有许多要素会影响器材的成效,成效能够用电池两次充电之间可用小时数来衡量。在现在这个高清移动屏年代,电池消耗最大的主要要素有两个——显现器亮度和视频与图形子体系的功耗。在这篇文章中,咱们将评论后者——体系级芯片中的智能视频和显现流水线(Display Pipeline)。智能,意味着供给与竞争性解决方案相似的功用,但要求低得多的功耗。
视频与图形子体系面对的应战
现代图形SoC要求以高帧速率烘托高分辨率图画,而且在此根底之上履行多个图画后处理使命,如缩放、旋转、像素格局转化等等。应对这种应战的典型办法是选用图形处理单元(GPU),但是,由于其通用性架构,在详细显现处理操作期间的成效并不是最优的。
针对这种状况,Evatronix公司开发出了PANTA DP IP内核——系列显现处理器,旨在从GPU接收这些特别显现使命,从而明显下降功耗。PANTA处理器专门针对一些履行使命进行了优化,如多层组合、YUVRGB转化、旋转、阿尔法混合、伽玛校对以及在将帧缓冲内容提交给显现器之前的其它使命。这样能够通过部分或悉数卸载GPU使命而明显下降总的SoC动态功耗。由于通过削减对视频和图形帧缓冲器的拜访次数而保留了最小的体系内存带宽,因而能够进一步下降PANTA DP辅佐SoC的功耗。
增强现有架构
咱们以一个处理多个显现器输出的GPU处理显现流水线为例。该体系要在两个具有不同分辨率的屏幕上显现图形帧——外部全高清(1920×1080像素)和本地高清(1280×720像素)显现器。每个帧由3个层组成。第一层是由曾经设备相机记载的通过译码的全高清视频。这个帧以YUV 4:2:0格局存储在帧缓冲器内。别的两层是音量控制和记载速率,由GPU以RGB格局发生。在组合层能够被显现之前有必要履行许多操作,包含YUV到RGB视频层转化、三帧阿尔法混合、缩放和旋转。在如图1所示的体系中,显现控制器只需传送帧缓冲器中由GPU准备好的终究数据。
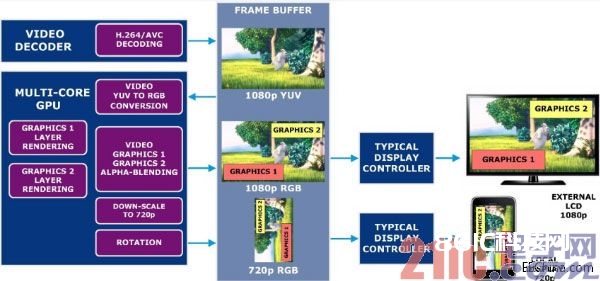
图1:典型的多显现器体系。
在这个事例中,能量被GPU中履行的特别显现使命浪费了,而GPU专门针对履行不同图形运算操作——本例中是2D图形烘托进行过优化。
为了进步能效,能够运用PANTA系列元件。图2显现了一个图形子体系架构比如,其间运用了两个装备有PANTA CP20缩放协处理器的PANTA DP30显现处理器。在这个比如中,GPU只担任烘托图形层像素,并将成果发送到帧缓冲器。因而GPU使命量得到了很大程度地卸载,由于YUV到RGB转化、阿尔法混合、缩放和旋转交给了PANTA DP30和PANTA CP20单元来完结。

图2:选用PANTA元件的多显现器子体系。
在这个体系中,由PANTA DP30转化到RGB格局的视频层会与其它图形层组合在一起,并在外部屏幕上直接显现。与此同时,组合帧被PANTA CP20模块从1080p缩小到720p,并返回到帧缓冲器。第2个PANTA显现处理器取回缩小后的帧并旋转90度,然后将它发送给本地显现器。由于PANTA IP的缩放和旋转功用,这两个额定操作不需要在GPU中履行,因而图形子体系中的整体功耗会有明显下降。别的,由于帧缓冲器中存储的图形数据巨细取决于帧分辨率和格局,因而与图1所示的典型多显现器解决方案比较,PANTA元件的运用能够将体系内存带宽最多削减40%。在这个用例中描绘并用40nm LP工艺完成的PANTA元件总功耗不到30mW。
PANTA显现处理器还能下降更多的功耗。在有些状况下,一切视频和图形处理使命都能够由PANTA元件履行,因而答应彻底封闭GPU。图3显现了一种用例,其间PANTA IP显现由视频译码器传送至帧缓冲器的译码视频。这样的数据流只要求旋转以及YUV至RGB转化,因而彻底不需要GPU参加。在这种状况下,选用40nm LP工艺完成的PANTA DP30功耗不会超越6mW。
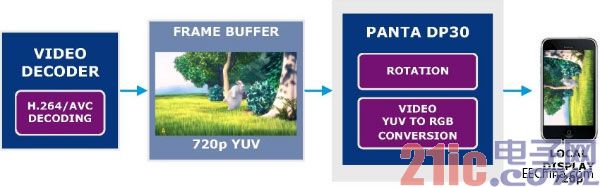
图3:没有GPU的PANTA DP辅佐显现子体系。
小结
由于三维游戏和高清视频回放正在成为移动设备的基本功用,因而上述视频流水线在SoC等级得到功耗最优化非常重要。用户希望智能手机和平板电脑能够供给超长电池寿数,在多媒体使用期间也不破例。
Evatronix PANTA处理器能够在不献身任何功用的前提下协助用户进步显现子体系的成效,这要归功于替代GPU履行特别显现使命、最大极限削减视频/图形子体系内存带宽的内部IP。