


作者:Cathal Murphy/Yao Fu
为了满意不断攀升的数据处理需求,未来的体系需在运算才干上进行改进。传统处理计划(如x86处理器)再也无法以高功率、低本钱的方法供给所需运算带宽,因而体系规划人员须寻觅新的运算渠道。
越来越多体系规划人员将现场可编程门阵列(FPGA)和绘图处理器(GPU)视为可以满意未来需求的运算渠道。本文将剖析未来GPU、FPGA和体系单芯片(SoC)组件,能为新年代供给哪些必要的运算功率和弹性。
云端数据中心和自动驾驭轿车等未来体系,需在运算才干上进行改进,以支撑不断添加的作业负载,以及不断演进的底层算法[1]。例如,大数据剖析、机器学习、视觉处理、基因体学以及先进驾驭辅佐体系(ADAS)的传感器交融作业负载都超出现有体系(如x86体系)所能供给的功率与本钱效益。
体系架构师正在寻觅能满意需求的新运算渠道,且该渠道需求有满意的弹性,以便整合至现有架构中,并支撑各种作业负载及不断演进的算法。此外,许多这类体系还须供给确认性低推迟效能,以支撑如自动驾驭轿车在实时体系上所需的快速反应时刻。
因GPU在机器学习练习的高效能运算(HPC)范畴取得的作用,因而GPU厂商十分积极地将GPU定位为新年代运算渠道的最佳挑选。在此进程中,GPU厂商已修正其架构来满意机器学习推论的作业负载。
但是,GPU厂商一向忽视GPU根本架构的约束性。而这些约束会严峻影响GPU以高功率、低本钱方法供给必要的体系级运算效能之才干,例如,在云端数据中心体系中,作业负载需求在一天内会发生很大的改动,且这些作业负载的底层算法也正快速地演进。GPU架构的约束性会阻止许多如今与未来的作业负载映像到GPU,导致硬件搁置或低功率。本文稍后提及的章节,将针对这些约束进行更具体的介绍。
相反地,FPGA与SoC具有许多重要特质,将成为处理未来体系需求的最佳挑选。这些共同特质包含:
・针对一切数据类型供给极高的运算才干和功率
・针对多种作业负载供给极高弹性,并将运算和功率之优势最大化
・具有I/O弹性,能方便地整合到体系中并抵达更高功率
・具有大容量芯片内建高速缓存,以供给高功率及最低推迟率
看清布景/运用/优劣势 绘图处理器大拆解
GPU的来源要追溯到PC年代,辉达(NVIDIA)宣称在1999年推出世界首款GPU,但其实许多显卡推出时刻更早[2]。GPU是一款全新规划的产品,用于分管及加快图画处理使命,例如从CPU进行像素数组的遮盖和转化处理,使其架构适用于高并行传输率处理[3]。本质上,GPU的首要作用为替视觉显现器(VDU)供给高质量印象。
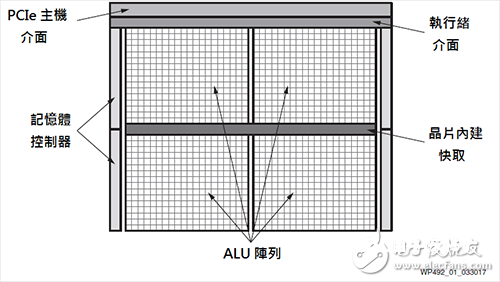
图1 GPU模块图
多年来,如大规划矩阵运算的医疗印象运用,此类少数非印象但需大规划平行及受内存约束的相关作业负载,已从GPU而非CPU上完成。GPU厂商意识到有机会将GPU商场拓宽到非印象运用,因而如OpenCL这类的GPU非印象编程言语应运而生,而这些编程言语将GPU转化成通用GPU(GPGPU)。
・机器学习
最近,可以杰出映像到GPU运转计划的作业负载之一,便是机器学习练习。透过充分运用GPU,能显着缩短深度神经网络的练习时刻。
GPU厂商企图运用机器学习练习的成功,来触动其在机器学习推论上的开展(布置经过练习的神经网络)。跟着机器学习算法与所需数据精度的演进,GPU厂商一向在调整其架构以坚持自身位置优势。其间一个比如便是,NVIDIA在其Tesla P4产品中支撑INT8,但是如今许多用户探究着更低的精度,如二进制和三进位[4]。若要运用机器学习与其它范畴的开展,GPU用户有必要等候新硬件推出之后再购买。
GPU厂商想运用机器学习作为根底,使自身成为此新运算年代的首选运算渠道。但若要清楚了解GPU是否合适未来体系,仍需做更全面的体系级剖析、考虑GPU架构的约束性,以及体系要怎么随时刻开展演进。
・GPU架构约束性
本章节将深入研讨典型的GPU架构,来揭穿其约束性及怎么将其运用于各种算法和作业负载。
・SIMT ALU数组
图1展现典型的GPU模块图。通用GPU运算功用的中心是大型算术逻辑单元(ALU)或运算中心。这些ALU一般被认为是单指令多线程(SIMT),相似于单指令大都据(SIMD)。
根本原理是将作业负载分红数千个平行的线程(Thread),ALU需求许多的GPU线程来防备搁置。在对线程进行调度后,不同的ALU组便能平行履行相同的(单一)指令。GPU厂商透过运用SIMT,能供给相较于CPU占位面积更小和成效更高的计划,因为许多中心资源能与同组的其他中心同享。
但是,显着特定作业负载(或部分作业负载)能被有用地映射到这大规划平行的架构中[5]。倘若构成作业负载的线程不具满意的共通性或平行性,例如接连或适度平行的作业负载,ALU则会出现搁置状况,导致运算功率下降。此外,构成作业负载的线程预期要将ALU运用率最大化,然后发生推迟。即便在NVIDIA的Volta架构中运用独立线程调度的功用,其底层架构仍坚持SIMT,好像需求大规划平行作业负载。
关于接连、适度平行或稀少的作业负载,GPU供给的运算与功率低于CPU所能供给的[6]。其间一个量化实例为在GPU上履行稀少矩阵运算;倘若非零元素数量较少,并从效能和功率的视点来看,GPU低于或等同于CPU[7][8]。风趣的是,许多研讨人员正在研讨稀少卷积式类神经网络,来运用卷积式类神经网络中的大规划冗余[9],这趋势显着代表GPU在机器学习推论中所遇到的应战。稀少矩阵运算也是大数据剖析中的关键环节[10]。
大都包含许多平行运算使命的作业负载亦包含一些接连或适度平行元素,这意味着需求GPU-CPU混合体系来满意体系效能要求[11]。显着,关于高阶CPU的需求会影响渠道的功率与本钱效益,并且CPU与GPU之间的通讯需求为体系添加潜在瓶颈。SIMT/GPU架构的另一个约束性是ALU的功用取决于其固定指令集和所支撑的数据类型。
・离散数据类型精度援助
体系规划人员正在探究简化数据类型精度,以此抵达运算效能的跳跃式进步,并且不会显着下降精度[12][13][14]。机器学习推论导致精度下降,首先是FP16,接着是INT16和INT8。研讨人员正在探究进一步下降精度,乃至降到二进制[4][15]。
GPU ALU一般原生支撑单精度浮点类型(FP32),而有些状况下支撑双精度浮点(FP64)。FP32是印象作业负载的首选精度,而FP64一般用于一些HPC运用。但是低于FP32的精度一般无法在GPU中取得有用支撑,因而相较于下降所需的内存带宽,选用规范GPU上下降精度较有优势。
GPU一般供给一些二进制运算功用,但一般只能每ALU进行32位运算,且32二进制运算有很大的杂乱度和面积需求。在二值化神经网络中,算法需求XNOR运算,紧接着进行族群(PopulaTIon)计算。因为NVIDIA GPU仅能每四个周期进行一次族群计算运算,因而对二进制运算有极大的影响[18]。
如图2所示,为了跟上机器学习推论空间的开展脚步,GPU厂商继续进行必要的芯片修正,以支撑如FP16和INT8的有限下降精度数据类型。其间一个实例为,Tesla P4和P40运算卡上的NVIDIA GPU支撑INT8,为每ALU/Cuda中心供给4个INT8运算。
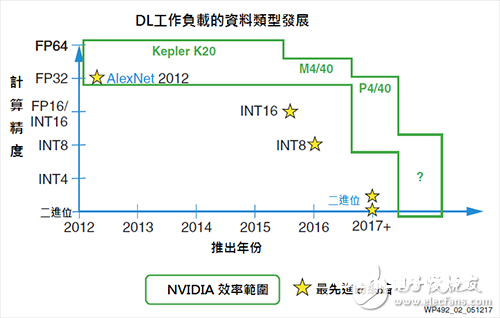
图2 NVIDIA降精度援助
但是,依NVIDIA在Tesla P40上的GoogLeNet v1 Inference推出的机器学习推论基准显现,INT8计划与FP32计划比较功率仅进步3倍,此成果显现在GPU架构中强行下降精度,并取得高功率存在较大难度[16]。
跟着机器学习和其他作业负载转向更低精度和客制化精度,GPU厂商需求在商场上推出更多新产品,且厂商的现有用户亦需晋级渠道,才干获益于此范畴的开展。
内存多阶级把关 软件界说数据抵达途径艰苦
与CPU相似,GPU中的数据流也由软件界说,并取决于GPU严厉且杂乱的内存阶级[17],而典型的GPU内存阶级如图3所示。每个线程在缓存器档案中都有自己的内存空间,用以贮存线程的部分变量。同一个模块内的少数线程可透过同享内存来通讯;且一切线程皆能透过大局或芯片外内存通讯[18]。
如图3所示,因为数据需从缓存器档案横跨整个内存阶级到大局内存,形成与内存存取相关的功耗和推迟别离添加100倍和80倍以上[15][17][19]。此外,内存抵触是必定的,一起亦会添加推迟导致ALU搁置,然后下降运算才干和功率。

图3 典型的GPU内存阶级
因而,若想发挥GPU的运算和功率潜能,作业负载的数据流有必要精确映像到GPU内存阶级。事实上,很少作业负载具有满意的数据部分性来有用地映像到GPU上。对大都的作业负载而言,当在GPU上运转时,实践的运算才干和功率会大打折扣,处理计划的推迟也会添加[19][20]。
机器学习推论作为量化实例,能清楚展现出数据流的约束性。GPU有必要进行如128笔的批处理(Batch),以取得高功率但推迟更长的处理计划。终究,批处理使机器学习处理部分化,但须支付添加推迟的价值[21],而此成果能清楚的在GoogLeNet v1 Inference的NVIDIA P40基准查验中看到。关于GoogLeNet v1来说,其网络因P40内存带宽而遭到运算捆绑,因而削减与批处理有关的内存带宽并不会发生很大的帮忙。但是,P40显着需求透过128的批处理以抵达50%的GPU理论效能,但一起也添加体系的推迟[16]。
某些状况下,材料可透过CPU进行前置处理,以便作业负载能更有用的映像到GPU SIMT架构和内存阶级,但其价值则是发生更多CPU运算和功耗,因而抵消了GPU的优势[7]。
・有限I/O选项
如本文一开端的阶段所述,GPU本来的人物是作为协同处理器。为了促进与主机交流,GPU以往只要一个PCIe接口与几个如GDDR5的芯片外接DRAM接口。近期的产品中,有些GPU选用硬件接口来进行GPU到GPU的通讯。而CPU仍须衔接网络来分配使命予GPU,此不只添加体系功耗,还会因PCIe有限的带宽而带来瓶颈。例如,支撑PCIe 3.0&TImes;16的NVIDIA Tesla 40,只能具有16GB/s的带宽。
GPU厂商已开端建构小型SoC,例如NVIDIA Tegra X1,其能整合GPU运算、Arm处理器、一些通用轿车周边和如HDMI、MIPI、SIP、CAN的根底以太网络等。因为上述组件具有少数运算才干,因而有必要倚赖额定的别离式GPU来抵达必要的运算才干。但是,别离的GPU接口有很大约束性,例如Tegra X1仅支撑PCIe 2.0&TImes;4,导致严峻瓶颈,且额定SoC的功耗会更进一步下降渠道的功率。
・芯片内建内存资源
除了推迟、功率和传输率方面的晦气影响,芯片外内存的带宽要显着低于部分/芯片内建内存。因而,若作业负载需求依托芯片外内存,不只芯片外内存的带宽会成为瓶颈,且运算资源也会被搁置,然后下降GPU能供给的运算功用和功率。
因而,更有利的做法是选用大型、低推迟且高带宽的芯片内建内存,再以机器学习推论为例,GoogLeNet共需27.2MB的内存空间;假定履行FP32,是没有GPU能供给的,这意味着需求芯片外内存[22]。在许多状况下,则需选用高本钱的高带宽内存(HBM)和批处理,以防止中心处于搁置状况。若挑选具更大型的芯片内建内存组件,便能防止HBM本钱及额定的推迟和功耗问题。
・功耗规模
GPU厂商在规划板卡和GPU时一般要适用于250W的功耗上限,并依托有用热办理来调理温度。针对机器学习推论商场,NVIDIA已开发如Tesla M4和P4等满意75W功耗规模的组件。尽管75W已远超出所答应的体系级功耗和热规模,但GPU的肯定功耗依然是阻止GPU被广泛选用的要素之一。
功用安全性
GPU源于消费图画处理和高效能运算范畴,其不存在功用安全性的需求。但跟着GPU厂商瞄准ADAS商场,功用安全性就成了必要条件,因而为用于ADAS体系中,组件需求从头规划,以保证抵达所需的功用安全性认证等级。这对GPU厂商来说不只是一个长时刻且触及各方面的学习进程,还需求新东西和设备。
完成多元运用推手 FPGA/SoC优点多
・原始运算才干
与GPU拥护者的说法不同,单一个FPGA组件能供给的原始运算才干,能抵达38.3 INT8 TOP/s的效能。NVIDIA Tesla P40加快卡以根底频率运转时供给相似的40 INT8 TOP/s原始运算才干,但功耗是FPGA计划的2倍多[26]。
此外,FPGA组件的弹功用支撑各种数据类型的精度[27]。例如,针对二值化神经网络,FPGA可供给500TOPs/s的超高二进制运算才干(假定2.5LUT/运算的状况),相当于GPU典型效能的25倍。有些精度较适用于DSP资源,有些则能在可编程逻辑中运转,还有些合适将两者结合起来运用,而这些弹性保证组件的运算和功率能跟着精度下降,且下降到二进制。机器学习范畴的许多研讨都从运算、精度和功率视点来进行最佳精度的研讨[28~32]。不管最佳点在哪,关于给予的作业负载都能随之调整。
多年来,许多FPGA用户针对多种作业负载,运用脉动数组处理规划抵达最佳效能,其间包含机器学习推论[33][34]。
风趣的是,NVIDIA为了如今的深度学习作业负载来进步可用的运算才干和功率,在Volta架构中以Tensor Core方式强化相似的功用。但是,深度学习作业负载会跟着时刻演进,因而Tensor Core架构亦需求改动,且GPU用户也需等候购买新的GPU硬件。
・功率和功耗
从体系层级来看,运算渠道有必要在指定的功率和热规模内供给最大运算才干。为满意此需求,运算渠道有必要:
1. 处于答应的功率规模内
2. 在功率预算内将运算才干最大化
All Programmable系列组件,运用户能挑选与功率和热规模最相符的组件。如表1所示,从原始运算视点来看,该组件能针对固定精度数据类型供给高效通用运算渠道,首要是因为FPGA架构中的直接开支较低。例如,GPU需求更多杂乱性环绕其运算资源,以促进软件可编程功用。关于当今的深度学习作业负载的张量(Tensor)运算,NVIDIA的Tesla V100凭仗已强化的Tensor Core抵达能与FPGA和SoC对抗的功率。但是,深度学习作业负载正以十分快的速度演进,因而无法确认NVIDIA Tensor Core的高功率能在深度学习作业负载保持多久。
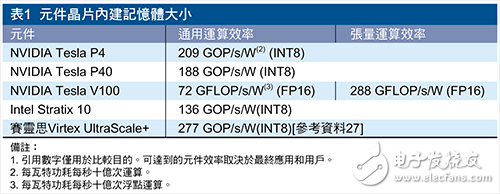
由此看来,关于其他通用作业负载,NVIDIA V100亦面对功率的应战。鉴于本文之前介绍的约束性,关于实践的作业负载与体系,GPU很难抵达如表1中所供给的数字。
・All Programmable组件弹性
赛灵思透过将硬件可编程资源(如逻辑、途径和I/O)与具弹性且独立的整合中心区块(如DSP切割和UltraRAM)结合,并将悉数构建在抢先制程技术上,如台积电(TSMC)的16nm FinFET制程,然后抵达这种平衡。
硬件可编程性和弹性,意味着底层硬件经过装备可满意指定作业负载的需求。随后,数据途径乃至能在运转时,透过部分可重组功用简易地进行从头装备[35]。图4企图举例All Programmable组件供给的部分弹性。中心(或用户规划元素)可直接衔接可编程I/O、恣意其它中心、LUTRAM、Block RAM和UltraRAM、及外部内存等。
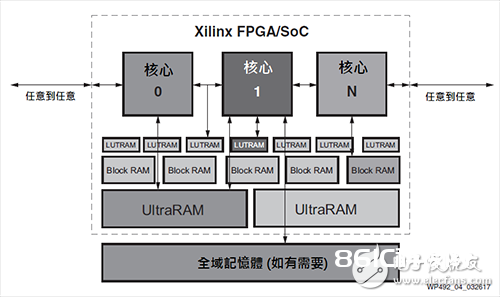
图4 All Programmable数据途径和各种方式IO
硬件可编程性组件意味着它们不存在这类的特定约束,如SIMT或固定数据途径等。不管是大规划平行、适度平行、管线接连或混合方式,都能取得赛灵思组件的运算才干和功率。此外,若底层算法改动,例如机器学习网络的开展,则渠道也能随之调整。
许多体系和作业负载中都能看到FPGA与SoC组件发挥弹性优势,而机器学习推论便是其间之一。其间机器学习推论的趋势便是向稀少网络跨进,且FPGA与SoC组件用户已在运用此趋势,而NVIDIA自身便是其间一位用户。在近期与NVIDIA联合编写关于语音辨认的一篇文章中说到,经过运用FPGA,相较于CPU能进步43倍速度和40倍功率,而NVIDIA GPU仅能进步3倍速度和11.5倍功率[36]。可编程数据途径还削减了FPGA的批处理需求,批处理是体系推迟比照实时效能的重要决定要素。
从大数据视点来看,FPGA在处理包含在如可变长度字符串的杂乱数据状况下,SQL作业负载时具高功率且快速。基因体剖析则是一个实例,有人已运用GPU来加快基因体剖析,其相较于Intel Xeon CPU计划能进步6至10倍的速度[40]。不过,FPGA进步速度的作用更高,相较于平等CPU可进步约80倍的速度[41]。
最终,关于正在尽力研制自动驾驭功用的轿车体系规划人员来说,FPGA与SoC组件的灵敏能为他们供给可扩展的渠道,以满意美国轿车工程学会(SAE)各种彻底自动驾驭路途的规范。
・各种方式I/O弹性
除了组件运算资源的弹性,FPGA的各种方式之I/O弹功用保证组件无缝整合至既有的根底架构,例如在不运用主机CPU的状况下,直接衔接到网络或贮存设备[42]。此外,I/O弹性还答应渠道针对根底架构的改动或更新进行调整。
・芯片内建内存
如表2所示,这种巨大的芯片内建内存快取,代表着大都的作业负载内存需求是透过芯片内建内存供给,来下降外部内存存取所带来的内存瓶颈,以及如HBM2这类高带宽内存的功耗和本钱问题。例如,针对大都深度学习网络技术(例如GoogLeNet)的系数/特性图都可存在芯片内建内存中,以进步运算功率和下降本钱。芯片内建存取能消除芯片外内存存取所引起的巨大推迟问题,将体系的效能最大化。
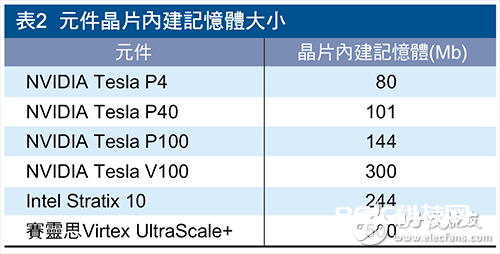
・封装内HBM
针对需求高带宽内存的状况下,FPGA组件供给HBM,以便作业负载有用的映像到组件和可用内存带宽,将效能和运算功率最大化。
在新的运算年代,体系规划人员面对许多困难挑选。FPGA和SoC为体系规划人员供给最低危险,来帮忙其满意未来体系的中心需求与应战,一起供给满意的弹性以保证渠道在未来不会掉队,可谓统筹两层需求。在深度学习范畴,UltraScale架构中DSP架构固有的平行性透过INT8向量点积的扩展性效能,为神经网络强化卷积和矩阵乘法传输率,使得深度学习推论抵达更低推迟。快速DSP数组、最高功率的Block RAM内存阶级及UltraRAM内存数组的组合可抵达最佳功率效益。






