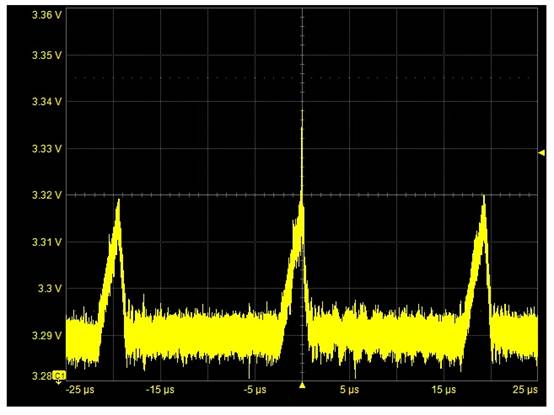
1. 用Altera_Cpld作了一个186(主CPU)操控sdram的操控接口, 发现问题:要使得sdram读写正确, 有必要把186(主CPU)的clk送给sdram, 而不能把clk经cpld的延时送给sdram. 两者相差仅仅4ns. 而时序经过逻辑剖析仪测验没有问题. 此程序在xilinx器材上没有问题. 这是怎样回事?
答:主张将一切操控和时钟信号都从PLD输出, 因为SDRAM对时钟偏移(clock skew)很灵敏, 而Altera的器材PLL答应对时钟频率和相位都进行彻底操控. 因而, 关于一切运用SDRAM的规划, Altera的器材PLL有必要生成SDRAM时钟信号.
要运用SDRAM作为数据或程序存储地址来完结规划, 是选用MegaWizard仍是Plug-In Manager来将一个PLL在选用Quartus II软件的规划中的顶层示例?能够挑选创立一个新的megafuntion变量, 然后在Plug-In manager中创立ALTCLKLOCK(I/P菜单)变量. 能够将PLL设置成多个, 或是将输入区分开来, 以习气规划需求. 一旦软件生成PLL, 将其在规划中示例, 并运用PLL的“Clock”输出以驱动CPU时钟输入和输出IP引脚.
2. 在max7000系列中, 只答应有两个输出使能信号, 可在规划中却存在三个, 每次编译时呈现“device need too many [3/2] output enable signal”. 假设不替换器材(运用的是max7064lc68). 怎样处理这个问题?
答:Each of these unique output enables may control a large number of tri-stated signals. For example, you may have 16 bidirectional I/O pins. Each of these pins require an output enable signal. If you group the signals into a 16-bit bus, you can use one output enable to control all of the signals instead of an individual output enable for each signal. (参阅译文:这两个共同的输出使能中每个都或许操控很多三相信号. 例如, 或许有16个双向I/O引脚. 每个引脚需求一个输出使能信号. 假设将这些信号一同分组到一个16位总线, 就能够运用一个输出使能操控一切信号, 而不用每个信号一个输出使能. )
3. 关于vhdl的问题:process(a, b, c) begin… end process; 假设a、b、c一起改动, 该进程是否一起履行三次?
答:PROCESS STATEMENTS 中的履行跟逻辑有联系, 假设是同步逻辑, 则在每次时钟的触发沿依据A, B, C的条件来履行一次;假设是异步逻辑, 则依据判别A、B、C的条件来履行. 一般咱们都引荐运用同步逻辑规划
4. 在规划开始, 因为没有将时钟信号界说在大局时钟引脚上, 导致MAXPLUS II 在时刻剖析时提示过错:(时钟偏斜加上信号推迟时刻超越输入信号树立时刻). 大局时钟引脚的时钟信号到各个触发器的延时最小, 有没有或许经过编译软件设置, 将一般I/O脚上的时钟信号也经过芯片内部的快速通道以最小的推迟送到每个触发器时钟引脚?
答:you can register that signal and assign it as the global signal, by the step flow: assign->logic option->Individual logic options->Global signal. But you’d better input the clock signal through the dedicated input pin. (参阅译文:能够存放这个信号, 并将它指定为大局信号, 进程如下:指定—>逻辑选项—>单个逻辑选项—>大局信号. 但是, 最好经过专用输入引脚输入时钟信号. )
5. 用MaxplusII 软件规划完后, 用Delay Matrix查看推迟时刻. 因为内部触发器的时钟信号用了一个输出引脚的信号, 比如将一引脚ClkOut界说为Buffer, Clkout是一时钟信号, 然后反应到内部逻辑, 内部逻辑用此信号作为时钟信号, 但用Delay Matrix, 却查看不到一些信号相应于ClkOut的推迟, 因为ClkOut是一Output引脚, 在Delay Matrix source 一栏中没有ClkOut信号, 怎样处理这个问题?
答:这种做法在逻辑规划中称为GATE CLOCK, 所谓GATE CLOCK便是将规划中的组合逻辑效果拿来做时钟信号, 这是一种异步逻辑规划.
现在都引荐运用同步逻辑规划办法. 能够将该信号(CLKOUT)拿来作使能信号, 即ENABLE信号, 而时钟信号仍是选用本来的一致时钟, 使规划用尽量少的同步时钟, 这样一来就仍是用DELAY MATRIX来剖析原有的时钟.
6. 我是一个epld的初学者, 现在看到xilinx的Virtex-II中嵌入很多的资源如:powerpc、ram等, 终究怎样在fpga中运用这些资源?
答:Xilinx Virtex-II中嵌入的资源非常丰富, 如BlockRAM、Digital Clock Manager、On-chip termination等等. ISE 4.2i软件彻底支撑这些资源. 能够举出单元库中相应根本数据的实例. Xilinx Core Generator中也还支撑BlockRAM等特性. 至于PowerPC和MGT规划, 能够运用Virtex-II Pro开发者套件.
7. 在规划中, 往往需求对某个信号做必定(恣意长)的延时, 有没有好的办法来完结?而不是选用相似移位存放器的办法来延时.
答:运用移位存放器在FPGA中对信号进行延时是一种好办法. Xilinx Virtex架构中每个对照表(LUT)都能够设置成为具有可编程深度(最多为16)的移位存放器. 这就供给了一种高效的途径来在FPGA中完结移位存放器. 无须运用触发器就能够完结一个16位存放器. 作为一个好的规划习气, 任何状况下都不要经过闸推迟来完结推迟逻辑.
8. ISE中的PAD TO PAD CONSTRAINT 是否是包含输入输出的pad时延之和再加上输入输出之间的组合逻辑的时延?仍是仅仅输入输出之间的组合逻辑的时延?
答:Xilinx PAD-to-PAD contraint确实涉及到输入输出PAD时延. 这从布局后时序陈述中能够看出.
9. 因为现在的规划根本上都是同步规划, 那么PAD TO PAD CONSTRAINT 在什么状况下运用?
答:尽管如今大都规划都是彻底同步, 但仍有一些状况需求从一个输入引脚到另一个输出引脚的朴实组合途径. 因而, 依然需求PAD-to-PAD constraint操控这些途径的时延.
10. 怎样在ISE 中看到PAD TO PAD 的布线状况?
答:一般不用介意信号在FPGA内的道路, 只需它涉及到时序问题. 这种东西将对以优化的办法对规划进行路由. 假设期望查看具体路由, 能够运用Xilinx FPGA Editor, 它包含在ISE4. 2i软件中.
11. 在Xilinx Foundation 3. 1i下用JTAG PROGRAMER下载程序到芯片中, 但是总是呈现如下过错:If the security flag is turned on in the bitstream, programming status can not be confirmed;others, programming terminated due to error. 丈量电路信号, 没有相应的波形, 明显下载没有成功. 所用的芯片是:Xilinx Spartan2 XC2S50TQ144. 怎样处理?
答:This is a security feature. By disabling readback, the configuration data cannot be read back from the FPGA. This prevents others from pirating your intellectual properties. You can enable or disable this feature during bitstream generation.
The proper way to determine if the configuration is finished without error is to check the status of the DONE pin on the FPGA. DONE pin should goes high if the bitstream is received correctly. Also, since you are using JTAG configuration, please make sure you have selected JTAG clock (not CClk) as your Startup clock during bitstream generation. (参阅译文:这是保密功用. 经过禁用回读, 装备数据不能从FPGA回读. 这能够避免其他人盗用你的效果. 在生成位元流进程中, 能够启用或禁用这个功用.
确认装备是否准确无误地完结, 合适的办法便是查看FPGA上DONE引脚的状况. 假设正确地接收了位元流, 则DONE引脚将会升高. 并且, 已然运用JFAG装备, 就要确保在生成位元流进程中, 现已将JGAG时钟(而不是CClk)选作了Startup时钟. )
12. Xilinx Virtex架构中每个对照表(LUT)都能够设置成为具有可编程深度(最多为16)的移位存放器. 可否理解为, 在写规划的时分假设规划了一个深度不大于16位的移位存放器, ISE归纳时就会用一个LUT来代替它?
答:Most synthesis tools (e. g. Synplify Pro, Xilinx XST) are able to infer LUT based shift register (SRL16E) from your source code. Even for depth greater than 16, the tool is smart enough to infer multiple SRL16E to realize the shift register. Another way to utilize this feature is to instantiate an SRL16E in the source code. You can refer to the Library Guide in the Xilinx ISE software package for more details. (参阅译文:大大都归纳东西, 例如Synplify Pro和Xilinx XST, 都能依据源代码中的移位存放器SRL16E来揣度 LUT. 即使是深度大于16的状况, 此类东西也能够揣度出多SRL16E, 然后完结移位存放器. 运用此功用的另一种途径是在原代码中例示一个SRL16E. 具体阐明能够参阅Xilinx ISE软件包中的库攻略. )
13. LUT是完结组合逻辑的SRAM, 怎样完结一个时序的移位存放器, 是不是有必要加一个触发器来合作LUT?
答:The LUTs in Xilinx Virtex architecture are not simply combinational logic. When it is configured as 16×1 RAM, the write operation is synchronous. When it is configured as shift register, there is no need to consume any flip-flop resource. In fact the internal circuitry of a Virtex LUT is more complicated than what it looks like. (参阅译文:Xilinx Virtex结构中的LUT不是简略的组合逻辑。当它被装备为16×1 RAM时,写操作是同步的。当它被装备为移位存放器时,则无需耗费任何flip-flop资源。事实上Virtex LUT的内部电路比看起来更杂乱。)
14. 在foundation 3.1环境里怎样找不到发动testbench.vhd的程式?
答:随同Foundation 3.1i呈现的仿真器为门极仿真器, 因而你不能在这种规划环境下以VHDL级运转仿真. vhdl代码有必要在你运转任何仿真之前进行归纳. 因而, 在Foundation 3.1i环境下并不能运用vhdl testbench. 作为代替办法, 你能够编写仿真script.
实际上, Foundation 3.1i是一款相对较老的软件. Xilinx ISE软件中支撑HDL testbench, 它的最新版别为4.2i.
15. 关于双向口的仿真, 假设双向口用作输进口, 输出口该怎样设置?
答:做仿真时, 软件会自动地将IO口(包含双向口)的引脚本参加到. SCF文件中去. 先新建一个SCF文件, 然后在NODE->ENTER NODES FROM SNF->LIST, 将列出的一切IO引脚(包含了双向口)都参加仿真文件中, 就能够进行仿真了.
16. 关于ACEX1K的I/O脚驱动才能. ALTERA 核算功耗的datasheet 中:对ACEX1K器材, PDCOUT (power of steady-state outputs)的核算便是依据IOH, IOL来核算的, 能否告诉我ACEX1K芯片的IOH, IOL别离是多少?
答:关于ACEX1K的IO驱动才能, IOHIOL的巨细能够从ACEX1K的数据手册中查到(ACEX. PDF PAGE 50/86).
17. 规划中Vccio=3. 3V, 假设IOH=20mA, IOL=20mA, n=10 (Total number of DC output with steady-state outputs), 怎样核算PDCOUT?
答:关于功耗的核算能够参照AN74(P2)中的功耗核算公式.
18. 当Vccio=3. 3V时, 关于输入脚, 它兼容TTL, CMOS电平;对输出脚, 它是否也兼容TTL和CMOS电平?对CMOS电平, 是否需求用OpenDrain 加上下拉电阻来完结?
答:ACEX1K器材引脚兼容TTL与CMOS电平. COMS输出是否要加上拉电阻要看外部接的CMOS电平, 假设说接5V COMS则需求上拉. 具体状况能够参照AN117.
19. 将EPC2与EPF10K30A衔接成JTAG菊花链的方法, 在调试阶段能够越过EPC2直接装备EPF10K30A, 而在装备经过验证今后再运用EPC2的JTAG口将EPF10K30A的装备信息固化到EPC2中去. EPC2的专用装备端与EPF10K30A装备端衔接, 当体系脱离JTAG电缆上电装备时, 由EPC2完结对EPF10K30A的装备. 这个进程中有一个疑问, EPF10K30A相当于有两个装备通道(一个经过JTAG, 一个经过EPC2), 当其间一个装备通道作业时, 别的一个装备通道的存在是否会影响到装备进程的正常进行呢?假设相互影响, 怎样才能做到两种办法一起存在又互不影响呢?
答:能够使10K30A具有两个不同的下载办法, 在板子上做一个跳线开关即可. 也能够从当地的署理得到该模块的参阅规划.
20. ALTERA是主张直接运用MAXPLUSII或QUARTUS编译HDL源代码, 仍是运用第三方EDA东西(如SYNPLIFY、LeoanrdoSpectrum或SYNOPSYS)先把HDL源代码编译为edf文件后再运用ALTERA的东西编译?
答:ALTERA主张用第三方的东西将HDL源代码编译为edf文件后再运用ALTERA的东西进行布局布线. ALTERA的MAXPLUSII和QUARTUS也都自带有HDL的归纳器, 一些简略的规划能够直接在MP2或QII中编译即可. 并且能够直接在软件中后台调用第三方的EDA东西.
21. 用MAXPLUSII或QUARTUS屡次编译同一规划生成的带延时的网表文件中的延时是否相同?
答:用MP2或QII屡次编译同一规划成的带延时的网表文件中的延时是相同, 但要确保该网表文件没有修改正.
22. 在编译前设定一个模块的Synthesis Style为FAST是否必定比不设定(NONE)要节约LC资源?
答:在布局布线的进程中, Synthesis Style的设置会影响到资源的运用率和速度的快慢, 一般状况下:设置为FAST首要是为了进步规划的速度. 在软件中除了归纳类型的设置, 还有一项是挑选优化的意图:oPTIMIZE->AREA OR SPEED. 挑选AREA能够节约规划所占用的资源.
23. Altera公司对芯片热规划有哪些材料和东西?
答:ALTERA供给了许多核算功耗的材料和东西. 数据手册中的AN74便是关与核算ALTERA器材功耗的专门文档.
24. 怎样在规划前期剖析芯片的功耗?
核算功耗的东西: ALTERA供给的QUARTUS软件就有核算功耗的功用, 它能够依据你不同的鼓励项量来核算功耗; 在ALTERA 的网叶上就有专门核算功耗的运算器, 请点击