卷积码因为其编码器简略、编码增益高以及具有很强的纠正随机过错的才干,在通讯体系中得到了广泛的运用。根据最大似然原则的维特比算法(VA)是在加性高斯白噪声(AWGN)信道下功用最佳的卷积码译码算法,也是常用的一种算法。
一般来说,完结软判定维特比译码可以有三种计划供挑选:专用集成电路(ASIC)芯片、可编程逻辑阵列(FPGA)芯片以及数字信号处理器(DSP)芯片。参考文献[3]对这三种计划的好坏做了具体的比较。运用DSP芯片完结译码是最为灵敏的一种计划,但速度也是最慢的,因为整个译码进程都是由软件来完结的。
在近年来鼓起的软件无线电技能中,要求选用可编程才干强的的器材(DSP、CPU等)替代专用的数字电路。对信道编解码而言,这样做的长处在于只需求在程序上加以少数改动,就可以习惯不同的编码速率以及各种通讯体系所要求的不同的编解码办法。但是速度的瓶颈约束了DSP译码在实时体系中的运用,因而进步DSP的译码速度关于软件无线电有着重要的含义。本文的意图便是经过对译码程序结构优化,来进步DSP芯片履行VA算法的速度。
1 维特比译码器
首要,需求界说两个将在本文中用到的术语:
输入帧–每次输入译码器的比特;
输出帧–对应一个输入帧,译码器输出的比特。
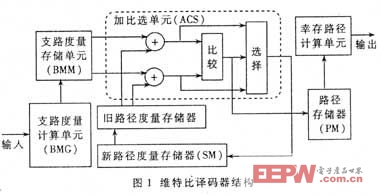
图1所示是卷积码译码器(VA算法)的一种典型结构。
以(2,1,7)卷积码为例(输入帧含2比特,输出帧为1比特),来阐明译码器的三个首要部分。
1.1支路衡量核算单元(BMG)
核算当时输入帧对应的128条支路的途径衡量值,并将其存人支路衡量存储单元(BMM)。
1.2加比选单元(ACS)
将支路衡量值与相连的前面的途径衡量值相加得到延伸后的新途径的衡量值;比较连接在同一个状况上的两条新途径的衡量值;挑选其间衡量值较小的那条途径(幸存途径),并将它的衡量值存储到新途径衡量存储器(SM)中,幸存途径值(对应编码状况的输入比特)存储到途径存储器(PM)中。
1.3幸存途径核算单元
找到64条幸存途径中衡量值最小的一个(最大似然途径),经过回溯操作(Traceback)在PM中找出该途径对应的一切输入比特,顺次输出即为译码成果。
每输出一帧,都对应着一次支路单元核算和64次ACS操作。ACS操作在总的运算时间里占了很大的份额。程序优化的首要作业便是设法削减每个ACS操作所需求的时钟周期数。
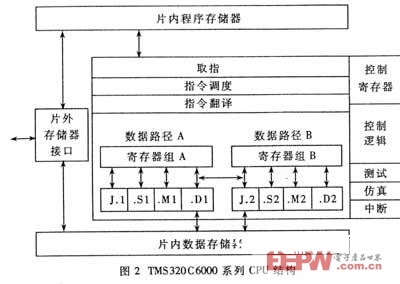
2 TMS320C6000 DSP芯片的特色
TMS320C6000系列DSP是根据TMS320C6000渠道的32位浮点DSP处理器。它包括两个子系列:用于定点核算的TMS320C62x系列和用于浮点核算的TMS320C67x系列TMS320C6000系列CPU结构如图2所示。时钟频率最高可到达250MHz。该系列DSP包括两个通用的寄存器组A和B,每组有16个32位的寄存器。芯片内含8个运算功用单元:两个乘法器(.M1和.M2);六个算术逻辑单元(.L1.L2.S1.S2.D1.D2)。一切单元都能独立并行操作。以TM320C6701为例,它的作业频率最高为167MHz,最快速度可达8×167=1336MIPS。
实践上,要完结这个速度存在许多瓶颈,首要有下面几种约束:
(1)功用模块的约束 8个功用模块可以履行的指令不尽相同。在实践程序中,因为程序流程的约束,指令的方位不能随意互换,因而不行能在每一个时钟周期都让8个模块一起作业。程序优化的首要手法便是要进步指令的并行程度,即均匀每一周期内一起履行的指令数。
(2)穿插途径(Cross Path)的约束 每一个功用模块都只能对其所属的寄存器组中的寄存器进行直接操作。例如.L1只能将成果直接写入寄存器组A。假如要对另一个寄存器组履行读或写操作,需求用到穿插途径,而整个CPU中只要两条穿插途径。也便是说,一个周期内至多能一起包容两个相反方向的穿插读写。
(3)多周期指令的约束 LD指令的功用是将数据从存储器读到寄存器中,由.D模块履行。但履行LD指令后有必要等候4个周期才干得到需求的数据。相似这样的需求多个周期才干完结的指令(例如跳转指令B)都成为进步指令并行处理程度的妨碍。
(4)对长数据操作的约束 C6000指令集只能以8比特、16比特、32比特或许40比特为单位对数据进行操作。