状况中,各巨子商场占有率由大到小依次为:Nuance、谷歌、苹果、微柔和科大讯飞等。
语音辨认的实质便是将语音序列转换为文本序列,其常用的体系结构如下:
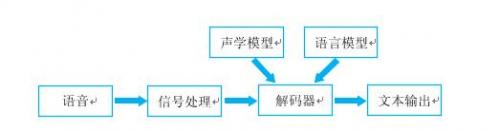
接下来对语音辨认相关技能进行介绍,为了便于全体了解,首要,介绍语音前端信号处理的相关技能,然后,解说语音辨认根本原理,并展开到声学模型和言语模型的叙说,最终,展现我司当时研制的离线语音辨认demo。
1.前端信号处理
前端的信号处理是对原始语音信号进行的相关处理,使得处理后的信号更能代表语音的实质特征,相关技能点如下表所述:
1)语音活动检测
语音活动检测(Voice Activity Detection,
VAD)用于检测出语音信号的开始方位,别离出语音段和非语音(静音或噪声)段。VAD算法大致分为三类:根据阈值的VAD、根据分类器的VAD和根据模型的VAD。
根据阈值的VAD是经过提取时域(短时能量、短时过零率等)或频域(MFCC、谱熵等)特征,经过合理的设置门限,到达差异语音和非语音的意图。
根据分类的VAD是将语音活动检测作为(语音和非语音)二分类,能够经过机器学习的办法练习分类器,到达语音活动检测的意图。
根据模型的VAD是构建一套完好的语音辨认模型用于差异语音段和非语音段,考虑到实时性的要求,并未得到实践的运用。
2)降噪
在日子环境中一般会存在例如空调、电扇等各种噪声,降噪算法意图在于下降环境中存在的噪声,进步信噪比,进一步提高辨认作用。
常用降噪算法包含自适应LMS和维纳滤波等。
3)回声消除
回声存在于双工形式时,麦克风收集到扬声器的信号,比方在设备播放音乐时,需求用语音操控该设备的场景。
回声消除一般运用自适应滤波器完成的,即规划一个参数可调的滤波器,经过自适应算法(LMS、NLMS等)调整滤波器参数,模仿回声产生的信道环境,然后估量回声信号进行消除。
4)混响消除
语音信号在室内经过屡次反射之后,被麦克风收集,得到的混响信号简单产生掩蔽效应,会导致辨认率急剧恶化,需求在前端处理。
混响消除办法首要包含:根据逆滤波办法、根据波束构成办法和根据深度学习办法等。
5)声源定位
麦克风阵列现已广泛运用于语音辨认范畴,声源定位是阵列信号处理的首要任务之一,运用麦克风阵列确认说话人方位,为辨认阶段的波束构成处理做准备。
声源定位常用算法包含:根据高分辨率谱估量算法(如MUSIC算法),根据声达时刻差(TDOA)算法,根据波束构成的最小方差无失真呼应(MVDR)算法等。
6)波束构成
波束构成是指将必定几许结构摆放的麦克风阵列的各个麦克风输出信号,经过处理(如加权、时延、求和等)构成空间指向性的办法,可用于声源定位和混响消除等。
波束构成首要分为:固定波束构成、自适应波束构成和后置滤波波束构成等。
2.语音辨认的根本原理
已知一段语音信号,处理成声学特征向量之后表明为![]() ,其间表明一帧数据的特征向量,将或许的文本序列表明为
,其间表明一帧数据的特征向量,将或许的文本序列表明为![]() ,其间表明一个词。语音辨认的根本起点便是求
,其间表明一个词。语音辨认的根本起点便是求![]() ,即求出使
,即求出使![]() 最大化的w文本序列。将
最大化的w文本序列。将![]() 经过贝叶斯公式表明为:
经过贝叶斯公式表明为:

其间,![]() 称之为声学模型,
称之为声学模型,![]() 称之为言语模型。大多数的研讨将声学模型和言语模型分隔处理,而且,不同厂家的语音辨认体系首要体现在声学模型的差异性上面。此外,根据大数据和深度学习的端到端(End-to-End)办法也在不断发展,它直接核算
称之为言语模型。大多数的研讨将声学模型和言语模型分隔处理,而且,不同厂家的语音辨认体系首要体现在声学模型的差异性上面。此外,根据大数据和深度学习的端到端(End-to-End)办法也在不断发展,它直接核算![]() ,行将声学模型和言语模型作为全体处理。本文首要对前者进行介绍。
,行将声学模型和言语模型作为全体处理。本文首要对前者进行介绍。
3.声学模型
声学模型是将语音信号的观测特征与语句的语音建模单元联络起来,即核算![]() 。咱们一般运用隐马尔科夫模型(Hidden Markov
。咱们一般运用隐马尔科夫模型(Hidden Markov
Model,HMM)处理语音与文本的不定长联络,比方下图的隐马尔科夫模型中,
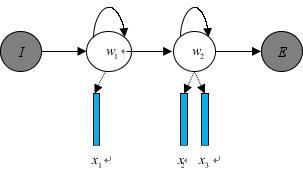
将声学模型表明为
其间,初始状况概率![]() 和状况搬运概率(
和状况搬运概率(![]() 、
、![]() )可用经过惯例核算的办法核算得出,发射概率(
)可用经过惯例核算的办法核算得出,发射概率(![]()
、![]() 、
、![]() )能够经过混合高斯模型GMM或深度神经网络DNN求解。
)能够经过混合高斯模型GMM或深度神经网络DNN求解。
传统的语音辨认体系遍及选用根据GMM-HMM的声学模型,示意图如下:

其间,![]() 表明状况搬运概率
表明状况搬运概率![]() ,语音特征表明
,语音特征表明![]() ,经过混合高斯模型GMM树立特征与状况之间的联络,然后得到发射概率
,经过混合高斯模型GMM树立特征与状况之间的联络,然后得到发射概率![]() ,而且,不同的状况
,而且,不同的状况![]() 对应的混合高斯模型参数不同。
对应的混合高斯模型参数不同。
根据GMM-HMM的语音辨认只能学习到语音的浅层特征,不能获取到数据特征间的高阶相关性,DNN-HMM运用DNN较强的学习才能,能够提高辨认功能,其声学模型示意图如下:

GMM-HMM和DNN-HMM的差异在于用DNN替换GMM来求解发射概率![]()
,GMM-
HMM模型优势在于核算量较小且作用不俗。DNN-HMM模型提高了辨认率,但关于硬件的核算才能要求较高。因而,模型的挑选能够结合实践的运用调整。
4.言语模型
言语模型与文本处理相关,比方咱们运用的智能输入法,当咱们输入“nihao”,输入法候选词会呈现“你好”而不是“尼毫”,候选词的摆放参照言语模型得分的凹凸次序。
语音辨认中的言语模型也用于处理文字序列,它是结合声学模型的输出,给出概率最大的文字序列作为语音辨认成果。因为言语模型是表明某一文字序列产生的概率,一般选用链式法则表明,如w是由![]() 组成,则
组成,则![]() 可由条件概率相关公式表明为:
可由条件概率相关公式表明为:
![]()
因为条件太长,使得概率的估量变得困难,常见的做法是以为每个词的概率散布只依靠于前几个呈现的词语,这样的言语模型成为n-gram模型。在n-gram模型中,每个词的概率散布只依靠于前面n-1个词。例如在trigram(n取值为3)模型,可将上式化简:
5.语音辨认作用展现
根据PC的语音辨认展现demo如下视频所示:
此处刺进视频zal_asr_demo_video.mp4
视频包含运用“小致同学”唤醒设备,设备唤醒之后有12秒时刻进行语音辨认操控,闲暇时刻超过了12秒将再次休眠。
咱们的语音辨认算法现已部分移植到了根据AWorks的cortex-m7系列M1052-M16F12 8AWI
-T渠道。语音辨认的声学模型和言语模型是我司练习的用于测验智能家居操控的相关模型demo,在支撑65个常用命令词的离线辨认测验中(数量越大辨认所需时刻越长),运用读取本地音频文件的办法进行语音辨认“翻开空调”所需时刻0.46s左右。下面是在M1052-M16F128AWI-
T的实测作用:

最终附上M1052-M16F128AWI-T产品图片:

6.关于算法库获取
现在语音辨认体系处于研制阶段,广大客户可将本身需求反馈给广州建功科技股份有限公司与建功科技·致远电子相关商场人员,咱们会以最快速度研制客户需求的产品。